This article was published as a part of the Data Science Blogathon.
Following the #MeToo movement we had a lot of people opening up about their sexual harassment incidents, but as with any internet viral movement, it faded with time. However, this plethora of information can be used effectively to automatically classify abuse incidents into appropriate categories, and this article would help us understand how we can reduce the incidences of Sexual Harassment using Machine Learning

Photo by Danie Franco on Unsplash
Index
1. Business Problem
2. ML Formulation of Business Problem
3. Dataset Analysis
4. Performance Metrics
5. The Objective of the Case Study
6. Exploratory Data Analysis
7. Preprocessing of Description Text
8. Embedding of Description Text
9. Models Used
10. Performance of Metrics achieved
11. Approaches that did not work
12. Deployment of Model
Business Problem
Automatic classification of the type of sexual harassment will enable people who want to make a change in society to better analyze the data, and it is for this very reason that identifying Sexual Harassment using Machine Learning would prove to be a game changer and ensure no such unforeseen incidences take place. Aggregation of data would also be made possible through classification which could prove to be an important use case in enabling faster actions by the authorities. As we already have many personal stories about sexual abuse shared online through this case study we would make scientific use of the data.
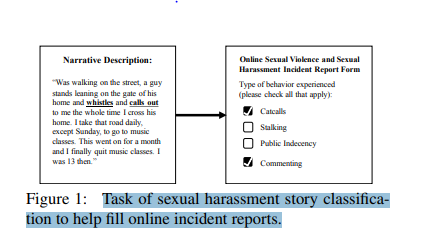
ML Formulation of Business Problem
We would leverage NLP to correctly classify types of Sexual Harassment using Machine Learning (As manually sorting each of them and taking action can take a tremendous amount of time and effort). Single and multi-label classification is used for the task to help fill online incident reports automatically and classify, summarize the data based on the type of abuse.
Data Set Analysis
Data has been collected from Safecity, which collects anonymous reports of crimes in public spaces. The top three most dense categories groping/touching, staring/ogling, and commenting, to use as our dataset out of a total of 13 different categories, as the others were more sparse. Each description may fall into none, some, or all of the categories. Data provided to us already have split for train test and validation sets, we have used the same combination of splits for our models.
The training dataset has two columns
For single-label classification:-
1. Description of the incident:- We have data present in the English language.
2. Category:- Binary variable 1 indicating harassment 0 indicating none
Example for ogling :
“My college was nearby. This happened all the time. Guys passing comments, staring, trying to touch. Frustrating” → classified as 1, which shows that Sexual Harassment using Machine Learning has been identified
I witnessed an incident when a chain was brutally snatched from an elderly lady. The incident took place during the evening. → classified as 0
For multi-label classification:-
1. Description of the incident:- We have data present in the English language.
2. Category:- All labels applicable are present
Example:
“During the morning, a woman was walking by and a thin guy came around and called her names, and commented and stared”
is positive for two classes: commenting, ogling
Performance metrics
We would be using the below evaluation metrics for:-
1. Binary Classification:- Accuracy
2. Multi-label Classification:- Hamming Loss
Hamming Loss can be defined as (Source: Wikipedia) the fraction of the wrong labels to the total number of labels.
The objective of the Case Study
The case study has been developed using the reference of paper (SafeCity: Understanding Diverse Forms of Sexual Harassment Personal Stories (https://arxiv.org/pdf/1809.04739.pdf)). My objective while working on the case study was to match the results of the paper (which uses deep learning) while following a different route(using classical machine learning models), without further ado let’s get going with describing my work.
Exploratory Data Analysis
We first look at the balance of the target classes. As is evident from the below graph, the data is highly imbalanced in all three datasets(train, test, and validation) we have descriptions that are not actual incidents way more than the ones that are harassment incident descriptions.
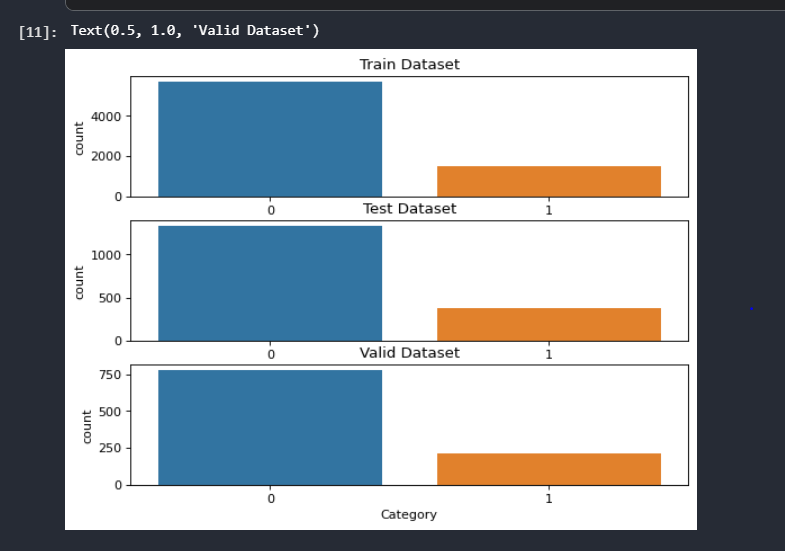
Source: Author
On further analyzing the text data, it was observed that it contains duplicate data which is erroneous, the same description of the text is duplicated and assigned to a different category. As you would be able to see below the description of misbehaved has a category of 0 in row 199 and a category of 1 in row 7175.
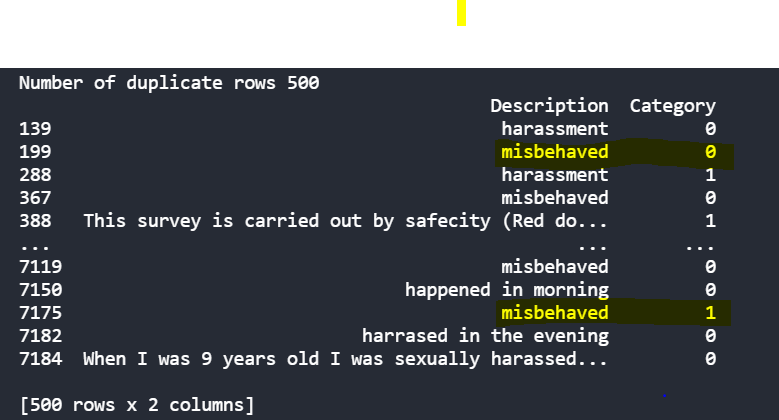
Source: Author
It was also observed that some description texts were not very informative.
1. it was really bad.
2. This survey is carried out by safe city (Red Do…
3. misbehaved
4. harassment
Preprocessing of Description Text
As part of preprocessing, I have taken the following steps. Code for each step followed by a short description. (The entire codebase link is shared at the end of the article for your reference)
1) Deduplication
df_train_og.drop_duplicates(subset="Description",keep= False, inplace = True) df_train_go.drop_duplicates(subset="Description",keep= False, inplace = True) df_train_co.drop_duplicates(subset="Description",keep= False, inplace = True) train_df.drop_duplicates(subset="Description",keep= False, inplace = True)
We use pandas drop_duplicates functionality to deduplicate the dataset.
2) Punctuation and stopword removal
puncts = [',', '.', '"', ':', ')', '(', '-', '!', '?', '|', ';', "'", '$', '&', '/', '[', ']', '>', '%', '=', '#', '*', '+', '\', '•', '~', '@', '£',
'·', '_', '{', '}', '©', '^', '®', '`', '<', '→', '°', '€', '™', '›', '♥', '←', '×', '§', '″', '′', 'Â', '█', '½', 'à', '…',
'“', '★', '”', '–', '●', 'â', '►', '−', '¢', '²', '¬', '░', '¶', '↑', '±', '¿', '▾', '═', '¦', '║', '―', '¥', '▓', '—', '‹', '─',
'▒', ':', '¼', '⊕', '▼', '▪', '†', '■', '’', '▀', '¨', '▄', '♫', '☆', 'é', '¯', '♦', '¤', '▲', 'è', '¸', '¾', 'Ã', '⋅', '‘', '∞',
'∙', ')', '↓', '、', '│', '(', '»', ',', '♪', '╩', '╚', '³', '・', '╦', '╣', '╔', '╗', '▬', '❤', 'ï', 'Ø', '¹', '≤', '‡', '√', ]
def clean_text(data):
stop = stopwords.words('english')
res = []
data['Description'] = data['Description'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
for x in data['Description']:
x = str(x)
for punct in puncts:
if punct in x:
x = x.replace(punct,' ')
res.append(x)
return res
We use the predefined stopwords by the nltk library, if any word of the description is present in the stopword corpus we remove it. The primary reason for removing stopwords is that they do not provide a lot of value to the text. Stopword examples are is, at, on, etc.
Similarly, we have defined a list of punctuations, if any punctuation symbols are present we remove them as well. The reasoning is the same a punctuation symbol may not provide a significant input value in our classification task.
Embedding of Description Text
The purpose of embedding the description field is machine learning model would not understand words we need a way to embed their meaning to vectors and provide the same to the model.
We experimented with two embedding strategies:-
1. TF IDF vectorizer with trigram, bigram, and unigram features with 50 maximum features and a min_df of 15. These values were determined by experimentation.
2. Using universal sentence encoding to embed the sentence. It converts variable-length input text to a 512-dimensional vector. It has been stated in many research papers that using a sentence-level encoder is beneficial over a word-level encoder as it maintains contextual information.
Models Used
We have used the below machine learning models for single-label classification
1. Logistic Regression (as a baseline model)
2. XGBoost
3. LightGBM
For multilabel classification, we have used Binary Relevance with base learners of support vector classifiers and XGBoost.
Binary Relevance:- It solves the multilabel classification by converting them to L single-label classification problems and the output is a union over all the L single label classifications. You can refer to the documentation here. http://scikit.ml/api/skmultilearn.problem_transform.br.html
Performance of Metrics Achieved
For single-label classification we reached the below metrics, these results are comparable to the original paper’s output, for each category on the test data we are almost only 2% below accuracy than the paper because the paper uses complex deep learning techniques and we have used classical machine learning models in our case study.
Case study metric achieved:
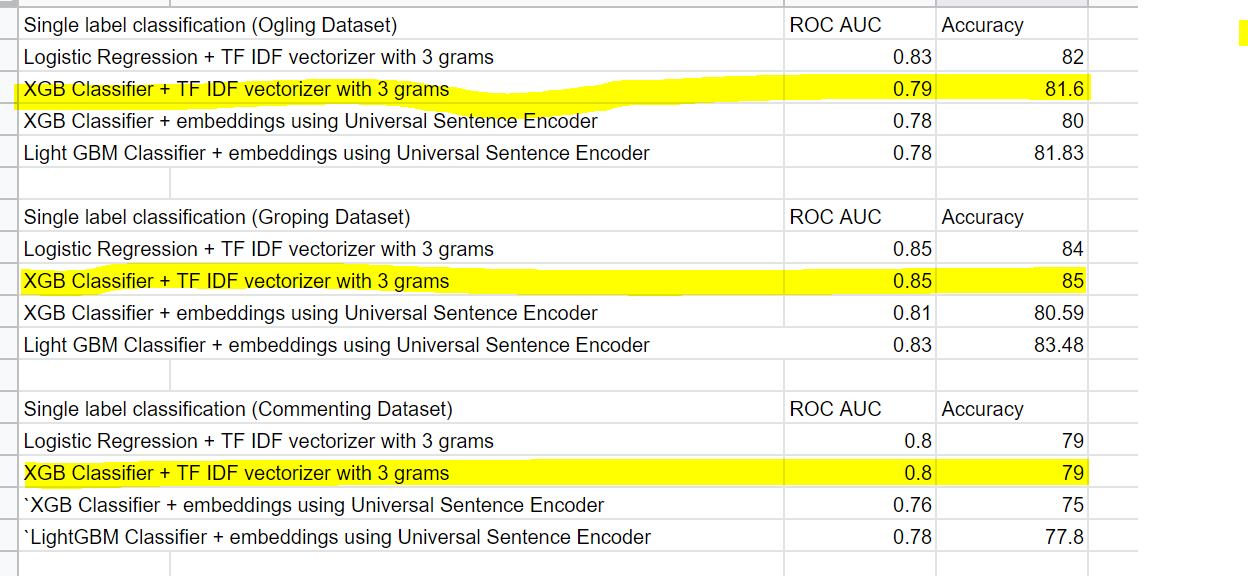
Source: Author
Original paper’s metric:
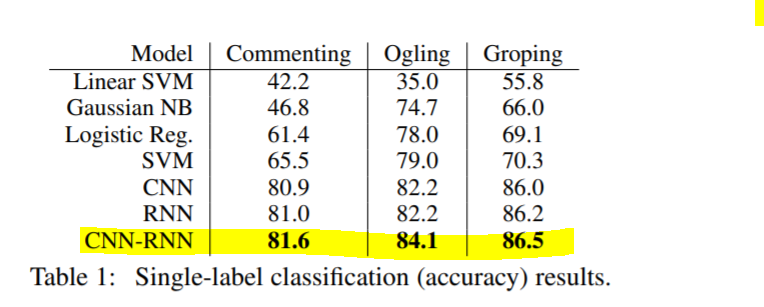
https://arxiv.org/pdf/1809.04739.pdf
For multilabel classification, our case study performs slightly better than the paper as can be seen from the hamming scores below.
The case study’s metric achieved:

Source: Author
Original paper’s metric:
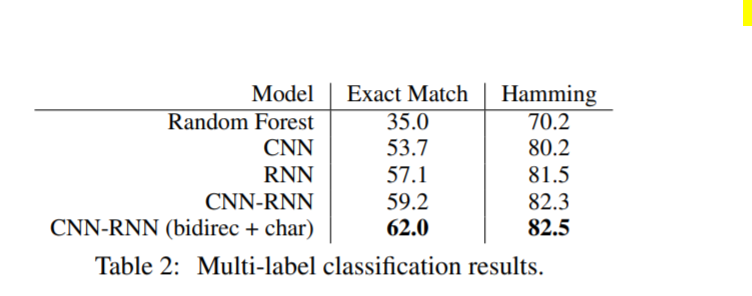
Approaches that didn’t Work
Tried SMOTE for imbalance in data, did not improve accuracy
Deployment of Model
I have used Flask API and Heroku to deploy my model. It is available for access
https://predict-abuse.herokuapp.com/index
Below is a live demo of my deployed model:
https://youtu.be/9_YYODlDHj
Link to my entire code base:- https://www.kaggle.com/aliphya/casestudy-eda-baseline-model
References
https://mlwhiz.com/blog/2019/01/17/deeplearning_nlp_preprocess/
Upgrade your beginner NLP project with BERT
Deep learning doesn’t have to be complex.
https://deeplizard.com/learn/video/gZmobeGL0Yg
About the author
I am Alifia, currently working as an analyst. By writing these articles I try to deepen my understanding of applied machine learning.
Link to my entire code base:- https://www.kaggle.com/aliphya/casestudy-eda-baseline-model
To read more articles published by Alifia, click here
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.





