This article was published as a part of the Data Science Blogathon.
Introduction
Modern applications and products deal with large amounts of data. The quantity of data being processed and utilised in modern times is enormous. So, the question arises? How to manage large files and data.
Data size soon outgrows a machine’s storage limit as data velocity increases. Data might be stored over a network of machines as a solution. Distributed file systems are the name for these types of filesystems. Data is stored over a network, introducing all of the network’s problems.
This is where Hadoop enters the picture. It has one of the most stable file systems available. HDFS (Hadoop Distributed File System) is a one-of-a-kind file system that stores enormously big files and allows for streaming data access on commodity hardware.
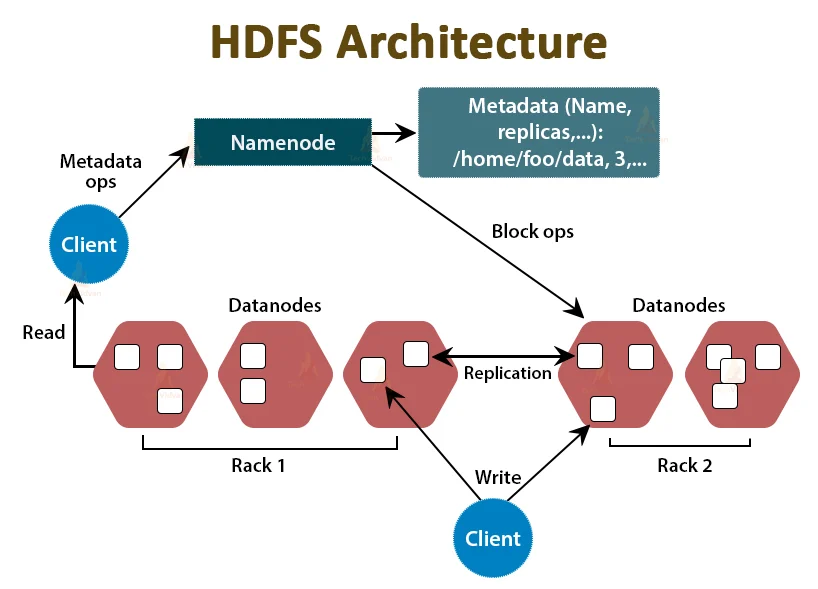
Image: techvidvan.com
What is HDFS?
The Hadoop Distributed File System is a fault-tolerant data storage file system that works on standard hardware. It was created to solve problems that conventional databases couldn’t. As a result, its full potential is only realised when dealing with large amounts of data.
HDFS can store a lot of data and make it easy to retrieve. The files are spread over numerous machines in order to store such large amounts of data. These files are duplicated to protect the system from data loss in the event of a system failure. HDFS also enables parallel processing of applications.
Some Features of HDFS are as Follows
- It’s ideal for storing and processing in a distributed environment.
- To communicate with HDFS, Hadoop provides a command interface.
- The name node and data node built-in servers make it simple for users to monitor the status of the cluster.
- Data from the file system is accessed in real-time.
- File permissions and authentication are provided by HDFS.
How does HDFS Store Data?
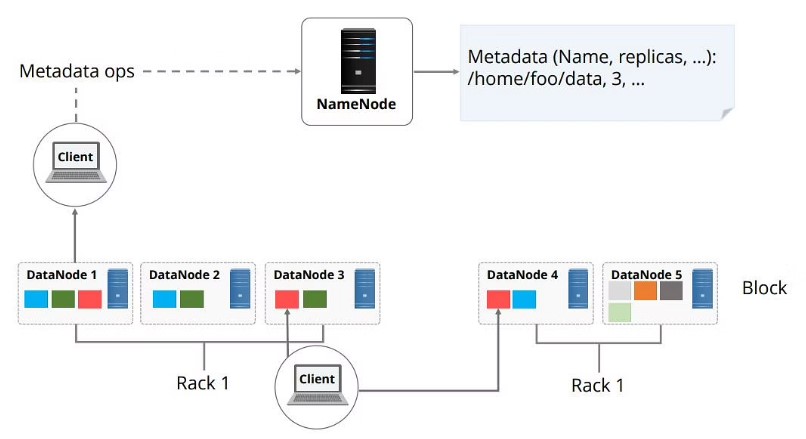
HDFS separates files into blocks, which are then stored on DataNodes. The NameNode, the cluster’s master node, is connected to several DataNodes. These data blocks are replicated across the cluster by the master node. It also tells the user where to get the information they’re looking for. However, before NameNode can assist you with data storage and management, the file must first be partitioned into smaller, more manageable data blocks. This is known as data block splitting.
Why should we Use HDFS?
- Fast recovery from hardware problems — a cluster of HDFS servers may ultimately fail, but HDFS is designed to detect a failure and recover on its own.
- Streaming data access — HDFS is designed for high data throughput, making it ideal for streaming data access.
- Large data sets – HDFS expands to hundreds of nodes in a single cluster and delivers high aggregate data capacity for applications with gigabytes to terabytes of data.
- HDFS is portable across hardware platforms and works with a variety of underlying operating systems.
What are Blocks?
The smallest quantity of data it can read or write is called a block. The default size of HDFS blocks is 128 MB, although this can be changed. HDFS files are divided into block-sized portions and stored as separate units. Unlike a file system, if a file in HDFS is less than the block size, it does not take up the entire block size; for example, a 5 MB file saved in HDFS with a block size of 128 MB takes up just 5 MB of space. The HDFS block size is big solely to reduce search costs.
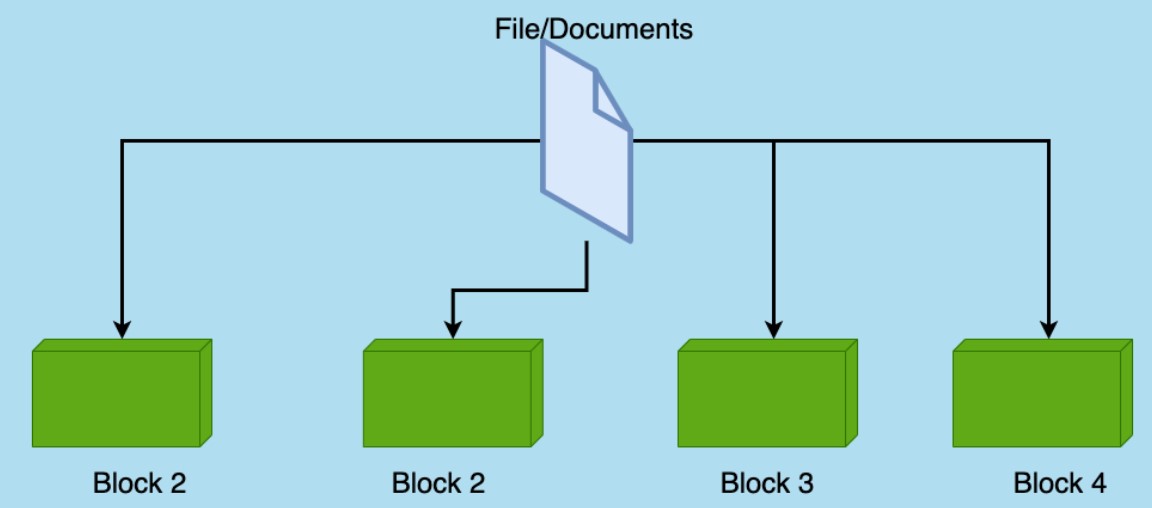
Image: nitendratech.com
What is the Replication Method for HDFS Blocks?
The block size and replication factor in HDFS may be customised per file. The number of replicas can be set up programmatically by an application. It can be supplied at the time of file creation and altered later if necessary. Name Node is in charge of determining the block size. HDFS makes two copies of the data in the same rack and the third copy in a separate rack using a rack-aware replica placement strategy.
The default block size in HDFS is 64 MB for Hadoop 1.1x and 128 MB for Hadoop 2.x and above. Depending on the cluster’s size, this block size can be changed. HDFS blocks are larger than disc blocks, primarily to reduce seek costs. The default replication size in an older version of Hadoop is three, which implies that each block is duplicated three times and stored on various nodes.
NameNode
NameNode can be regarded as the system’s master. It keeps track of the file system tree and metadata for all of the system’s files and folders. Metadata information is stored in two files: ‘Namespace image’ and ‘edit log.’ Namenode is aware of all data nodes carrying data blocks for a particular file, but it does not keep track of block positions. When the system starts, this information is rebuilt from data nodes each time.
Name Node is the HDFS controller and manager since it is aware of the state and metadata of all HDFS files, including file permissions, names, and block locations. Because the metadata is tiny, it is kept in the memory of the name node, allowing for speedier data access. Furthermore, because the HDFS cluster is accessible by several customers at the same time, all of this data is processed by a single computer. It performs file system actions such as opening, shutting, renaming, and so on.
DataNode
The data node is a commodity computer with the GNU/Linux operating system and data node software installed. In a cluster, there will be a data node for each node (common hardware/system). These nodes are in charge of the system’s data storage.
Datanodes respond to client requests by performing read-write operations on file systems. They also carry out actions such as block creation, deletion, and replication in accordance with the name node’s instructions.
Relevance and Practicality of HDFS
- A 10 TB file is extremely tough to store on a single system. Even if we store, each read and write operation on the whole file will take a long time to complete. However, if we have numerous 128MB blocks, it becomes easier to do different read and write operations on them rather than doing so on the entire file at once. As a result, we partition the file to allow for quicker data access, reducing seek time.
- HDFS is a distributed file system (or distributed storage) that runs on commodity hardware and can manage massive amounts of data. You may extend a Hadoop cluster to hundreds or thousands of nodes using HDFS.
- HDFS data may be replicated from one HDFS service to another. To offer fault tolerance, data blocks are duplicated, and an application can define the number of replicas for a file. The replication factor can be set at the time of file creation and adjusted later. HDFS files are write-once and only have one writer at any one moment. Each DataNode in the cluster sends a Heartbeat and a Blockreport to the NameNode, which makes all choices on block replication.
Conclusion
Each HDFS cluster contains one name node that stores metadata information such as the filename and the location of the file’s content. The amount of files you may have in each cluster is limited by this one node. When dealing with millions of little files, as is the case with machine learning, this is a significant restriction.
HDFS takes data in any format, regardless of schema, optimises for high-bandwidth streaming, and expands to proven installations of 100PB and beyond. It was designed primarily for large-scale data processing tasks where scalability, flexibility, and performance are crucial.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Prateek is a dynamic professional with a strong foundation in Artificial Intelligence and Data Science, currently pursuing his PGP at Jio Institute. He holds a Bachelor's degree in Electrical Engineering and has hands-on experience as a System Engineer at TCS Digital, where he excelled in API management and data integration. Prateek also has a background in product marketing and analytics from his time with start-ups like AppleX and Milkie Way, Inc., where he was involved in growth campaigns and technical blog management. Recognized for his structured thinking and problem-solving abilities, he has received accolades like the Dr. Sudarshan Chakraborty Award for Best Student Performance. Fluent in multiple languages and passionate about technology, Prateek continues to expand his expertise in the rapidly evolving AI and tech landscape.






