Getting Started with Computer Vision: Basics and Starter Projects
This article was published as a part of the Data Science Blogathon.

What is Computer Vision?
Artificial Intelligence is an upcoming field with a vast study scope. Computer Vision is one of the AI branches that has proved to be very beneficial to solve real-life issues such as OCR recognition in driving number plate recognition which scans text from images. It enables AI to view the world and make use of input data observed to make changes to the environment or solve problems encountered. Computer Vision will specifically utilize techniques to train models to capture and extract useful data after interpreting information from an image or video stream.
Most beginners get confused between image processing and computer vision as both deal with similar concepts. Image processing is the method that is applied in order to enhance the images by adjusting parameters like brightness, contrast, zoom, rotation angle, and many more. It does not process the image to obtain useful qualities, while computer vision focuses on extracting valuable information from images and videos. At times computer vision may make use of image processing techniques to raw images to improve the feature understanding process.
How does Computer Vision Work?
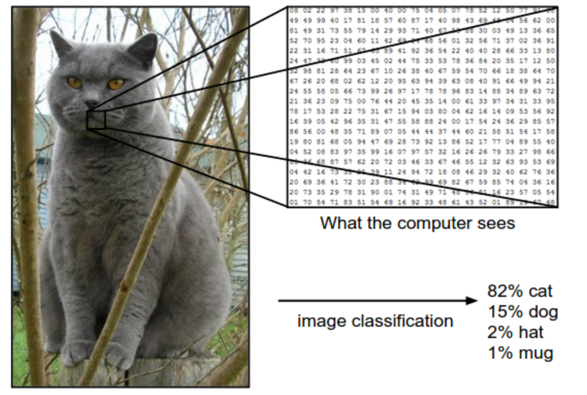
Image Source: InData Labs
The computer does not view images as a whole picture like us, it will break the image into pixels and use the RGB values of each pixel to understand if there is any important feature hidden in the image. Computer Vision algorithms focus on one patch of pixels at a time and utilize a kernel or filter which contains values for pixel multiplication for object edge detection. The computer will observe all aspects of the image like colours, shadows, strokes, and more to recognize and differentiate images.
Nowadays, we make use of Convolutional Neural Networks for model building and training. CNNs are specialized neural network used in image recognition and processing that is specifically designed to process pixel data. Convolutional layers contain multiple neurons and tensors which assist in the processing of a large dataset as input by learning to adjust values to match the features that are significant to the differentiation of various classes. This is done through extensive training of the model.
What is OpenCV?
OpenCV is an open-source library of programming functions that is used widely for the tasks of real-time Computer Vision and Image processing. It can carry out tasks like face detection, object detection and tracking, landmark detection, handwriting recognition, and many more. It supports multiple languages including Python, Java, and C++.
Project to Get Started
Now that the basic concepts are clear, let’s get started with our project so that you can get a basic overview of what is involved in Computer Vision. We will be using computer vision to detect fire with an image dataset of fire and non-fire from Kaggle.
This project was done on Google Colab using Python and run with GPU.
Step 1: Import Libraries
For any project, the first step will be importing all the necessary libraries that will be utilized throughout the code. For this particular project, you will require libraries like Numpy, Pandas, OS, OpenCV, Tensorflow, Keras, Scikit-Learn, Matplotlib, and Seaborn.
Step 2: Load Data
As I used Google Colab, I mounted the data from my Google Drive. You can directly access the file from your directory if you use any other IDE like Jupyter Notebook.
For Google Colab: You will first have to download the data from the Kaggle site and upload it to your Google Drive. Once uploaded, mount your Drive to the notebook using the code and give access. Then you will be able to access the directory inside your Notebook.
Load the respective folders paths into variables that can be used in the code.
Step 3: Exploratory Data Analysis
EDA is a very necessary step for any project. It will allow us to understand what data we are dealing with and how we can plan our journey to reach our end goal.
I tried to visualize the data distribution of the dataset using matplotlib to plot a graph from the dataframe created using the value counts of image folders.
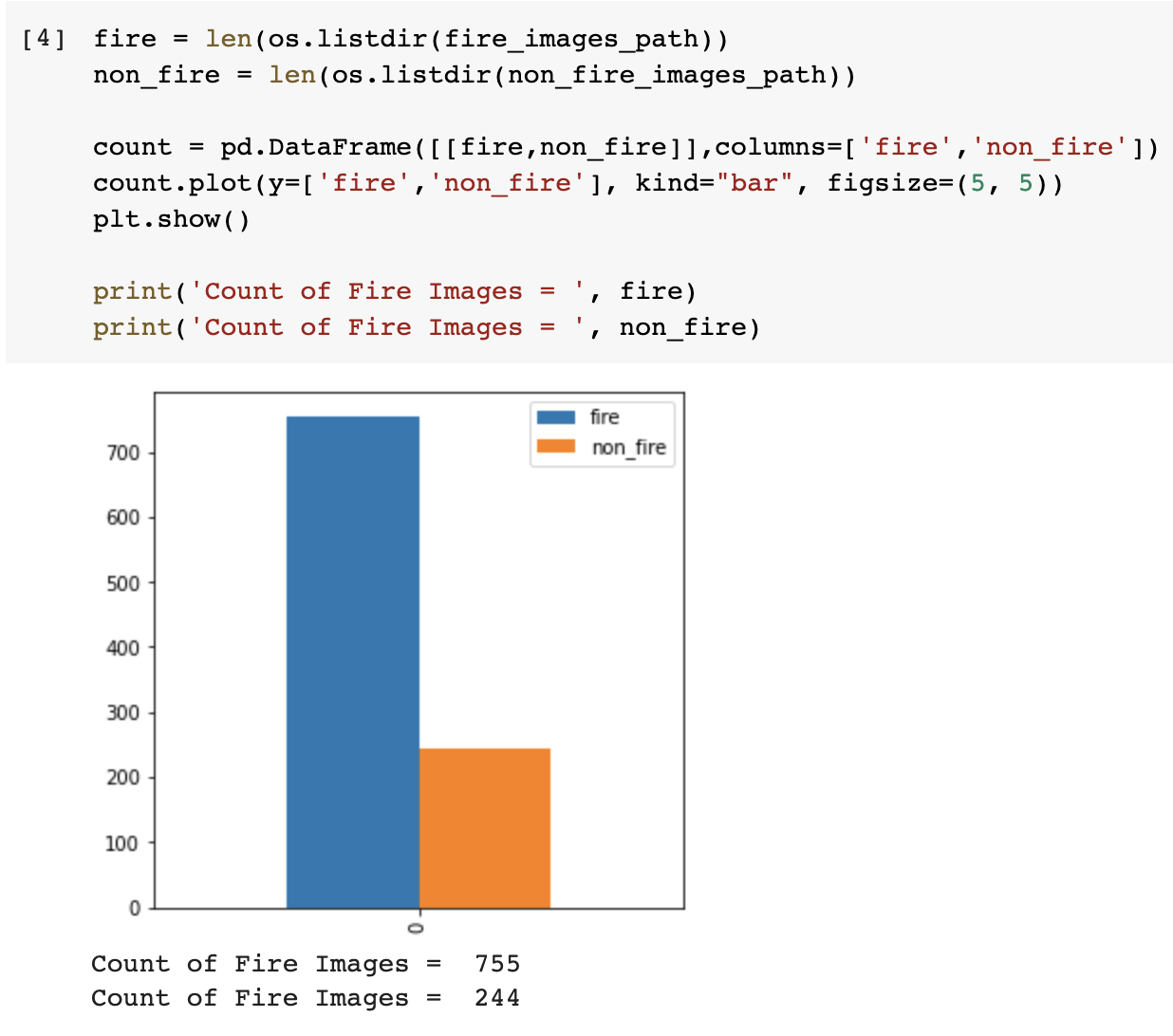
I also displayed 5 images from each class to check the type of images we would be dealing with. From this, I discovered that the images are of various shapes and sizes which could cause issues in training. Hence, we should normalize the size of the images before splitting them into train-test. We can do this using the resize function from the OpenCV module.

Step 4: Train Test Split
Once the images are normalized, we can split them into train, test and validation groups. The train set will be used in the training process of the model, the validation set will be used to tune the parameters of the model, the test set will be used for testing of the model.

Step 5: Model Building & Training
Next, we will build a simple sequential Convolutional Neural Network using Tensorflow and Keras. This CNN will consist of Conv2D, MaxPooling2D, Flatten, and Dense layers with activation function Relu.

Here, the model will be taking images and carrying our feature extraction to understand the signification features that will help in the classification of the images as Fire or Non-Fire.
The 2D Convolutional layer is the main layer in the CNN which contains a set of kernels that help the model learn parameters through training. The filters convolve with the input images to create a feature map that is used to see which regions in the input image are relevant to the class.
The Pooling Layer is added to reduce the dimensions of the feature maps. It reduces the number of parameters to learn and the amount of computation performed in the network. The pooling layer summarizes the features present in a region of the feature map generated by a convolution layer.
The Flatten Layer will be converting the data into a 1D array for inputting it to the next layer. We flatten the output of the convolutional layers to create a single long feature vector.
The Dense Layer will ensure that all outputs from the previous layer are input to all its neurons, each neuron providing one output to the next layer. It is the fully-connected layer in Keras and will have the neurons and activation function specified in this layer.
The activation function is used to apply a certain degree of nonlinearity to the output of a neuron. ReLU is a function that will output the input directly if it is positive, otherwise, it will output zero. It will prevent the vanishing gradient problem, allowing models to learn faster and perform better.
This model was fit and complied with epoch 20 and optimizer, Adam.
Step 6: Evaluation & Prediction
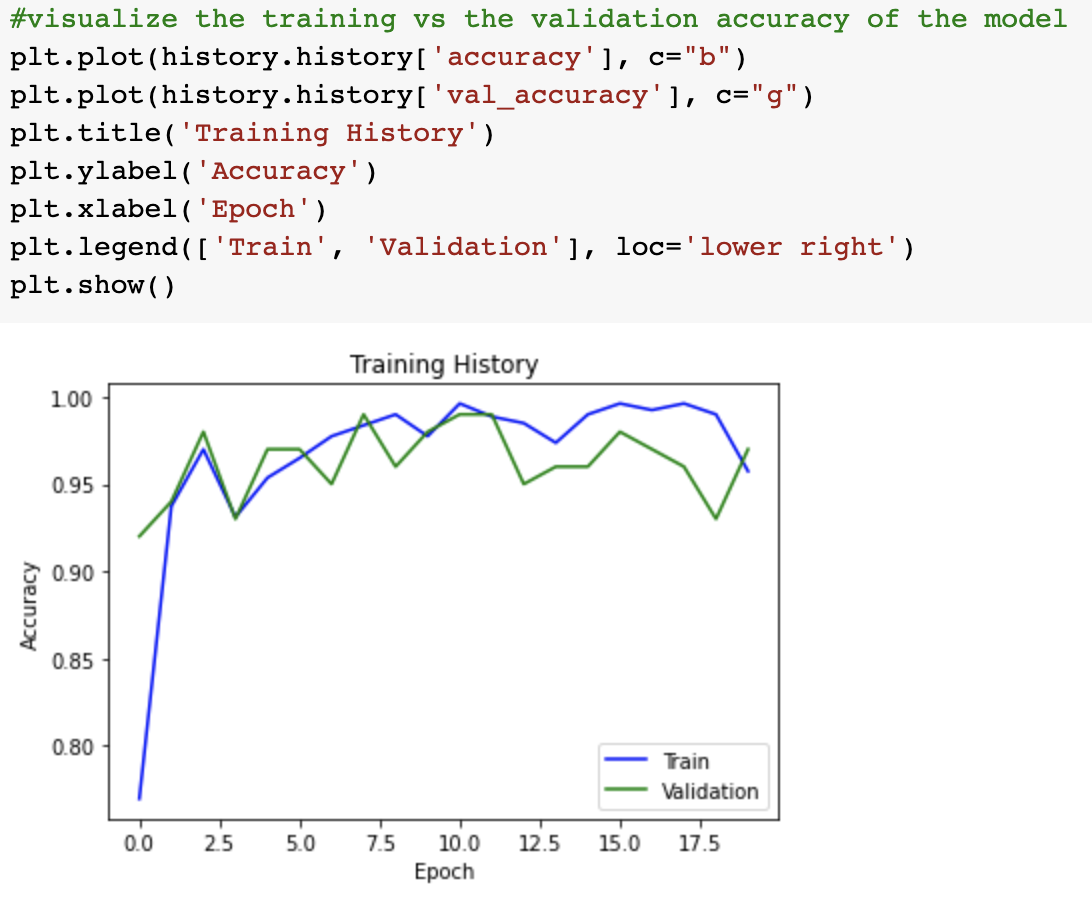
After training the model we reached an accuracy of 91% with a loss of 38%.
We plot a confusion matrix and got a positive response with 2 and 7 False Positive and False Negatives respectively. We also carried out predictions with a test set and visualized the results. For a simple model, this result is good as it is predicting the output with high accuracy.
How to Improve these Results?
- You can apply Data Augmentation which enhances the images to produce better results.
- You can try to build a model with the help of a pretrained model like VGG or MobileNet. This process is called Transfer Learning.
- Since the dataset is imbalanced, we can try oversampling or undersampling to increase the dataset.
- Training the model with higher epochs and early stopping
- Try out different loss functions
- Monitor other evaluation metrics like Precision and Recall
Conclusion
With that, we come to the end of this project. Some of the key takeaways that you should have gathered include:
- What is computer vision and how it can be used to solve some daily issues faced by people?
- What is the difference between computer vision and image processing?
- What are the underlying technicalities that make computer vision work from a computer perspective?
- What tools are commonly used for computer vision?
- Walkthrough of a Fire Detection problem with computer vision.
- How does the CNN model work to implement Fire Detection?
- How we can improve our model to perform better?
Hope this article helped you understand the basics of Computer Vision and were successfully able to implement Fire detection using OpenCV. This is a vast ocean, and you can find multiple projects and ideas out there that have further deeper your knowledge and understanding of the concept of Computer Vision.
For this project, you can find the entire notebook on my Github.
Read the latest articles on our blog.
About the Author
Saniya is a final year Computer Science student studying at the University of Wollongong Dubai. She harbours a deep interest in Artificial Intelligence and Data Science. Check out her LinkedIn here
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.










Hi. I want to learn computer vision from basics. Currently am working in same domain but not in development. can you suggest me any books or blogs/sites for this