This article was published as a part of the Data Science Blogathon.

Hey Folks!
Welcome to the NLP article series. so far we have covered the multiple text processing techniques in the first article. In the second part of the NLP article series, we saw different types of feature extraction techniques and word embedding with python codes.
Table of Contents
- Parts of Speech Tagging
- Name Entity Recognition
- Text-Classification
Introduction
In this article, we will go one step further and we will discuss some very important NLP jobs.
After having an idea about multiple features extraction techniques and text cleaning it’s time to perform some NLP jobs. there is a wide variety of jobs we can perform using NLP. some of them are part of speech tagging, entity extraction, and text classification.
Part of Speech Tagging
Part of speech(POS) tagging involved labeling the words with their respective part of speech ie. noun, adjective, verb, etc.
It’s a very crucial part of natural language processing. Named Entity Recognition is based on these phenomena which we will discuss further in this article.
Sentiment Analysis, Named Entity Resolution, Question Answering, Word Sense Disambiguation is based on Part of speech tagging.
There are 2 ways to build a POS tagger
- Rule-based: based on rules
- Stochastic based: based on the sequence of words with the help of hidden Markov model
Implementing in Python
we have given a document and we have to tag every word with their part of speech.
text = “I love NLP and trying to learn it by reading articles”
Before further doing let’s filter out the stopwords.
#---importing the library------
import nltk
#-----loading the stopwords---------
from nltk.corpus import stopwords
stop_words = set(stopwords.words('english'))
filtering out all the stopwords
from nltk.tokenize import word_tokenize,sent_tokenize #---Generating the tokens of words ------ words = nltk.word_tokenize(text) #-----Filtering the stopwords words = [word for word in words if w not in stop_words] words

nltk.pos_tag() takes the word in a list and returns the Part of speech.
POS = []
for word in words:
POS.append(nltk.pos_tag([word]))
POS
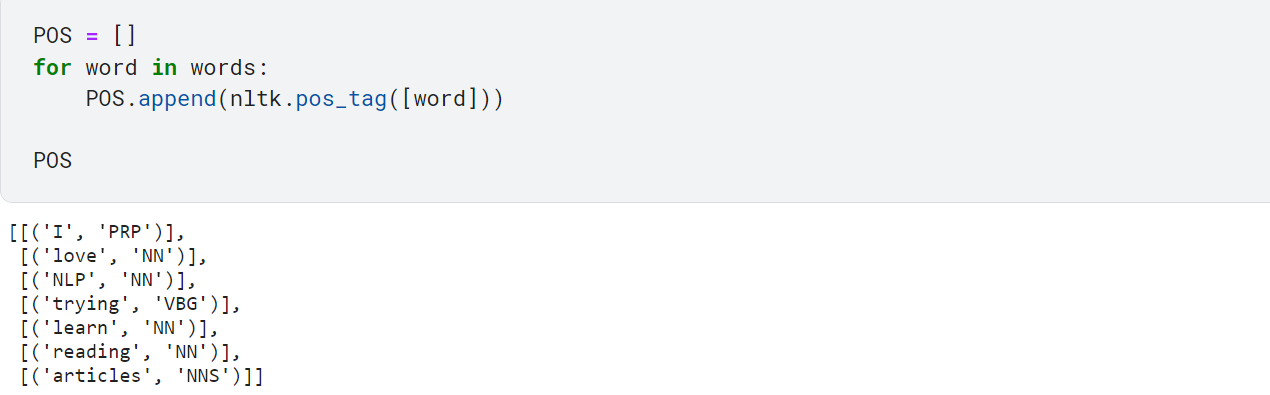
Here the part of speech is written in their short form:
- NNS → Noun Plural ie.Tables
- NN → Noun Singular ie.Table
- VBG → Verb
- PRP → Pronoun
Based on this idea we can extract different parts of speech from a document but if we want to extract something very specific suppose we want to extract different country names, different organization’s names from a document we can’t do this using POS tagger, here we use the idea of Named Entity Recognition.
Name Entity Recognition
Extracting different types of entities from a document is based on POS but it is able to identify a wide range of entities from a document.ie Extracting all names, countries names from a document.
There are multiple libraries available for performing entity extraction.ie SpaCy, NLTK chunker,StanfordNER etc.
we will use SpaCy since it’s easy to implement and gives better results
Implementation with Python
#-----Installing SpaCy ---- !pip install spacy !spacy download en_core_web_sm
#---- Loading the Spacy Pipeline
Import spacy
nlp = spacy.load('en_core_web_sm')
spacy.load(‘language_model’) returns a language pipeline.
text = "Samsung is ready to launch new phone worth $1000 in South Korea"
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.label_)
doc.ents→ list of the tokensent.label_→ entity nameent.text→ token name
All text must be converted into Spacy Document by passing into the pipeline.
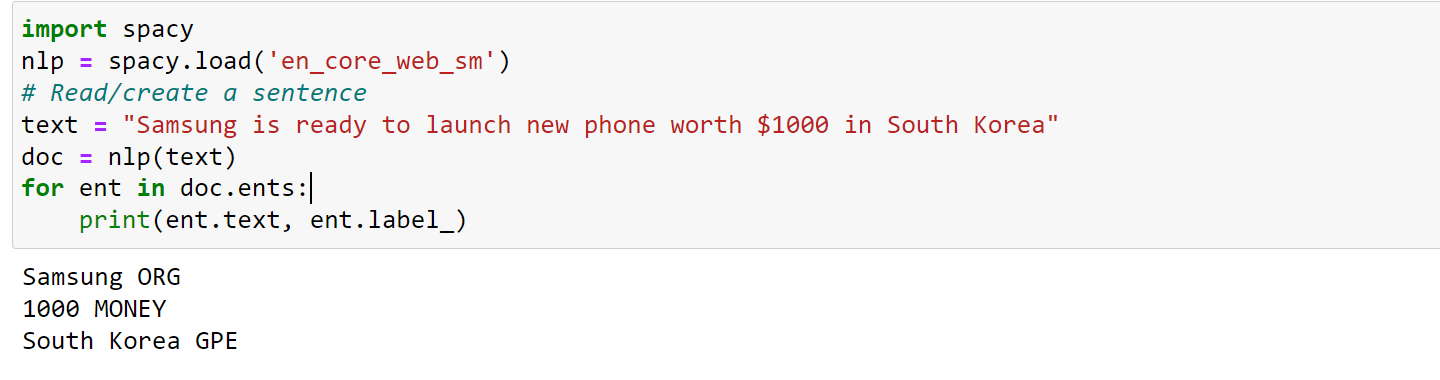
- ORG → Organization
- 1000 → Money
- South Korea → GeoPolitical entity
SpaCy gives accurate results and it can be used where our objective is to filter out entities.
Text-Classification
Here the idea is to classify a text based on the pre-trained category. There are a wide variety of applications based on Text-Classification.
- Resume Shortlisting
- Spam Classifier
- Document Classification
- Sentiment Analysis
You may have seen that there is a directory for all spam messages in your message inbox, a machine learning model works in the backend that classifies spam mails vs our normal mails.
Building a Spam mail classifier in Python
We need a dataset containing all spam messages and normal messages in order to train a model. we will train a baseline text classifier in order to understand the training process.
1. Download the dataset from here in your working directory.
2. Import the necessary libraries to load the dataset into a pandas data frame and perform some data cleaning.
import pandas as pd
df = pd.read_csv(r'spam.csv',encoding='ISO-8859-1',usecols=['v1','v2'])
df.rename(columns = {'v1':'Target', 'v2':'Email'}, inplace = True)

As you see our raw data is not cleaned we need to perform some data cleaning operations.
df.Target.value_counts()

In the dataset most of the rows are normal mails, only 747 mails are spam. Our dataset is Imbalanced. This can be fixed by either upsampling or downsampling which we will perform in the next part.
3. for text cleaning I have made a library text-hammer that makes our text cleaning much easier. installing and using this library is so easy.
!pip install text_hammer import text_hammer as th
Creating a function for text cleaning
def text_cleaning(df,col_name):
#-----Remove Stopwords----
df[col_name] = df[col_name].progress_apply(lambda x: th.remove_stopwords(x))
#----Remove Special Character----
df[col_name] = df[col_name].progress_apply(lambda x: th.remove_special_chars(x))
#---Remove accented characters---
df[col_name] = df[col_name].progress_apply(lambda x: th.remove_accented_chars(x))
# ---Removing HTML tags and URL---
df[col_name] = df[col_name].progress_apply(lambda x: th.remove_html_tags(x))
df[col_name] = df[col_name].progress_apply(lambda x: th.remove_urls(x))
#--- Converting into root words--
df[col_name] = df[col_name].progress_apply(lambda x: th.make_base(x))
return df
Calling the text cleaning function: text_cleaning takes a df and the column name containing the Raw data.
df = text_cleaning(df, 'Email')
Mapping the spam with 1 and ham with 0.
df['Target'] = df.Target.map({'ham':0,'spam':1})
Splitting the whole data for training and testing
Using train_test_split in order to split the dataset into training and testing purposes.
# splitting the data to check our final model from sklearn import model_selection X_train,X_test,y_train,y_test = model_selection.train_test_split(df['Email'],df['Target'], stratify = df['Target'], test_size = 0.2, random_state = 42)
X_train,y_trainis the data that will be used for training purposes.X_test,y_testwill be used for prediction purposes.
Creating a Training Pipeline
Creating Pipelines lets us combine multiple steps in a single one. The same Pipeline can be used for training and for prediction.
Here we have combined Feature Extraction and model training in a single step using a pipeline.
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import Pipeline
vectorizer = TfidfVectorizer()
classifier = Pipeline([('feature_generation', vectorizer), ('model',MultinomialNB())])
- MultinomialNB Here we are using the Multinomial Naive Bayes model for our classification task, Naive Bayes models perform well for discrete classes, read more.
- The pipeline contains 2 functions in it. Passed data will be first converted into features using TF-IDF vectorizer and then the features will be passed to the MultinomialNB model.
Training the Pipeline
classifier.fit(X_train,y_train)
Prediction
After training the classifier we can use the same pipeline for the prediction.
text = ['Hey Abhishek can we get together to watch a football match',
'Free entry in 2 a weekly competition to win FA Cup final']
classifier.predict(text)
The predict method inputs a list of texts and predicts in the form of 0 (normal),1 (spam).

the first sentence is not spam mail hence predicted 0 and the second one is predicted as spam 1.
Performance Metrics
sklearn provides a metrics class to see how our model is performing on a dataset.
classification_report takes true_label and predicted_label as input and print a report.
from sklearn import metrics y_predicted = classifier.predict(X_test) print(metrics.classification_report(y_test,y_predicted))
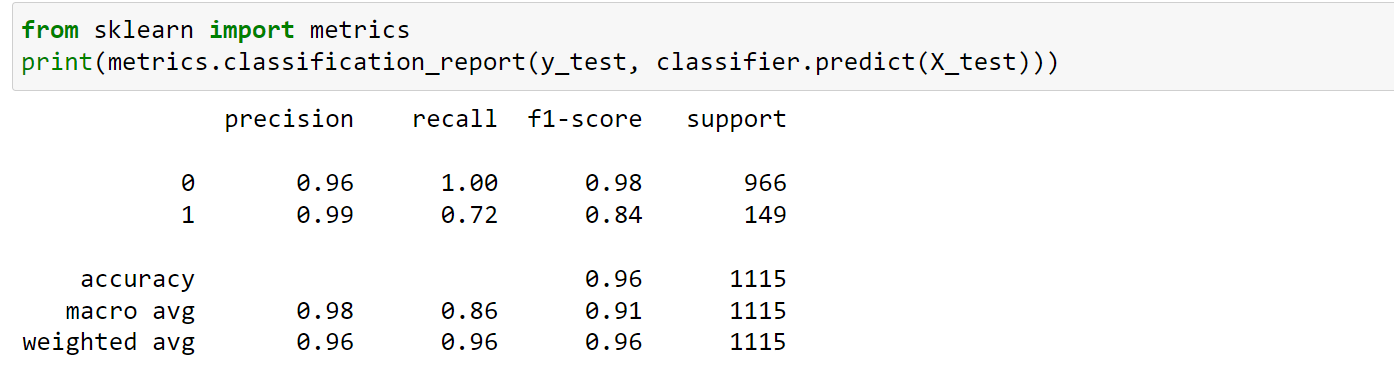
As you see our model can predict normal mails with high confidence .but the prediction of spam messages lags a bit due to the imbalanced data.
from sklearn.metrics import confusion_matrix results = confusion_matrix(y_test, y_predicted) print(results)

Confusion Matrix indicates that our model classifies 177 spam messages correctly,61 spam messages are classified wrong and 1434 normal messages are correctly classified.
Model Evaluation
the model we just trained using the sklearn pipeline is a baseline model. we definitely can improve the results by taking the following steps:
- Using Word-Embedding can give us better results
- Eliminate the data imbalance
- Using a Deep learning-based model ie. LSTM, BERT, etc.
End-Note
In this article, we have discussed text classification which includes Part of speech tagging, Entity extraction using Spacy and we build a model for classifying spam msgs. the model we build is just a baseline model we definitely improve it further. creating pipelines is a good practice while training the model since it combines multiple steps.
Streamline your text classification workflow: Enroll in our ‘Mastering Text Classification with Spacy‘ course and learn to build robust models, leverage pipelines, and take your NLP skills to new heights!
In the next article, we will discuss
- Topic Modelling
- Text to Speech
- Language Detection and Translation
Feel free to write to me on Linkedin.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
A data enthusiast exploring the leading technologies related to the data




