This article was published as a part of the Data Science Blogathon.
Introduction
In this article, we are going to cover Spark SQL in Python. In the last article, we have already introduced Spark and its work and its role in Big data. If you haven’t checked it yet, please go to this link.
Spark is an in-memory distributed big data processing tool that has become the standard data processing tool in the field of Big data.
Spark is 100 times faster than traditional Hadoop’s Map-reduce due to in-memory processing in Spark. It is originally written in SCALA, but it also provides application development in Python and JAVA APIs.
Spark SQL is an inbuilt Spark module for structured data processing. It uses SQL or SQL-like dataframe API to query structured data inside Spark programs.
- It supports both global temporary views as well as temporary views. It uses a View Table and SQL query to aggregate and generate data.
- It supports a wide range of data types, ie. Parquet files, JSON and HIVE tables.
- Spark also optimizes the SQL queries we provide using Catalyst and Tungsten tools.
- Using it, we can Run our SQL queries.
- A view of data in Spark SQL is treated as a table.
In this article, we will first understand why we should use SparkSQL and how it gives us flexibility while working in Spark with Implementation.
This article was published as a part of the Data Science Blogathon.
Table of contents
Objective
- Importance and Features of Spark SQL
- Setting up Spark with Python
- Loading a data file as dataframe
- Running SQL queries and creating Views
- Creating Pandas UDF for columnar operations.
SparkSQL Features
Spark SQL is so feature-rich; SparkSQL supports a wide range of structured data like Hive Table, Pandas Dataframe, Parquet files, etc.
We can write data in a wide variety of Structure data formats using Spark SQL ie. Hive Table, Parquet, JSON etc.
Spark SQL leverage the Scalability and other advantages of the Spark RDD model.
Using connectors like JDBC or ODBC allows us to connect in a standard manner.
Spark SQL Optimization
The main goal of Spark SQL Optimization is to improve the SQL query run-time performance by reducing the query’s time and memory consumption, hence saving organizations time and money.
It supports both rule-based and cost-based query optimization.
- Catalyst- It is also known as the Catalyst Optimizer; it is a spark Built-in Query optimizer. We can add custom optimization techniques and features to it.
- Tungsten It is a cost-based query Optimizer that uses a Tree data structure to calculate the lowest cost path. It improves the CPU performance instead of IO.

Setup
We will be using Pandas to load the data into the dataframe. We can load pandas’ dataframe into Spark.
Installing Required packages need internet, so it’s advised to use any cloud notebook.
# Installing required packages
!pip install pyspark
!pip install findspark
!pip install pyarrow==1.0.0
!pip install pandas
!pip install numpy==1.19.5After installing all the required packages we need to set up environment variables for Spark.
import findspark
findspark.init()Initializing Spark Session
import pandas as pd
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSessionNote build Spark Context and Session
# Creating a spark context class
sc = SparkContext()# Creating a spark session
spark = SparkSession
.builder
.appName("Python Spark DataFrames basic example")
.config("spark.some.config.option", "some-value")
.getOrCreate()Running the command spark returns the information of Running Spark Instance.
Loading the Data and Creating Table View
In this section, we will first read a CSV file into the pandas dataframe and read it into the spark dataframe.
To create a Spark data frame we are simply converting the pandas dataframe into a Spark dataframe.
# Reading the file using `read_csv` function in pandas
mtcars = pd.read_csv('https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBM-BD0225EN-SkillsNetwork/labs/data/mtcars.csv')mtcars.head()
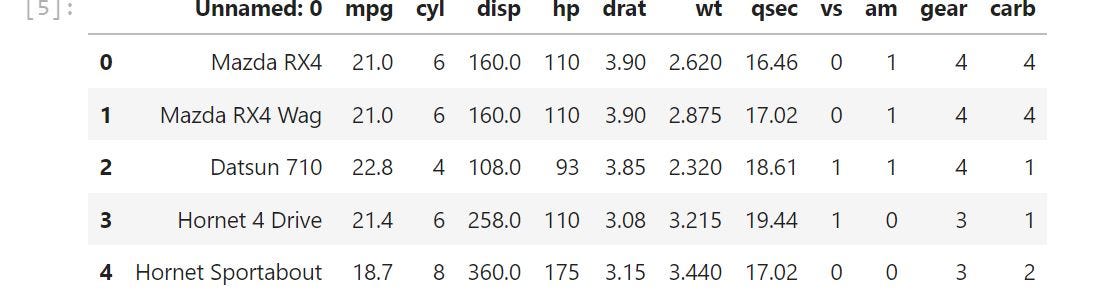
Renaming the column “Unnamed”
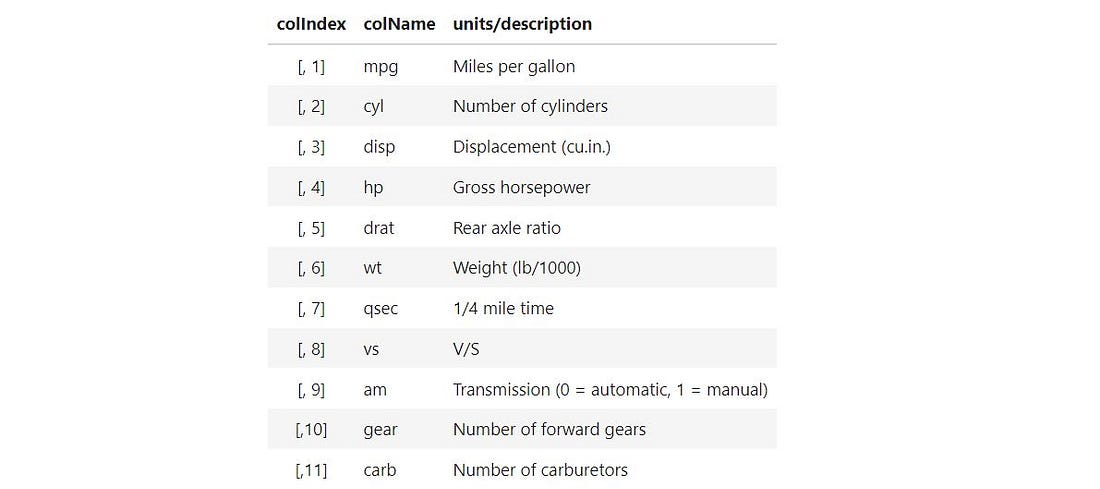
mtcars.rename( columns={'Unnamed: 0':'name'}, inplace=True )The dataframe consists of 32 observations (rows ) on 11 variables.
Loading the Dataframe into Spark
We use the createDataFrame function to load the data into the spark dataframe.
sdf = spark.createDataFrame(mtcars)Printing Schema of the loaded spark dataframe

Creating Table View
The table view is required for Spark SQL to run queries. The table view is treated as a SQL table.
There are two ways we can create a Table View.
- Temporary view
- Global-View
A temporary view persists in the local scope within the current spark session. Using the function createTempView() we can create a temporary table view.
sdf.createTempView("cars")After Creating a View we can treat cars as a SQL table in Spark.
Running SQL Queries and Data Aggregation
After creating a table view we can run queries similar to querying a SQL table.
- Showing the whole table
spark.sql("SELECT * FROM cars").show()- Selecting a Specific Table
# Showing a specific column
spark.sql("SELECT mpg FROM cars").show(5)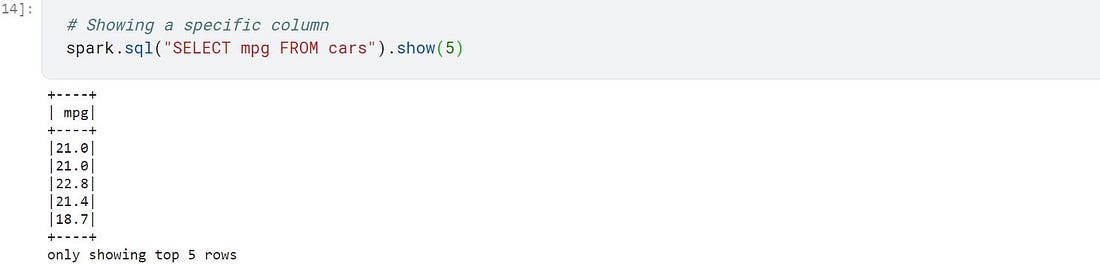
- Basic SQL filtering
#Basic filtering query to determine cards that have a high mileage and low cylinder count
spark.sql ("SELECT* FROM cars where mpg>20 AND cycl<6"). show(5)
- Aggregation
#Aggregating data and grouping by cylinders
spark.sql ("SELECT count (*), cyl from cars GROUP BY cal").show()
Querying all the cars having their Name starts with “Merc”
spark.sql("SELECT * FROM cars where name like 'Merc%'").show()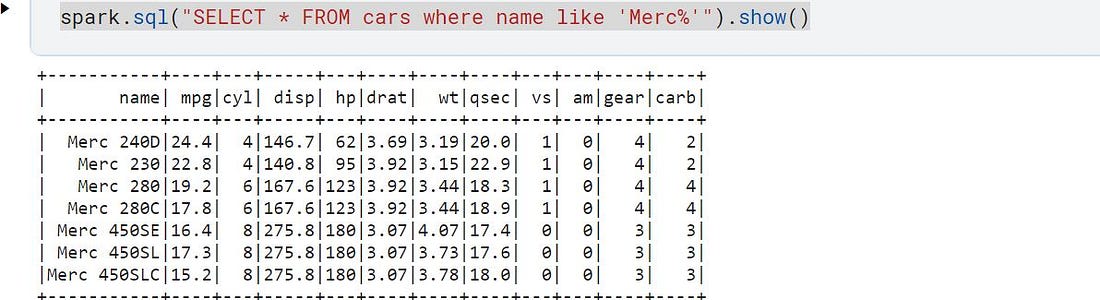
Padas UDF in Spark
User-Defined Function (UDF) acts on one row at a time, and because of this it suffers high serialization thus many data pipelines use UDF for data processing calculation tasks.
By registering a regular python function using the @padas_udf() decorator becomes a UDF.
It can be applied on Spark dataframe as well as in Spark SQL.
Importing libraries
# import the Pandas UDF function
from pyspark.sql.functions import pandas_udf, PandasUDFTypeCreating a UDF
@pandas_udf("float")
def convert_wt(s: pd.Series) -> pd.Series:
# conversion from imperial to metric tons
return s * 0.45spark.udf.register("convert_weight", convert_wt)Creating a UDF for converting mileage ( miles per liter) to kmpl( kilometer per liter)
@pandas_udf("float")
def convert_mileage(s:pd.Series) -> pd.Series:
return s*0.425# Registering UDF in Spark
spark.udf.register("convert_mileage", convert_mileage)spark.udf.register()makes a pandas udf available in Spark.- convert function takes a pandas series
sas input and returns a series as output. convert_weigthIt will convert imperial weight to metric tons by multiplying it by 0.45.
Applying the UDF to the table view
Now we can use convert_weight udf in our spark SQL or Spark dataframe.We can create a more complex udf according to our calculations.
spark.sql("SELECT *, wt AS imperial_weight , convert_weight(wt) as weight_metric FROM cars").show()Spark Sql Functions
SparkSQL functions are tools provided by Apache Spark for working with structured data in SparkSQL. They help you perform tasks like adding numbers, changing text, and working with dates in your data. They make it easier to analyze and process big datasets using SQL commands in Spark.
Conclusion
In this article, we have discussed how to Load the data in Spark and how to perform queries with SparkSQL. Spark has now been a standard data processing tool because of its in-memory architecture that makes it faster than Hadoop map-reduce.
Spark SQL is so feature-rich, It provides:
- Unified Data Acess
- Scalability
- Integration
- High Compatibility
In this article, we have learned to work with Spark SQL and data processing in Spark SQL. Spark also provides datasets that are only available in JAVA and SCALA APIs. In the next article, we will learn machine learning with Spark in Python.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A data enthusiast exploring the leading technologies related to the data






