This article was published as a part of the Data Science Blogathon.
Introduction
Python is an excellent programming language for automating stuff. It contains many libraries that allow you to create awesome reusable code. One such library is python-docx.
This library is useful for a variety of document processing tasks, such as:
1. Adding heading
2. Reading paragraphs
3. Writing paragraphs
4. Adding image
5. Creating and saving document files
6. Finding and replacing text
7. Manipulating existing document file
8. Adding page breaks, and much more.
In this article, however, we will discuss one particular functionality of the Docx library in Python. We will create a python script in such a way that it will create as many data frames as the number of tables so that later these tables can be stored as separate files (can be CSV) and are handy for use. While the Python-Docx library can create and update Microsoft Word files, we will use it to –
1. Print each paragraph in the document.
2. Read all tables in the word document and convert them into data frames.
3. Print the word count of each paragraph and the overall word count of the document.
The documentation for the library is limited but further reading can be done through this link: https://python-docx.readthedocs.io/en/latest/
Understanding Data Frames
Before we begin with the actual code, we will discuss briefly the data frames. Data frames are two-dimensional tabular data structures. It is composed of rows and columns. It consists of heterogeneous elements. For example, if we consider an “employee” data frame. The columns can be “name”, “age”, “gender”, “salary”, “joining date”. The resultant structure of the above data frame is as follows –
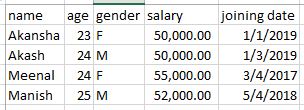
From the above figure, we see the heterogeneous components. Such as the name is string type data, age is numeric, gender is a character, salary is a double, and joining date is a date type field.
We can create a data frame using lists, dictionaries, or simply importing files. The majority of data analysis, data manipulation, extraction, etc., can be done after getting the data as data frames.
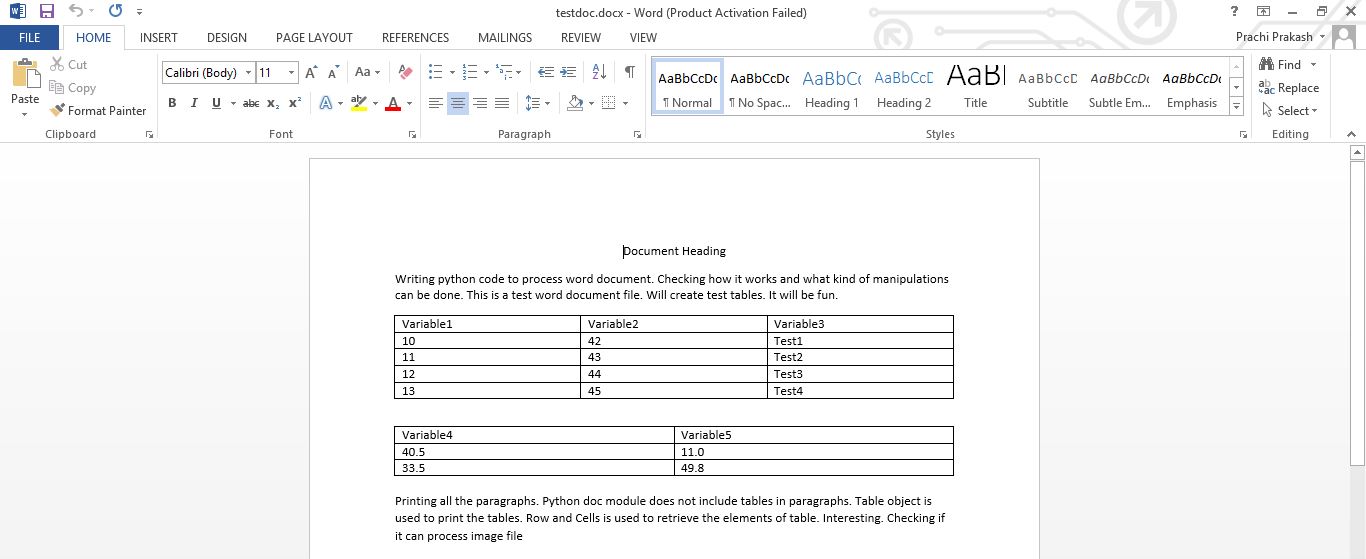
We will use the following document for coding, as shown below. This document contains two tables. Hence, our code will also create two data frames.
Understanding Functions in Python
The function is a collection of commands that perform a certain task. Functions avoid repetition and are a great way to create reusable components. It breaks the program into modules. It makes the code easier to manage and understand. Functions are written in Python using the keyword “def”. It is to be followed by the unique function name and passing arguments. A colon (:) marks the end of the function header. A function can be with or without a return statement. A return statement marks the exit of the function. And then control returns to the calling place. It depends on the nature of the task for which the function is written. We can call the function in another function or program using the function name. We can pass parameters if the function is defined to accept parameters.
In our article, we have defined a function named “create_df_from_table”. It accepts two arguments or parameters. They are “c” and “tab”. The first parameter is an integer whose value starts with 0. The second parameter is table output from “document. tables”.
Implementation
1. Importing libraries
We will use two libraries – Docx and pandas. Python-Docx is a python library that can process Microsoft word files. Pandas is a python library that is used to analyze the data.
import docx import pandas as pd
2. Reading the word document
Let us create a sample word document file with the name testdoc.docx. This document file contains a heading. There are two tables and two paragraphs. The first table has four rows and three columns, excluding the header row. The second table has two rows and two columns, excluding the header row. The “Document” object is used to read the Docx file.
document = docx.Document('testdoc.docx')
3. Printing paragraphs
There are two paragraphs in the document. The heading is also considered as one paragraph. Two tables present in the document are not seen as a paragraph in the Docx module. The two paragraphs along with the document heading are displayed when the below commands are run.
para_text_list = []
for each_par in the document.paragraphs:
print(each_par.text)
para_text_list.append(each_par.text)
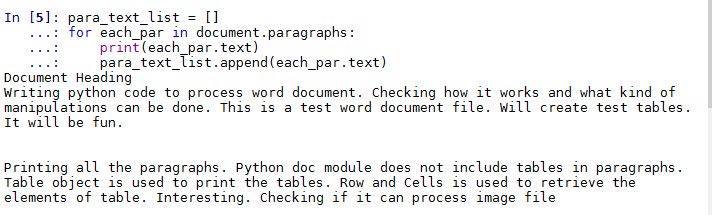
4. Creating data frame from the table
We will create a re-usable function to read the tables. Our function should be created in such a way that it finds all tables in the document and create separate data frames for all. In this definition, we assume that each table has a header. The first row will be treated as column names and the rest of them as row values. We will prefix our data frame names with “result_df_” and the count starts with 0. For example, if there are three tables in the word document, then the data frames names created are result_df_0, result_df_1, and result_df_2.
def create_df_from_table(c, tab):
list_name = str(c)+"_result_list"
list_name = []
for i,each_row in enumerate(each_tab.rows):
text = (each_cell.text for each_cell in each_row.cells)
if i == 0:
keys = tuple(text)
else:
each_dict_val = dict(zip(keys, text))
list_name.append(each_dict_val)
result_df = pd.DataFrame(list_name)
return result_df
for c, each_tab in enumerate(document.tables):
globals()[f'result_df_{c}'] = create_df_from_table(c, each_tab)
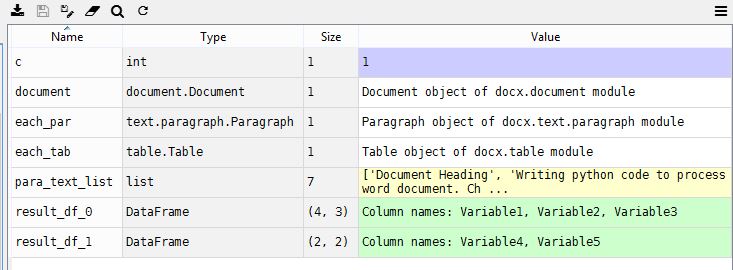
The two data frames created as shown below.
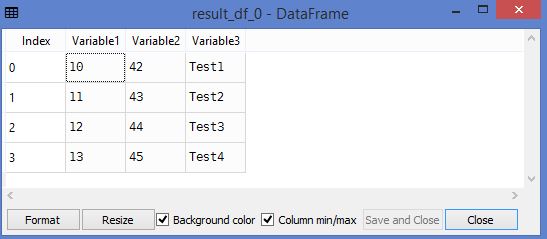
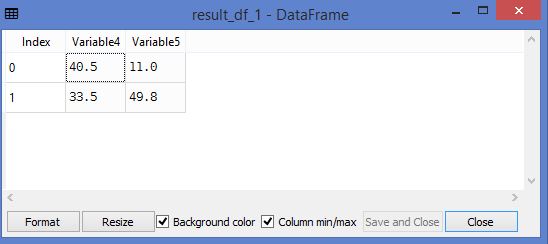
5. Reading word count of each paragraph and over word count
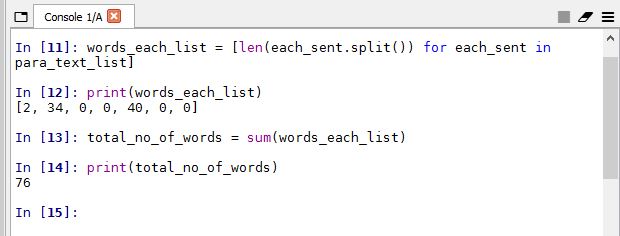
We will calculate the length of each section of the word document. “len” and “sum” function is used to find the word count.
words_each_list = [len(each_sent.split()) for each_sent in para_text_list] print(words_each_list) total_no_of_words = sum(words_each_list) print(total_no_of_words)
Advantages of Creating Re-Usable Codes
In this article, we have tried to create a code snippet that can work for any table in the word document. These are the potential benefits of creating re-usable codes –
1. Saves development time – Writing a snippet that can be integrated and used in another application leads to saving enough time for more critical development.
2. Provides structure – While all the automation codes can be placed in a single place, it gives developers a good look and understandability.
3. Decreased risk – When the code gets developed, it goes through a vulnerability check before deployment. These checks can easily be avoided.
4. Easy maintenance – It is easy to maintain the product. A fix in one place can lead to an overall fix for all the components that are interlinked to each other.
5. An efficient way of working – The functions can be kept at a central location and can be used as needed. This will make the program more modular and neat.
Conclusion
In this article,
1. We explored the Docx library –
a) Docx library can be installed in python using pip install python-docx.
b) Actions like saving the Docx file, adding paragraphs, highlighting phrases in the document, adding images in the document, adding a heading, changing font properties, etc., can be performed using the Docx module.
c) We created a re-usable function to convert all tables into data frames.
2. We created a brief understanding of data frames.
3. Discussed the importance of writing re-usable codes.
Read more articles on our blog.
Images source: Author
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.







It was so helpful! Thanks a lot!