This article was published as a part of the Data Science Blogathon.
Statistics plays an important role in the domain of Data Science. It is a significant step in the process of decision making, powered by Machine Learning or Deep Learning algorithms. One of the popular statistical processes is Hypothesis Testing having vast usability, not limited up to the Data Science domain only. One can find the applications of Hypothesis Testing in Healthcare, Biological, Mechanical domains. In fact, many of the biological process decisions are based on Hypothesis Testing.

In this article, we will learn about Hypothesis Testing & one of the most popular Hypothesis Test i.e. Z-test. We will also look at how to build our own Z-test Calculator in an interactive way quickly, using Python’s package Streamlit.
Table of Contents
1. What is Hypothesis?
2. How Hypothesis Testing is Performed?
3. Z – test
4. Creating Z – test Calculator
5. Conclusions
What is a Hypothesis?
A Hypothesis is a statement that is not proved or is yet to be proved. In other words, it’s an assumption that is to be tested to check if it’s true or not. The tests which are involved in testing these hypotheses are known as Hypothesis Testing, which we will see in the next section. Although there are many types of hypotheses, generally there are two types of it widely used namely Null Hypothesis, Alternate Hypothesis. These two hypotheses are completely opposite to each other. A Null Hypothesis is a statement which we believe currently is true. An Alternate Hypothesis is a statement that becomes true when the Null Hypothesis turns out to be false. Null Hypothesis is identified by H0 & Alternate Hypothesis is identified by Ha.
Statistically, it checks if a sample from a population is equal to the population, based on the population parameters such as Mean, Standard Deviation etc. For example, we know that the Mean Female height in a particular society is 168 cm & we want to test this claim if the mean height is 168 cm or not. Here, our Null Hypothesis is
H0: μ = 168
and Alternate Hypothesis is
Ha: μ ≠ 168
Now, based on the statements, the alternate hypothesis might have less than ≤, or greater than ≥ signs between the known values & Population’s Mean or Proportion. These signs also decide the tails of the test. Once we have the Null Hypothesis value, we can easily identify the Alternate Hypothesis statement & the sign to be involved.
How Hypothesis Testing is Performed?
To decide which hypothesis is to be adopted out of Null & Alternative hypotheses, we need to use the Hypothesis Test. There are several tests available that can be used to make decisions. The choice of the test depends on several parameters such as sample size, number of tails involved in the test, sample data type, Population Parameters involved, & others. Each of these tests calculates a test statistic. For example, a Z-test calculates Z-score or Z-statistic, T-test calculates T-score or T-statistic. Based on these statistical values, p-value, level of significance, we make a decision whether we are able to reject the Null Hypothesis or fail to reject the Null Hypothesis. A general process of Hypothesis testing is:
1. State the Null & Alternate Hypothesis statements
2. Specify Level of Significance (α)
3. Calculate the Test Statistic & p-value
4. Specify Critical Region
5. Conclusion – Reject or Accept Null Hypothesis
Remember that in Hypothesis Testing we test the Null Hypothesis. This means that either we will be able to Reject the Null Hypothesis or Fail to reject the Null Hypothesis. We would never say that we are accepting Alternative Hypotheses or Rejecting the Alternate Hypothesis. Although technically it means the same we should always affirm in terms of the Null Hypothesis. In this article, we will be focusing only on the Z-test & calculating its statistic value, or Z-score. Choosing the correct Hypothesis Test is the most important part, as selecting an incorrect test would lead to incorrect results & as a result, one would make incorrect decisions. You can refer to this article to learn how to choose the correct Hypothesis Test based on the problem statement.
What is Z-Test?
Z-test is a kind of Hypothesis test based on Standard Normal Distribution. It is also known as Standard Normal Z Test. Using this test, we calculate the Z-score or Z-statistic value. Z-test is used for testing the following:
1. Mean of a single population (μ)
2. Difference between means of two populations (μ1 – μ2)
3. Proportion of a single population (P)
4. Difference between proportions of two populations (P1 – P2)
The Z-test has several assumptions which need to be fulfilled before using it. The assumptions are as follows:
1. The sample size should be more than 30.
2. Sample data should be selected at random from the Population.
3. The Samples should be drawn from Normal Population Data.
4. The Population Variance should be known beforehand.
5. The Samples (or Populations) should be independent of each other.
The Z-statistic value can be calculated using the formula:
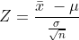
Where,
x̄ is the Sample Mean,
μ is Population Mean,
σ is Sample Standard Deviation
n is the sample size.
Note: This formula is for one sample Z-test.
After calculating the Z-score, the conclusion may change based on the tails of the test. Generally, there are three types of tailed tests: Left tailed test, Right Tailed test, Two-tailed test. The thumb rule is if we have ≤ or ≥ signs between the Ha & the given value, it is a one-tailed test (or Left & Right tail, respectively), or if we have ≠ between the Ha & the given value, it is a two-tailed test.
Thus, after calculating the z statistic value, if our test is left tailed, our conclusion can be determined by the rule: If the calculated Z-statistic value is less than the critical Z value, Reject Null Hypothesis H0 else we fail to reject the H0. If our test is right-tailed, our conclusion can be determined by the rule: If the calculated Z-statistic value is more than the critical Z value, Reject Null Hypothesis H0 else we fail to reject the H0. If our test is two-tailed, our conclusion can be determined by the rule: If the calculated Z-statistic value is less than or greater than the critical Z value, Reject Null Hypothesis H0 else we fail to reject the H0.
Creating Z – test Calculator
Now we will create the Z-test calculator. For this, we need to import the required libraries, firstly.
import streamlit as st import numpy as np
Now, we will accept the sample data from the users. We accept the sample data from the user using Streamlit’s .text_input() method with a default value of 0 since .text_input() accepts a string type value. Then, to convert all the input values into a float value in the next step, first, we need to make sure that there is no empty string between the data as it would not be parsed to float.
raw_data = st.text_input('Enter the Data', value = 0)
raw_data = raw_data.strip()
data = raw_data.replace(" , " , " ").replace(", " , " ").replace(" ," , " ").replace(" " , ',').split(',')
x = [float(i) for i in data]
Next, we will accept the known Population Mean from the user. We accept the user input using the Streamlit method .text_input() and convert it into a float since .text_input() accepts a string type value. The value = 0 argument inside the .text_input() states that the default value for this field is 0 when no data is filled by the user.
mu = st.text_input('Enter Population Mean', value = 0)
mu = float(mu)
Next, we will calculate the Sample Size, Mean & Standard Deviation using the NumPy package. We used the .mean() method to calculate the mean of sample input data, the .std() method to calculate the standard deviation of the sample input data (with denominator degrees of freedom = 1) and len() for calculating the same size of input data.
xbar = np.mean(x) sigma = np.std(x, ddof = 1) n = len(x)
Finally, we will calculate the Z-statistic Value using the formula mentioned above.
z_cal = (xbar - mu) / (sigma / np.sqrt(n))
st.write("Your z - statistic value is: ", np.round(z_cal, 3))
Note that since we are using Streamlit, a Python library for making the Z-test Calculator interactive, we are using its methods in place of generic Python methods. Thus, we are using .text_input() in place of input() for accepting the text input. Also, using the .write() method in place of the generic print() method to display the strings.
Putting it all together for Z-test Calculator
import streamlit as st
import numpy as np
raw_data = st.text_input('Enter the Data', value = 0)
raw_data = raw_data.strip()
data = raw_data.replace(" , ", " ").replace(", ", " ").replace(" ,", " ").replace(" ", ',').split(',')
x = [float(i) for i in data]
mu = st.text_input('Enter Population Mean', value = 0)
mu = float(mu)
xbar = np.mean(x)
sigma = np.std(x, ddof = 1)
n = len(x)
z_cal = (xbar - mu) / (sigma / np.sqrt(n))
st.write("Your z - statistic value is: ", np.round(z_cal, 3))
One can run the script by executing the statement streamlit run .py on the Command prompt or Anaconda Prompt.
On executing this code, when we added sample data, we get:
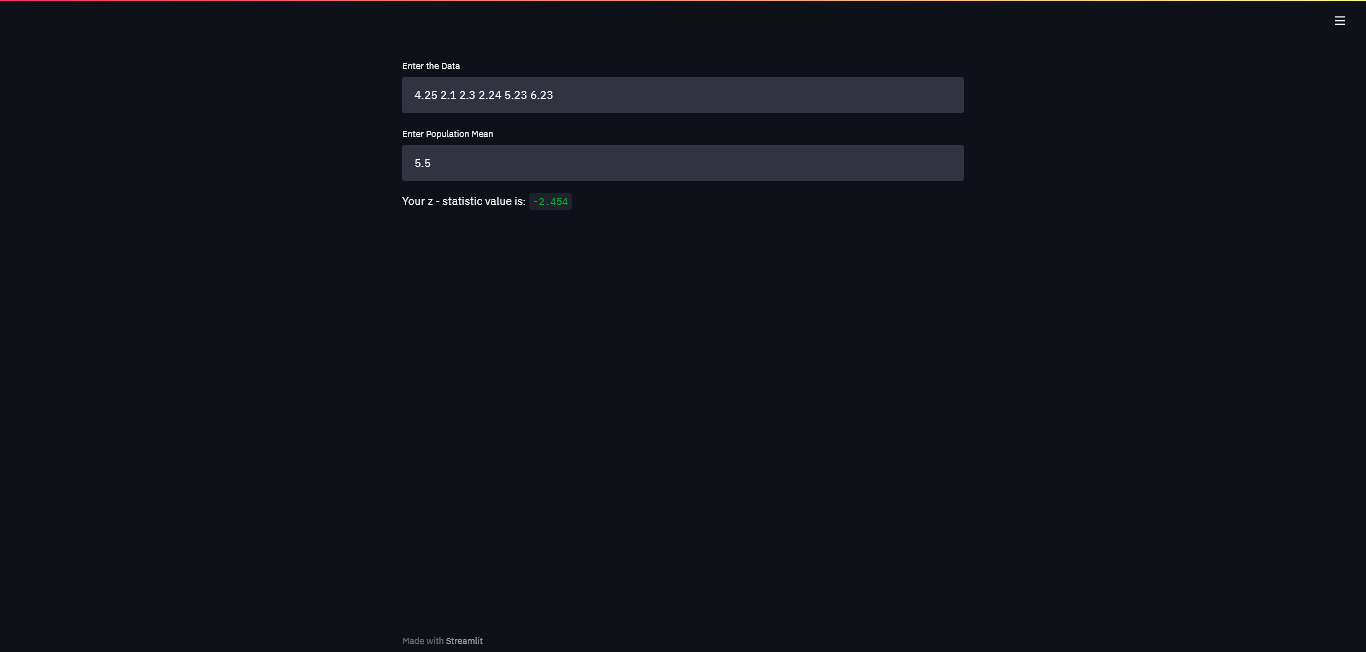
Now, let’s add the error handling functionalities to make it more robust & accessible in any test case. This can be done by adding try-except blocks, wherever necessary.
Putting it all together after adding the try-except blocks
import streamlit as st
import numpy as np
try:
raw_data = st.text_input('Enter the Data', value = 0)
raw_data = raw_data.strip()
data = raw_data.replace(" , ", " ").replace(", ", " ").replace(" ,", " ").replace(" ", ',').split(',')
x = [float(i) for i in data]
except:
st.write('Enter Valid Numerical Data!')
try:
mu = st.text_input('Enter Population Mean', value = 0)
mu = float(mu)
except:
st.write('Enter valid Population Mean!')
try:
xbar = np.mean(x)
sigma = np.std(x, ddof = 1)
n = len(x)
z_cal = (xbar - mu) / (sigma / np.sqrt(n))
st.write("Your z - statistic value is: ", np.round(z_cal, 3))
except:
st.write('Cannot compute z-statistic value. One or more fields does not contain valid Data.')
st.write('Check for the input field having warnings!')
Let’s add a non-numerical value to the Sample Data input field and check the results.
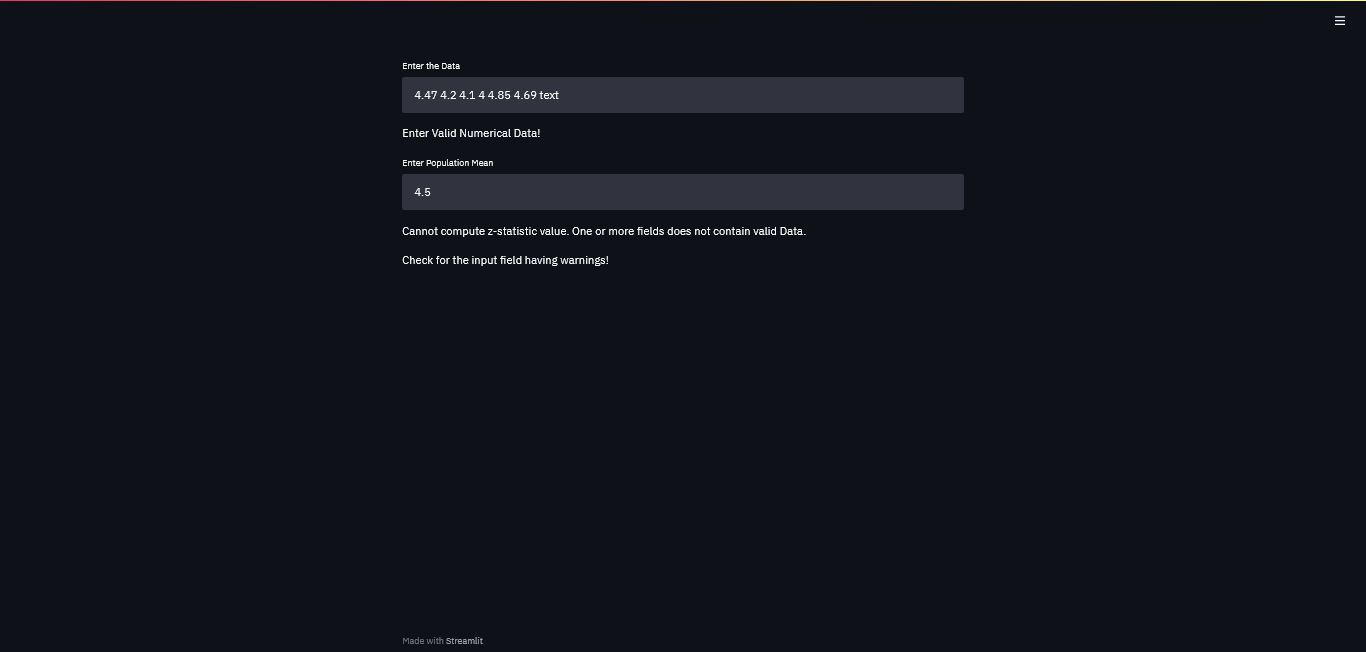
As expected, the script threw the exception with the error message when we added the non-numerical data into the input field.
Conclusions
In this article, we learned about Hypothesis & Hypothesis Testing. We also learned about one of the most popular Hypothesis tests, i.e. Z-test or the Standard Normal Test meant for Standard Normal Distribution. We also looked at the formula for calculating the Z-statistic formula. This formula, later, was used for building the calculator as well. Then, we learned how to build a Streamlit application. We built a One-Sample Z-test statistic Calculator. One can try building a Two-Sample Z-test statistic calculator, p-value calculator based on Z-score, printing conclusions based on the Tail type selected. Similarly, We can also build a confidence interval calculator too. Thus, this created application can be used as a prototype to create a more functional application.
About the Author
Connect with me on LinkedIn.
For any suggestions or article requests, you can email me here.
Check out my other Articles Here and on Medium
You can provide your valuable feedback to me on LinkedIn.
Thanks for giving your time!
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion
IT Engineering Graduate currently pursuing Post Graduate Diploma in Data Science.






