Introduction
There are many projects all over the internet talking about Twitter sentiment analysis. All these projects talk about finding the sentiment of tweets that are scrapped already. The datasets that these projects use are structured datasets scrapped for a specific purpose.
But, what if you want to find the live sentiment of tweeples(people who tweet are called as tweeples) on some celebrity or any event like, say, COVID at this moment?
In this article, we shall see how to build such a live Twitter sentiment analyzer using Tweepy, HuggingFace Transformers, and Streamlit. We shall also deploy that app using streamlit sharing and see the live sentiments on any celebrity.
Overview
- Tweepy
- HuggingFace Transformers
- Streamlit
- Application Setup
- Building our Application
- Testing
- Deploying
- Conclusion
Before we get our hands dirty let’s, briefly, see some details about different libraries that we are going to use in our app.
Tweepy
Tweepy is an open-source python package to access the Twitter API. Using this package, we can retrieve tweets of users, retweets, status, followers, etc. We can also use this package to create Twitter bots that can post on our behalf. We can stream the tweets of users and check their live status. We can do a lot of things with Tweepy. You can go through the documentation to know the full functionality of this python package.
In our project, we will use this package to get live tweets based on a given search string.
HuggingFace Transformers
HuggingFace is a company that intends to democratize Artificial Intelligence through open source. It contains all Natural Language Processing tools that can be used for sentiment analysis, text generation, question-answer based on context. It has a hub of models from which we can choose a model based on our application. Recently it has added a new feature called Spaces to host our apps built with Streamlit and Gradio.

Besides that, it also offers a python library called transformers. We will use this library in our project.
Streamlit
Streamlit is an open-source python package to build Machine Learning web apps in very little time. It is very easy to learn. It is best for prototyping machine learning models. We can also build visualization apps, dashboards using this tool. It also offers a way to deploy our apps on its servers through ‘Streamlit sharing’. We can also deploy our Streamlit apps on GCP, AWS, Heroku, or any platform of our choice.
Live Twitter Sentiment Analyzer Setup
Our objective is to find the sentiment of live tweets on a particular topic or person.
For this,
- We need to fetch tweets from Twitter based on our requirements.
- Find sentiments of these tweets.
- Display it to the user along with the corresponding tweets.
So as the first step we fetch tweets from Twitter using Tweepy and then use huggingface transformers to find the sentiments of those tweets and the user controls all this process through the interface we build with Streamlit to see the end result.
Let’s start building our app.
Building our Live Twitter Sentiment Analyzer
First, we install and import necessary libraries. You can skip the installation of some libraries if you already have them installed on your system.
pip install tweepy
pip install transformers
pip install streamlit
pip install pandas
Now that we have installed all the necessary libraries, open VS code or your favorite IDE and create a .py file and import the installed libraries as below
import tweepy as tw import streamlit as st import pandas as pd from transformers import pipeline
We have imported all necessary libraries
Now the first step we see in our application setup above is getting tweets from Twitter. To do that we have to access Twitter API and use it to fetch the tweets. To access Twitter API, we need API keys and API key secrets. To get them do follow the below steps
- Create a Twitter account if you don’t have one
- Apply for a developer account on Twitter
- Once you get access to your developer account, start a project and get create an app instance
- This will generate your keys. Get ‘consumer key’, ‘consumer secret’, ‘access token’, ‘access token secret’
‘consumer key’, ‘consumer secret’ are nothing but ‘API key’ and ‘API key secret’ respectively.
So if you want to build your own app you have to get your own values from Twitter.
A detailed explanation for getting these keys is explained in this youtube video. Please follow the steps given in this video. If you don’t understand the steps given in that video or if you have any doubts regarding getting these values comment below this article I will reply to clarify your doubts.
Now that we have all keys necessary to access Twitter API we use the following Tweepy code to access it
consumer_key = 'type your API key here' consumer_secret = 'type your API key secret here' access_token = 'type your Access token here' access_token_secret = 'type your Access token secret here' auth = tw.OAuthHandler(consumer_key, consumer_secret) auth.set_access_token(access_token, access_token_secret) api = tw.API(auth, wait_on_rate_limit=True)
The above code creates a connection between our app and Twitter.
Now that we established a connection between our app and Twitter, let’s define an instance of sentiment analysis using the pipeline function of hugging face transformers that we already imported.
classifier = pipeline('sentiment-analysis')
Now that we defined our instance and established a connection between our app and Twitter, let’s give a title to our app using Streamlit. I used the below name you can give your name of choice
st.title('Live Twitter Sentiment Analysis with Tweepy and HuggingFace Transformers')
st.markdown('This app uses tweepy to get tweets from twitter based on the input name/phrase. It then processes the tweets through HuggingFace transformers pipeline function for sentiment analysis. The resulting sentiments and corresponding tweets are then put in a dataframe for display which is what you see as result.')
The above code gives a title and a little description of what our app is doing.
def run():
with st.form(key=’Enter name’):
search_words = st.text_input(‘Enter the name for which you want to know the sentiment’)
number_of_tweets = st.number_input(‘Enter the number of latest tweets for which you want to know the sentiment(Maximum 50 tweets)’, 0,50,10)
submit_button = st.form_submit_button(label=’Submit’)
if submit_button:
tweets =tw.Cursor(api.search_tweets,q=search_words,lang=”en”).items(number_of_tweets)
tweet_list = [i.text for i in tweets]
p = [i for i in classifier(tweet_list)]
q=[p[i][‘label’] for i in range(len(p))]
df = pd.DataFrame(list(zip(tweet_list, q)),columns =[‘Latest ‘+str(number_of_tweets)+’ Tweets’+’ on ‘+search_words, ‘sentiment’])
st.write(df)
if __name__==’__main__’:
run()
Explanation of above code
We need to take a name or phrase as input so we use st.text_input of Streamlit to get our desired name.
Similarly, we need to know for how many tweets we want to find sentiment and display them. Since this is a demo app that’s going to be deployed on a free hosting platform we have limited computing resources. So we limit the number of tweets to retrieve. In this case, it’s just 50.
we take number input using st.number_input to get the number of tweets.
Then we give a submit using st.form_submit_button.
If the user gives a search string and the number of tweets to be retrieved for sentiment analysis and press submit button, we need to get the tweets based on that input string and perform sentiment analysis on that, and then display them as a data frame.
The if code block does this job exactly.
Variable tweets stores the tweets that we fetched using the Tweepy library based on the user inputs. But the fetched tweets are in the form of Cursor objects. So we need to get the text of those tweets.
Variable tweet_list contains the tweets in text form.
The next variable p contains all the sentiment outputs using the classifier instance we defined previously.
Variable q stores the sentiment labels(positive or negative) of the tweets. We get them as shown in the above code.
In the next line, we create a data frame containing the extracted tweets and the corresponding sentiment labels.
Using the Streamlit command st.write(), we display the final result to the user.
Press ctrl+s to save the code in the .py file
So finally we built our app.
Testing the Live Twitter Sentiment Analyzer
Testing our app is very simple. Open the terminal and type the following code
streamlit run your_app_name.py
This will open the app in your browser in a separate window and you can start giving the inputs to the app to get the live sentiments.
Deploying the Live Twitter Sentiment Analyzer
Now that we built and tested our app, it’s time to deploy our app. We will deploy it using Streamlit sharing. Streamlit provides an option to host three apps for free on its servers. To deploy an app using Streamlit sharing we must create a file named requirements.txt
create a text file with name requirements.txt and type the libraries we used in our app
tweepy streamlit pandas transformers tensorflow
Type the above in your requirements.txt file. If you observe we typed TensorFlow too. But we didn’t use it in our app. This is because streamlit needs one of the two-deep learning libraries to run transformers library. So we give that library also as a requirement.
After creating this file, create a new GitHub repository and upload the .py file we created above and also the requirements.txt file.
Go to stream share website and create an account if you don’t have one already. You can see the ‘New app’ button click it and give the GitHub repo name you just created and click deploy.
Streamlit will take care of the rest and displays your app. The end result should look like below
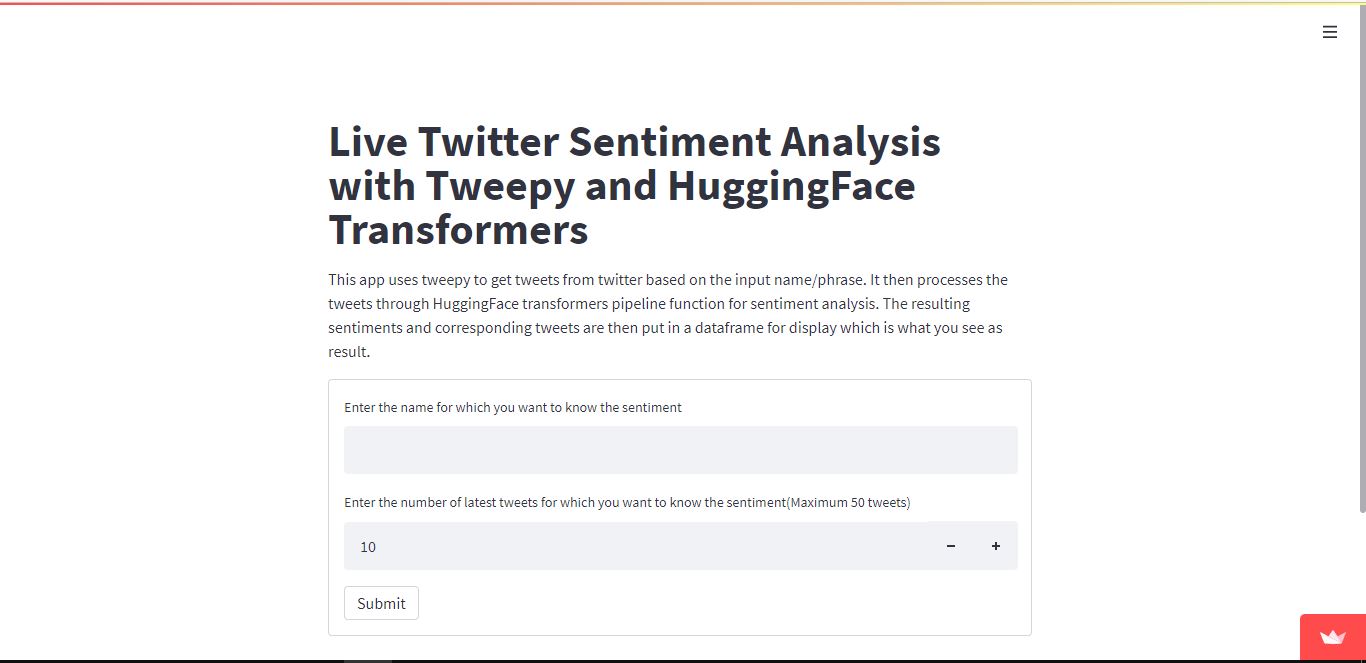
Finally, we built and deployed our app. Now you can type the name of a celebrity or any topic name like COVID etc., and also choose the number of tweets you want to find sentiment for and click submit button. You will see a table with n number of the latest tweets and their sentiment.
You can find the above app I built in this link – Streamlit. Do give it a try.
Conclusion
So we built a live Twitter sentiment analyzer in a simple way. These kinds of apps are useful to businesses to know the sentiments of their brands on social media so that they can make informed decisions or at least address the issues that their customers have. If you have any doubts regarding the above app, please comment below so that I can clarify. Thank you!!
Image Source
- image-1 : https://huggingface.co/
- image-2 : https://streamlit.io/brand





Hi, can i know how i can evaluate how well the sentiment analysis is?