This article was published as a part of the Data Science Blogathon
Introduction:

Source: https://www.asksid.ai/blog/what-is-natural-language-processing/
Language is very important when we want to communicate with each other. Every human can talk and tell others what they need and listen with language. These languages can be anything like English, Spanish, Hindi, Malayalam, etc… We can express our ideas to others in this medium. Language is one of the critical components of human intelligence.
Every day we interact with humans, but how about non-human? We daily use our mobile phones, computers, cars, etc… How do these machines understand what we want to express with them? This is where we use “Natural Language Processing”. Machines cannot understand our natural language and hence it is much required to process the language in such a way it can understand and the vice-versa is also true.
We have currently made a huge breakthrough in the field of NLP. But still, it’s a long journey ahead and huge research is involved across the globe. So, in this article, I will guide you through the fundamental understanding of NLP and how you can build a foundation in this field.
Structured Languages and the challenging part:
One beauty of human language is its nature of not being structured. This makes the idea of processing the language very difficult and is one of the hardest parts of NLP. Let us talk about some structured language. If we take the case of mathematics, we have equations say,
y = 3x+2
Here, it is directly conveying the fact that a point x is multiplied by a constant 3 and when added with 2 gives us y. and as we change x, our y keeps changing accordingly.
Programming languages, SQL Queries, and Scripting are other sets of structured language which we use. These languages are designed in such a way they are non-ambiguous in nature and can be processed easily. These are expressed by some rules or Grammars. These grammars are well defined and can be used while processing a language.
When we talk, mostly we try to use some languages and they may be structured. But mostly, unstructured. We don’t have many difficulties when we use ambiguities in our language while speaking and the unstructured nature isn’t difficult for us to process. This isn’t the case with machines and they can’t process the data as we do. In upcoming sections, we will discuss various things machines can do to process language.
The issue is with Context:
The main part for machines is to understand the context of the speech or text. To understand this let’s take this example of this meme :

Source: https://makeameme.org/meme/ha-ha-so-ofn1yj
Here, the sentence starts with haha, so funny and all and the machine might think it is a positive sentiment. But, in reality, we bring out sarcasm here and it means the joke was bad. Computers will make mistakes when they analyze this.
Take the case of these two sentences:
1. The table didn’t fit through the window as it was too wide.
2. The table didn’t fit through the window as it was too thin.
In the first sentence, we can say it refers to the table while in the second it refers to the window. But how does our computer understand them? This is challenging. How did we know where it belongs but the machine cant. It’s the way we see things. We may have experienced it, We know it by imagination.
How can we build NLP Pipeline?

Source: https://unsplash.com/photos/XYeCKHcZNz8
Building an NLP pipeline includes starting with raw texts and analyzing them, processing them by extracting relevant words and meaning, understanding the context to an extent which is the feature extraction, and building a model that can express the intention of doing something from the sentence. While building a pipeline the workflow may not be linear.
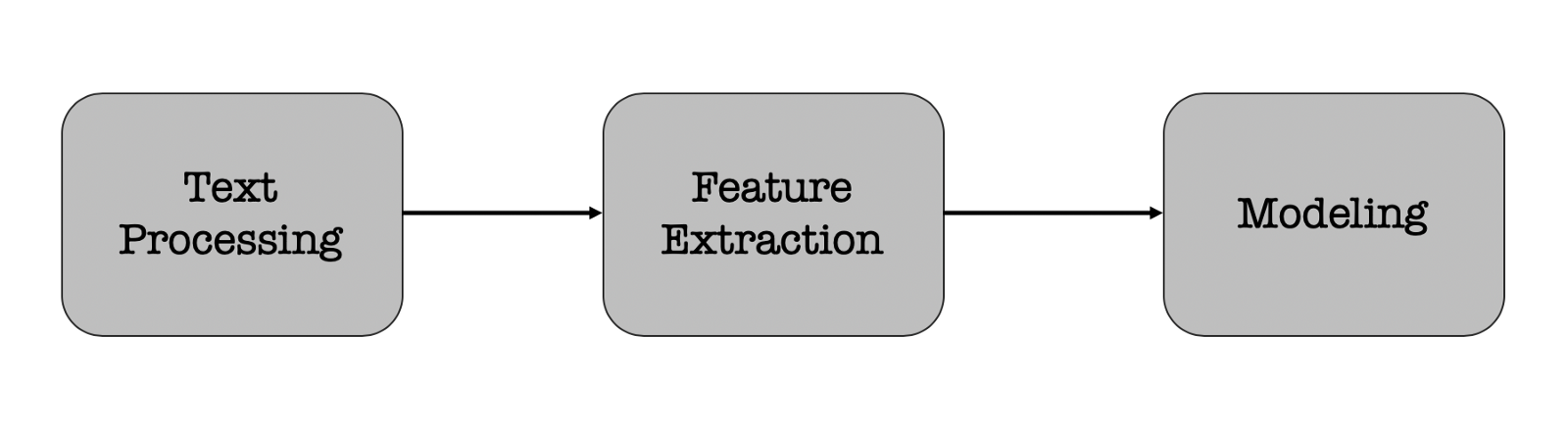
Source: https://medium.com/analytics-vidhya/understanding-nlp-pipeline-9af8cba78a56
Text Processing:
We would always think why do we need to process text? Why not directly provide the text? So, we will see where does this text come from before processing them. Most text may be available on web pages like Wikipedia, or maybe some sentence spoken by someone in a movie or even a speech given by our favorite motivational speaker. In the case of web pages, we have the text which is embedded inside HTML tags and we must retain only important text before extracting relevant features from them. There may be URLs, symbols, etc.. which may not make any sense for what we do and need to be removed.

Source: https://www.siriuscom.com/solutions/application-development/
The above image tells us about various sources from which we may have the text and why we must process them before extracting relevant features. Sometimes we might have to do basic operations like changing all words into lowercase as it will help reduce taking the same words more than one time. We may need to omit punctuation marks or stop works like ‘the’, ‘for’, as it may not be relevant for our problem and may repeat a lot of time and thus will reduce the complexity of the procedures we follow.
Feature Extraction:
Now that we have processed the text and we got relevant data can we directly build the mode? Not quite. This is because computers are machines that process data in a special encoding like binary. It cannot understand the English we speak. Computers don’t have any standard representation for words. These are internally a sequence of ASCII or Unicode values, but don’t capture meaning or context. So, building a good model may require proper features being extracted from processed data. This completely depends on what task we want to accomplish. We represent words in different forms like maybe graphical networks like for WordNet. Maybe like encoded form for Word2Vec, a bag of words, etc…
We can use an encoding to give probability to particular words such that they are represented in an array form. We use vectors in text generation and machine translation. These can be seen in word2vec or glove representations. There are many ways of representing such text pieces of information.
Modelling:
In this stage, we build a model such a machine learning or deep learning based on our requirements. We use the data we have and train them in our model. These trained data are used such that it gives the model experience and the model is said to learn from these experiences. In the future when new unseen data arrives the model can predict the outcome like say predict a word or predict a sentiment, etc…
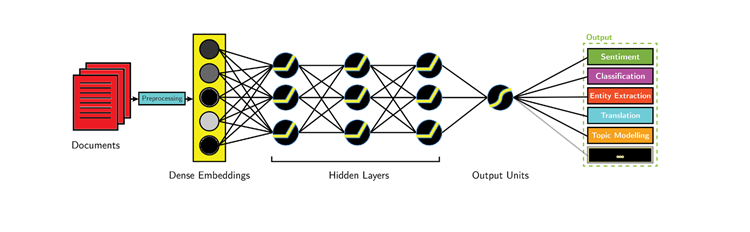
Source:https://software.intel.com/content/www/us/en/develop/articles/deep-learning-for-natural-language-processing.html
We work with numerical features here and that helps us work with any machine learning models. These models are used in our applications like websites, mobile apps as the backend to help make decisions for our business of products. Some of the latest language models that use deep learning includes Transformers, BERT, GPT, XLNet, etc…
References:
1. https://www.udacity.com/course/natural-language-processing-nanodegree–nd892
2. Image: https://aliz.ai/natural-language-processing-a-short-introduction-to-get-you-started/
Conclusion:

Source: https://www.scientific-editing.info/blog/writing-a-sound-conclusion-for-your-paper/
In this article, we saw an eagle’s view on NLP and what it is all about. This gives you a basic idea if you are a beginner and help you realize why NLP is such an exciting topic and a huge opportunity in research. Feel free to contact me for more details on NLP.
About Me: I am a Research Student interested in the field of Deep Learning and Natural Language Processing and currently pursuing post-graduation in Artificial Intelligence.
Feel free to connect with me on:
1. Linkedin: https://www.linkedin.com/in/siddharth-m-426a9614a/
2. Github: https://github.com/Siddharth1698
Passionate about artificial intelligence, I am dedicated to advancing research in Generative AI and Large Language Models (LLMs). My work focuses on exploring innovative solutions and pushing the boundaries of what's possible in this dynamic and transformative field.






