Introduction:
NLTK (Natural Language Toolkit) is a popular Python library for natural language processing (NLP). It provides us various text processing libraries with a lot of test datasets. A variety of tasks can be performed using NLTK such as tokenizing, parse tree visualization, etc… In this article, we will go through how we can set up NLTK in our system and use them for performing various NLP tasks during the text processing step.
This article was published as a part of the Data Science Blogathon

Source:https://www.hackerearth.com/blog/developers/natural-language-processing-components-and-implementations/
Text Processing steps discussed in this article:
- Tokenization
- Lower case conversion
- Stop Words removal
- Stemming
- Lemmatization
- Parse tree or Syntax Tree generation
- POS Tagging
Installing NLTK:
Use the pip install method to install NLTK in your system:
pip install nltk
To understand the basics of NLP follow this link:
Downloading the datasets:
This is optional, but if you feel that you need those datasets before starting to work on the problem.
import nltk nltk.download()
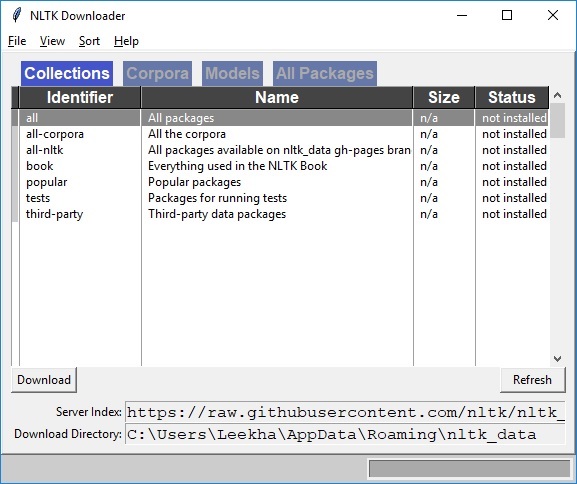
Source: https://thinkinfi.com/how-to-download-nltk-corpus-manually/
You can see this screen and install the required corpus. Once you have completed this step let’s dive deep into the different operations using NLTK.
Tokenization:
The breaking down of text into smaller units is called tokens. tokens are a small part of that text. If we have a sentence, the idea is to separate each word and build a vocabulary such that we can represent all words uniquely in a list. Numbers, words, etc.. all fall under tokens.
Lower case conversion:
We want our model to not get confused by seeing the same word with different cases like one starting with capital and one without and interpret both differently. So we convert all words into the lower case to avoid redundancy in the token list.
text = re.sub(r"[^a-zA-Z0-9]", " ", text.lower()) words = text.split() print(words)
# output -> ['natural', 'language', 'processing', 'is', 'an', 'exciting', 'area', 'huge', 'budget', 'have', 'been', 'allocated', 'for', 'this']
Stop Words removal:
When we use the features from a text to model, we will encounter a lot of noise. These are the stop words like the, he, her, etc… which don’t help us and, just be removed before processing for cleaner processing inside the model. With NLTK we can see all the stop words available in the English language.
from nltk.corpus import stopwords
print(stopwords.words("english"))
# output->
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
# Remove stop words
words = [w for w in words if w not in stopwords.words(“english”)]
print(words)
# output -> [‘natural’, ‘language’, ‘processing’, ‘exciting’, ‘area’, ‘huge’, ‘budget’, ‘allocated’]
Stemming:
In our text we may find many words like playing, played, playfully, etc… which have a root word, play all of these convey the same meaning. So we can just extract the root word and remove the rest. Here the root word formed is called ‘stem’ and it is not necessarily that stem needs to exist and have a meaning. Just by committing the suffix and prefix, we generate the stems.
NLTK provides us with PorterStemmer LancasterStemmer and SnowballStemmer packages.
from nltk.stem.porter import PorterStemmer # Reduce words to their stems stemmed = [PorterStemmer().stem(w) for w in words] print(stemmed)
# output -> ['natur', 'languag', 'process', 'excit', 'area', 'huge', 'budget', 'alloc']
Lemmatization:
We want to extract the base form of the word here. The word extracted here is called Lemma and it is available in the dictionary. We have the WordNet corpus and the lemma generated will be available in this corpus. NLTK provides us with the WordNet Lemmatizer that makes use of the WordNet Database to lookup lemmas of words.
from nltk.stem.wordnet import WordNetLemmatizer # Reduce words to their root form lemmed = [WordNetLemmatizer().lemmatize(w) for w in words] print(lemmed)
#output -> ['natural', 'language', 'processing', 'exciting', 'area', 'huge', 'budget', 'allocated']
Stemming is much faster than lemmatization as it doesn’t need to lookup in the dictionary and just follows the algorithm to generate the root words.
Parse tree or Syntax Tree generation :
We can define grammar and then use NLTK RegexpParser to extract all parts of speech from the sentence and draw functions to visualize it.
# Import required libraries
import nltk
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from nltk import pos_tag, word_tokenize, RegexpParser
# Example text
sample_text = "The quick brown fox jumps over the lazy dog"
# Find all parts of speech in above sentence
tagged = pos_tag(word_tokenize(sample_text))
#Extract all parts of speech from any text
chunker = RegexpParser("""
NP: {?*} #To extract Noun Phrases
P: {} #To extract Prepositions
V: {} #To extract Verbs
PP: {
} #To extract Prepositional Phrases
VP: { *} #To extract Verb Phrases
""")
# Print all parts of speech in above sentenceoutput = chunker.parse(tagged)
print(“After Extractingn”, output)

output.draw()
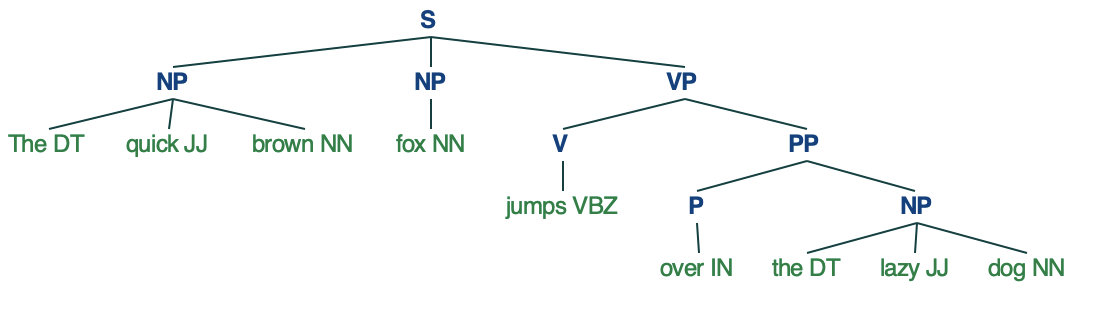
Source: https://www.geeksforgeeks.org/syntax-tree-natural-language-processing/
POS Tagging:
Part of Speech tagging is used in text processing to avoid confusion between two same words that have different meanings. With respect to the definition and context, we give each word a particular tag and process them. Two Steps are used here:
- Tokenize text (word_tokenize).
- Apply the pos_tag from NLTK to the above step.
import nltk
from nltk.corpus import stopwords
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
from nltk.tokenize import word_tokenize, sent_tokenize
stop_words = set(stopwords.words('english'))
txt = "Natural language processing is an exciting area."
" Huge budget have been allocated for this."
# sent_tokenize is one of instances of
# PunktSentenceTokenizer from the nltk.tokenize.punkt module
tokenized = sent_tokenize(txt)
for i in tokenized:
# Word tokenizers is used to find the words
# and punctuation in a string
wordsList = nltk.word_tokenize(i)
# removing stop words from wordList
wordsList = [w for w in wordsList if not w in stop_words]
# Using a Tagger. Which is part-of-speech
# tagger or POS-tagger.
tagged = nltk.pos_tag(wordsList)
print(tagged)
# output -> [('Natural', 'JJ'), ('language', 'NN'), ('processing', 'NN'), ('exciting', 'JJ'), ('area', 'NN'), ('.', '.')] [('Huge', 'NNP'), ('budget', 'NN'), ('allocated', 'VBD'), ('.', '.')]References:
- https://www.guru99.com/pos-tagging-chunking-nltk.html
- https://www.geeksforgeeks.org/part-speech-tagging-stop-words-using-nltk-python/#
- https://www.tutorialspoint.com/natural_language_processing/natural_language_processing_python.htm
- https://thinkinfi.com/how-to-download-nltk-corpus-manually/
- Image: https://quicksilvertranslate.com/14115/natural-language-processing/
Conclusion:
NLTK is a strong base for anyone initialized with Natural Language Processing. You have prepared the basic techniques like tokenization, stopword removals, stemming and lemmatizations – which will be added as one of core skills in achieving higher level NLP tasks. While we have gone through fundamental text preprocessing, bare in mind that NLP is broad and always changing.

Source:https://medium.com/datatobiz/the-past-present-and-the-future-of-natural-language-processing-9f207821cbf6
About Me: I am a Research Student interested in the field of Deep Learning and Natural Language Processing and currently pursuing post-graduation in Artificial Intelligence.
Feel free to connect with me on:
1. Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
2. Github: https://github.com/Siddharth1698
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Passionate about artificial intelligence, I am dedicated to advancing research in Generative AI and Large Language Models (LLMs). My work focuses on exploring innovative solutions and pushing the boundaries of what's possible in this dynamic and transformative field.






