Introduction
Data Science, Machine learning, Artificial Intelligence – you would have come across these terms very often while talking to your peers, reading through a blog post or in general having day to day conversations with family and friends. You would also have been in many decision-making spots yourself – while choosing to buy a smart TV for your home, your next smartphone, selecting a smart sound system for your living room, while making your next investment-related decisions or even while making your next travel itinerary.

1. Understanding Machine Learning and its Applications in the Real World Intuitively
Many of today’s day to day needs are governed by Smart and Intelligent systems that make your life very easy and convenient – to the extent that all of your experiences are more or less customised to your likes and choices intuitively.
Small instances – being – When you are buying anything online via e-commerce platforms – you are automatically nudged to products that you might like further – based on your earlier purchases, or the suggestions to which TV – series or movie to watch next on the OTT platforms that you have subscribed to, your choicest songs being played instantaneously on any of the music platforms like Gaana.com, Jio-Music, Spotify or YouTube music – the moment you select any song to play – based on your mood and choice of genre.
Even when you type an email – there are autocomplete suggestions. When you are booking your next flight – suggestions for destinations automatically pop up. And – when you are booking an uber using Amazon Alexa – your smart assistant intuitively asks you which destination to select, what time to book and whether you would want a sedan or an SUV.
Those friend suggestions on the social media apps, the suggestions on the smart portfolios – on which stock to buy next, or various geo-map applications suggesting you the best route possible while driving the car to your destination on a weekend. The chat assistants on various apps – also ask you the next intuitive question – as if you are talking to a human.
How does that happen? How do all these applications read your mind?
How all your next decisions are automatic – nudged towards – the custom choices that are preferred to your need?
Well, these are all examples of the AI-enabled smart systems – that learn from a user’s behavioural patterns and a large pool of different clusters of like-minded users – and then make suggestions based on the data backed decisioning systems and predictive modelling techniques which form the backbone of these smart intelligent systems.
2. Intuitive understanding of the ML Ecosystem
Now that you have seen, how Artificial Intelligent systems form an integral part of the day to day life – let’s understand – how data-backed decisions are made using machine learning and predictive modelling?
Data is the new oil. You would have come across this phrase often.
Let us understand what that means?
Today – any activity you perform as a user- there is a digital footprint that you leave behind – directly or indirectly. All the data of the internet browsing history, call logs, product searches, investment-related searches, purchase-related information etc are being saved by the applications that you use.
Let us understand this with an example.
Let’s take an example of an ABC bank – it has an already existing customer base of 10k users – who prefer doing banking with them.
Now – from the time the customer has opened a bank account with the bank, they have the information of the earning capacity of the customer, the kind of expenses he or she makes on a weekly / monthly basis, the genre of expenses say – house rent, travel to work back and forth, luxury expenses like premium travel, entertainment, fine dining v/s day to day expenses on needs like groceries, garments, fuel refill, electricity bill payments etc.
The ABC bank then would also have a fair understanding of the savings the customer base is making and the kind of financial behaviour they have – basis their Asset-Liability profile.
The information they have about their demographics like age, occupation, gender, family – number of dependents and other levels of investment and debt information that they have.
Illustration 1: Sample: ABC Bank: Data Dictionary
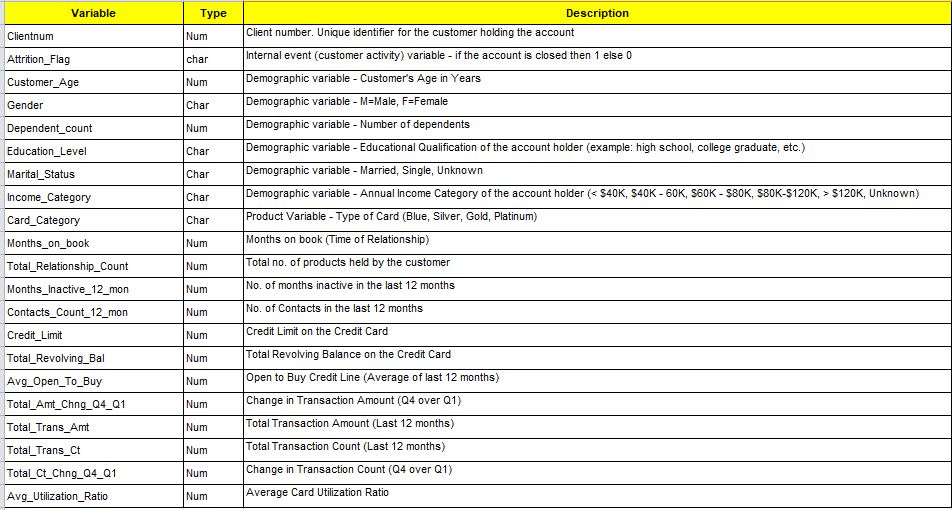
Don’t you think that on the basis of the above data points that they have for their customers – they will be able to make wise recommendations of the multiple banking products to their customer base – like credit cards, debit cards, investment products, insurance, loans (home loans, vehicle loans, small loans etc ) and others?
This is how data is leveraged by organisations to make well-informed decisions about their customers, the kind of next product that they want to roll out in the market, which strategy has more chances to work – versus which is more likely to perform poorly.
6 pillars of designing a machine learning problem
Whenever you think of designing a Machine learning application or solving a problem from an ML perspective – there are 6 pillars that you need to keep in mind.
Which domain are you designing it for? Who are your end customers?
What will be the business impact it will make? What is the product that will be impacted – is it a product or tool that you are designing / or a feature to improve it? How will you convert the business problem into a data science problem? What data will you need to start off with and how will you collect it? Finally – What technology and tools that you will use to enable your feature improvisation/product building? And then – how will you ship it to market?
The 6 pillars of designing an ML problem:-
- Domain –Finance, E-commerce, Ed-Tech, Digital Marketing?
- End Customers – Internal teams / B2B / B2C ?
- Business – Impact on business – which business problem?
- Product – What product is it for? Or Product features?
- Data Science – How to translate it into a DS problem?
- Technology – Which technology and tools to leverage?
For example – you are designing a model to predict – whether the Customers using the credit card products will churn out from the ABC bank or not churn?
Here let’s look at it from the perspective of these 6 pillars:-
- Domain – Banking / Financial Services
- End Customers – Product team, Marketing team and Business decision-makers
- Business – Credit Card Product vertical of the bank – aim to stop the existing Credit Card customers from churning out of the bank.
- Product – Credit Card
- Data Science – Predictive model for Credit Card Churn Prediction
- Technology – SQL – to extract the data, Python – to process the data and build POC models, AWS cloud services to deploy the model and move it to production in real-time.
3. Steps Involved in the Machine-Learning Lifecycle
Understanding – on the basis of a case study.
a. Defining the objective question – What business problem am I trying to solve? How will I convert it into a specific Data Science problem statement?
Illustration 2: The ML Steps: – with examples

b. Hypothesis Generation – Develop a 360-degree view of the problem at hand – understand what factors will impact the outcome? Develop the intuition behind it.
Involve all the business stakeholders like the Product teams, Marketing teams and Business leaders to make an effective hypothesis generation and finalise on them from a business relevance point of view.
Illustration 3: – Hypothesis Generation: ABC Bank Churn
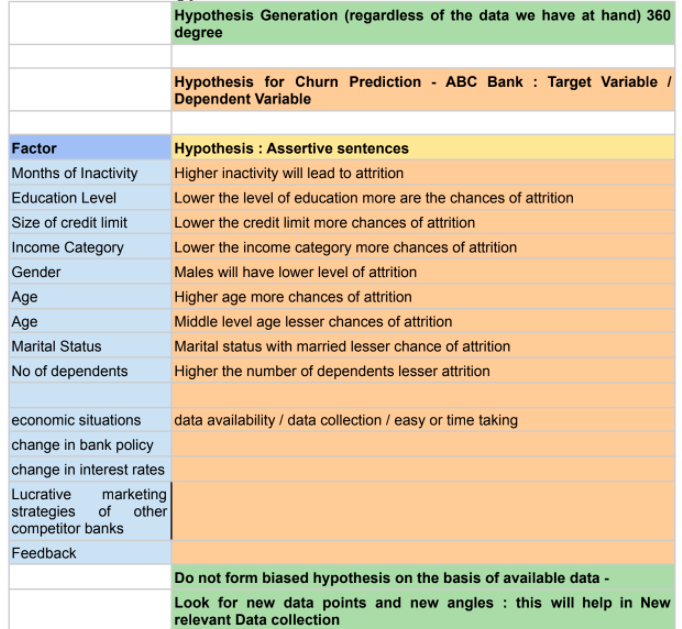
c. Data Collection / Extraction – What data will I need to start with? Identify the data sources to collect the data. Is there any data that is missing? If so, how can I start collecting it? How can I collaborate with different teams to start and streamline the processes behind it?
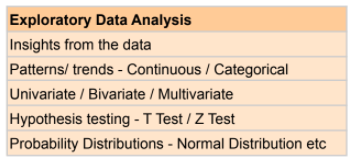
d. Exploratory Data Analysis – Now that I have the data, how do I understand it? What information does it give me? What kind of data do I have? What factors? Are there any missing values in the data? What patterns and trends do I observe in the existing data? Meanwhile, for phase 1 I will use the existing data to build a POC ( Proof of concept) – can I set up parallel processes to collect the additional data points which currently the Databases do not have – like conduct a survey, collect additional data points from existing customers, explore alternate resources from where the data can be derived. Or collaborate with third-party data vendors who provide relevant data for the domain?
Illustration 4: EDA
e. Data preprocessing and Feature generation – Once I have thoroughly explored my data at hand – developed an understanding of which features are present, what trends do I observe, Are there any outliers in the data, are there any missing values? How do the different variables depend on each other – and what relation do they have with each other –
Can I extract new features from the existing data? How do I deal with the missing values in the data? How can the outlier values be treated? Do they provide any valuable information? What are the reason behind these missing values and the outliers?
Illustration 5: Data Preprocessing

Finally, How do I bring my data in a form that can be used for predictive modelling? How do I deal with factors which are at different scales – say Customer age between 0 – 100 and Account balance ranging in 1000s or even lakhs?
How can I bring it to a proper format – where I can start my predictive modelling? Create a data farm and feature set – which is the final input to the predictive models.
f. Predictive Modelling – Once the data farm is created and a feature set is generated, how do I build predictive models?
What are predictive models? Are they only heavy mathematical models – or can they be as simple as any rule-based engines based on the trends of the data?
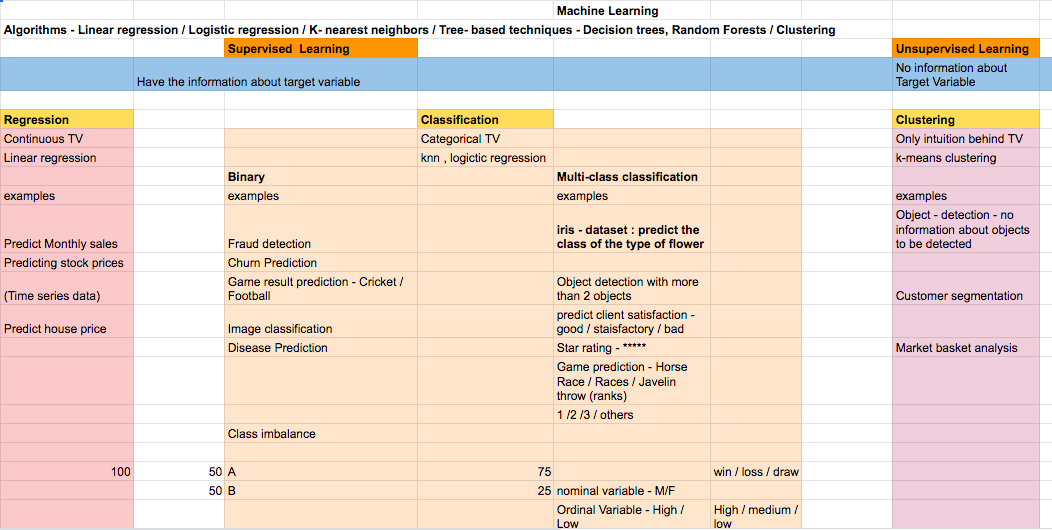
Am I solving for a Supervised problem (for which historical outcomes/labels/trends are already known ) or am I solving for an Unsupervised problem- where though the nature of outcomes is known, the final output is still vague and not a well-defined set?
Which techniques do I use for the same? And how can I implement them using Python / R – and libraries that these languages provide?
Illustration 6: Machine Learning – Different Techniques and Algorithms with examples
Predictive Model Evaluation:
How do I know if the results are up to the mark? How do I evaluate my model performance? If the results are average –
How do I improve it further and finalise my results?
Illustration 7: Model Evaluation: Regression
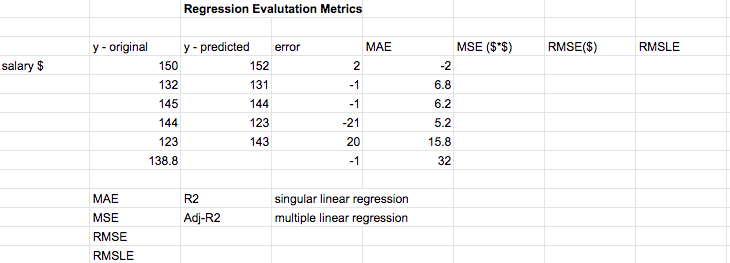
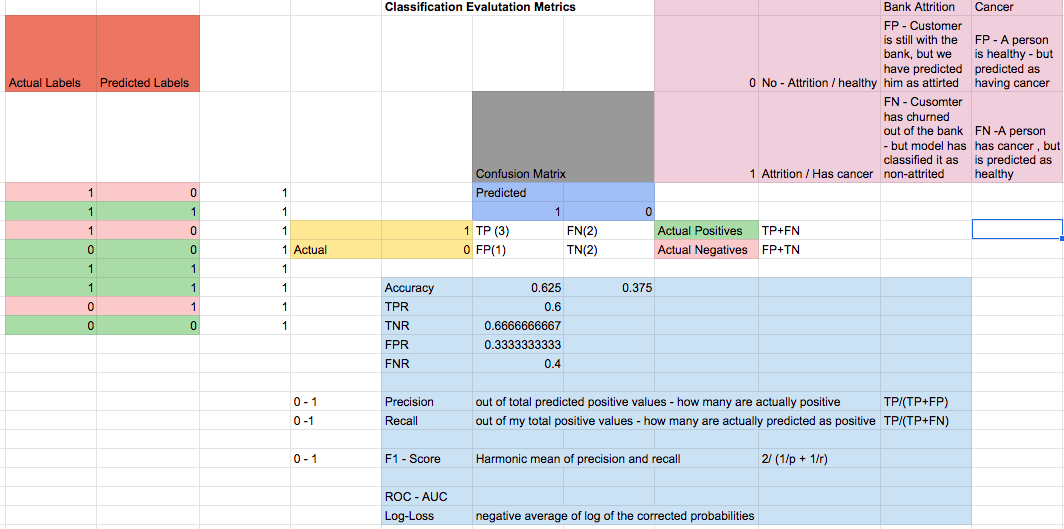
Illustration 8: Model Evaluation: Classification
g. Communicating the results – Now that we have the final results in the form of a model output or simple rule-based engine or any product based feature improvement – we then need to communicate the results to the Business stakeholders and the end audience – in a manner that the results are interpretable and can be understood in simple intuitive terms.
These can be in the form of model output, blog post, email communication or an End of project meeting/discussion.
Based on the feedback that is obtained – the results can be further improved – with subsequent iterations and then we can go ahead with the final version of the Proof of Concept – which can be a predictive model, product feature rollout or report implementation.
h. Model Deployment – Once the results are presented and agreed upon – for the Proof of concept. The next step is to go ahead and deploy the model in production.
i. Way Forward – Once the Predictive model is deployed into production – we then observe and monitor the results over a specified amount of time. Then, based upon the real-time performance of the model – we further initiate model upgrades from time to time and have proper monitoring and maintenance process in place.
EndNotes
Hope you all liked my article on Machine Learning Lifecycle. If you have anything to contribute to my article or share different views then please comment below. Would love to connect with the community and have meaningful conversations with you all.
Read the latest articles on our website.
Connect with me on LinkedIn or email me at [email protected].






