This article was published as a part of the Data Science Blogathon.
Introduction
News apps are one of the most downloaded apps and also they have huge traffic. Everyone is interested in knowing about the things happening in the world. But they may not have the time to go through those lengthy news articles and they may like to know the crux of the article without missing details. The latest developments in the field of artificial intelligence have made such a thing reality. Today people can read a summary of an entire news article in just two or three lines and understand all the details about the article.
Text Summarization is one such task in Natural Language Processing that can enable us to build such short news summaries. There are many famous apps like Inshorts that leverage Artificial Intelligence to deliver short news articles in their app.
In this article, we shall see how to build such an app using Streamlit and HuggingFace transformers and we will also deploy that app on stream cloud. To fetch news into our app we will use Free News API by Newscatcher.
Overview
- Free News API
- Newspaper3k
- HuggingFace Transformers
- Streamlit
- Application setup
- Building our Application
- Testing
- Deploying
- Conclusion
Free News API
Free News API is provided by Newscatcher. It helps us fetch live news based on several input parameters. Unlike many news APIs that are available on the internet, it is free to use. It aggregates news from over 60,000 news websites with up to 15,00,000 news articles daily. The basic version of this API has limited ability. We can not fetch news based on country or given category. But we can make unlimited API calls to fetch news. In this project, we will use the basic version as it is free.
Newspaper3k for extracting News Articles
Newspaper3k is a python library for extracting and curating news articles from the internet. It’s a very useful library to deal with news article links and also extract all the metadata of a news article. In this project, we will use this library to get the news article.

HuggingFace Transformers for Summarizing News Articles
We will use the transformers library of HuggingFace. This library provides a lot of use cases like sentiment analysis, text summarization, text generation, question & answer based on context, speech recognition, etc.
We will utilize the text summarization ability of this transformer library to summarize news articles.
Streamlit for deploying the News App
Streamlit is an open-source python library for building Data science and machine learning apps fastly. We can use this to prototype our data science apps quickly. Streamlit is also very easy to learn. It is good to have this skill to test our app before we take it to production. We can also build an analytics dashboard using this library. Streamlit also offers cloud services where we can deploy our apps. In this project, we will deploy our app on the Streamlit cloud.
Application Setup
Our application works as per the process shown in the below figure

In other words,
- Get news from the internet using Free News API
- Extract the news link and send it to the newspaper3k library to download the news article
- Pass the resulting article through the transformers pipeline to get the summarized version of the article.
- Finally, display the News title and summarized article to the user in a streamlit UI
Let’s start building our app!!
Building our News Application for Discord
First, let’s install all necessary libraries
pip install streamlit
pip install transformers
pip install json
pip install requets
pip install newspaper3k
Now we import all the installed libraries as follows
import streamlit as st from transformers import pipeline import json import requests from newspaper import Article
Before we code our app we need to get an API to fetch news links based on our search from the internet. As discussed earlier we will be using Free news API to get that link. So for this, we get an API from this link. Follow the steps given in the link to get the API. If you have doubts please comment below so that I can clear your doubts.
Now that we have installed and imported all necessary libraries and also got our API key, we code our Streamlit app in the following way. The final code looks like below –
import streamlit as st
import json
import requests
from newspaper import Article
from transformers import pipeline
st.set_page_config(page_title='Short News App', layout='wide', initial_sidebar_state = 'expanded')
st.title('Welcome to Short News App n Tired of reading long articles? This app summarizes news articles for you and gives you short crispy to the point news based on your search n (This is a demo app and hence is deployed on a platform with limited computational resources. Hence the number of articles this app can fetch is limited to 5)')
summarizer = pipeline("summarization")
article_titles = []
article_texts = []
article_summaries = []
def run():
with st.sidebar.form(key='form1'):
search = st.text_input('Search your favorite topic:')
submitted = st.form_submit_button("Submit")
if submitted:
try:
url = "https://free-news.p.rapidapi.com/v1/search"
querystring = {"q":search, "lang":"en", "page":1, "page_size":5}
headers = {'x-rapidapi-host':"free-news.p.rapidapi.com", 'x-rapidapi-key':"your_api_key"}
response = requests.request("GET", url, headers=headers, params = querystring)
response_dict = json.loads(response.text)
links = [response_dict['articles'][i]['link'] for i in range(len(response_dict['articles']))]
for link in links:
news_article = Article(link, language = 'en')
news_article.download()
news_article.parse()
article_titles.append(news_article.title)
article_texts.append(news_article.text)
for text in article_texts:
article_summaries.append(summarizer(text)[0]['summary_text'])
except:
print("Try with new search")
for i in range(len(article_texts)):
st.header(article_titles[i])
st.subheader('Summary of Article')
st.markdown(article_summaries[i])
with st.expander('Full Article'):
st.markdown(article_texts[i])
if __name__=='__main__':
run()
Explanation of the above code
- First, we import all necessary libraries.
- Then we set the page configuration of our app using st.set_page_config(). We give all parameters as shown in the above code.
- Next, we give a title of our app using st. title() as shown in the code. You can give your title and explanation as shown in the above code.
- Now we define three empty lists to store our article titles, article texts, and their corresponding summaries for final display. Next, we create a sidebar in our app for searching the desired topic. We create this search form using st.sidebar().form() of Streamlit as shown in the above code and also we create a submit button using st.form_submit_button().
- So now if the user enters a search term and clicks submit button we have to fetch news articles and display their summaries. We do that as follows –
- First, we get our API URL.
- We give our query parameters like search term, language, number of pages, and number of articles per page.
- Create headers for API as shown code.
- Using requests library we fetch data from the internet using our query parameters and headers.
- We convert the request object from the above step into a dictionary using JSON.
- Next, we extract the links from the dictionary metadata we obtained from the internet using requests.
- For each link we have, we use the newpaper3k library to get the article title and article text and append them into the corresponding empty lists we defined earlier.
- Now that we have article titles, article texts we get our summaries for each article using transformers summarization pipeline as shown in the above code.
- Now we have article titles, article texts, and their corresponding summaries. So we display the article using st.header() and we display the summary of the article using st.markdown(). Before that we create a heading ‘Summary of Article’ and then we display the news summary under this.
- Finally, if the user wants to read the full article, we also give an option to look at the full article using st.expander(). This expander widget of streamlit hides the content in it and displays the content only when the user clicks to expand.
Testing
We built our app. Save the code in a .py file and open the terminal.
Type streamlit run your_app_name.py in the terminal and press enter.
You will see a new tab in your browser with your app.
Deploying
We built and tested our app. It’s time to deploy it. We will deploy this on Streamlit cloud. Streamlit offers to host three apps for free on its cloud.
Go to this link of Streamlit sharing and create an account if you don’t have one already. After you create an account and sign in you will see a web page with the option ‘New App’. Click on it.
It will ask you to connect to a Github repository. So create a Github repository of your app and upload the .py file we just created. We also need a requirements.txt. So create a file with the name ‘requirements.txt’ and type the following in that file,
streamlit transformers tensorflow requests newspaper3k
save the file and commit changes to your repository. Now come to the Streamlit sharing website and connect your newly created Github repository and click deploy. Streamlit does the rest of the work for us and deploys our app.
Finally, our app will look like this –
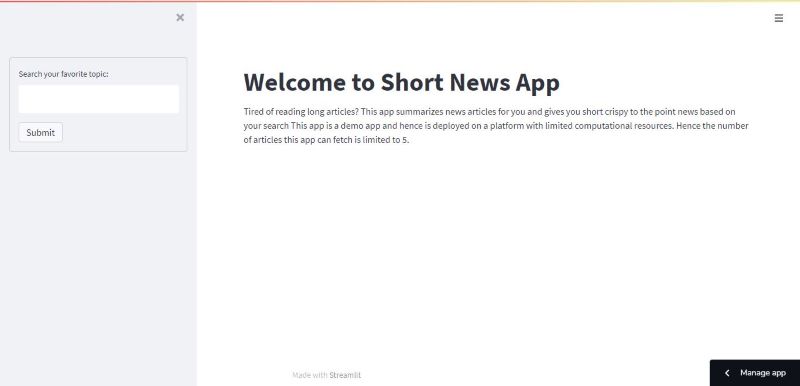
You can search the news for your favorite celebrity and get a summarized version of each article.
Try this app I created here Short News App · Streamlit
Conclusion
We successfully built our short news app leveraging AI capabilities. AI has made our life simple. More features can be added to this app. Try it.
Read my other articles here –
- Live Twitter Sentiment Analyzer with Streamlit, Tweepy and Huggingface (analyticsvidhya.com)
- NeatText Library | Pre-processing textual data with NeatText library (analyticsvidhya.com)
Image sources:
Image-1: https://newspaper.readthedocs.io/en/latest/
Image-2: https://huggingface.co/






