This article was published as a part of the Data Science Blogathon.
Introduction to Big Data File Formats
In the digital era, every day we generate thousands of terabytes of data. The most challenging task is to store and process this data. These data are generated from different sources like social media, web applications, cell phones, sensors, bank transactions, etc.
The structure of data differs in nature. Some data are structured, while others may be unstructured or semi-structured. So, to store them we need a huge storage area that can handle a variety of data. We need appropriate file formats to store these data so, that we can get some useful insight from these data.
In this article, we are going to discuss different file formats that we use to store the data in our storage area.
Benefits of Using the Appropriate Big Data File Formats
The cost to store the Big data is more in some technologies. For example, Hadoop creates replicas of files to achieve fault tolerance. While accessing files needs CPUs and other resources which is costly in nature. As our data get increased the storage and accessing cost also increases along with that.
The benefits of using an appropriate file format are
- The data Reading from storage becomes faster.
- The data writing becomes faster.
- Splittable in nature to support parallelism.
- The compression support helps in file size reduction.
- Support of schema evolution.
- Cost reduction.
Every file format is designed by keeping some specific data characteristics and optimization techniques in mind. Like Text file format is easy to use but can’t be used for storing large amounts of data.
AVRO File Format

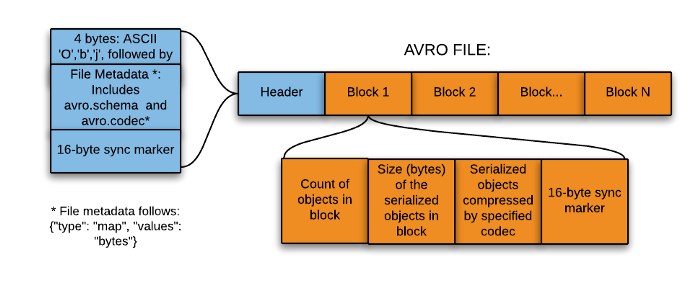
AVRO is an open-source project and it provides the data serialization and exchange services for Apache Hadoop.
It is a row-based storage format for Hadoop systems and is used as a data serialization platform.
It stores schema in JSON format, making it easy to read and interpret.
In AVRO the data is stored in binary format so, it is compact and efficient.
AVRO files have markers that help in splitting the larger datasets into smaller subsets that help to achieve parallelism.
The key feature of AVRO is it can efficiently handle any change in data schema over time. i.e. Schema Evolution. It handles schema changes like missing fields, added fields, and changed fields.
It also provides API support for the different programming languages like C, C++, Java, Python, Ruby, etc.
PARQUET File Format

Parquet is an open-source file format. It stores data in a columnar format. It provides great data compression and encoding schemes with enhanced performance to handle complex data in bulk.
Parquet is a binary file and contains metadata about its content. The metadata of the column is stored at the end of the file. It is optimized for the paradigm of Write Once Read Many (WORM).
It supports the splitting of files which helps in the parallel data processing.
Organizing by column, allows better compression, as data is more homogeneous.
It also supports schema evolution.
It’s only restricted to batch processing.
It provides high efficiency for OLAP workload. For example, the Analysis of data in BI (Business Intelligence) works.
With the help of Spark processing engines, it can read the data in less time.
It is mostly used along with Spark, Impala, Arrow, and Drill.
What are Row and Columnar Storage Formats?
In our day-to-day use case, the data that we see are mostly in rows format rather than in column format because searching and updating the records in this format is easier when data is small in size. But when our data is huge then the cost associated with searching, modifying, or deleting a record is quite a time taking process. To deal with this problem we use a columnar storage format.
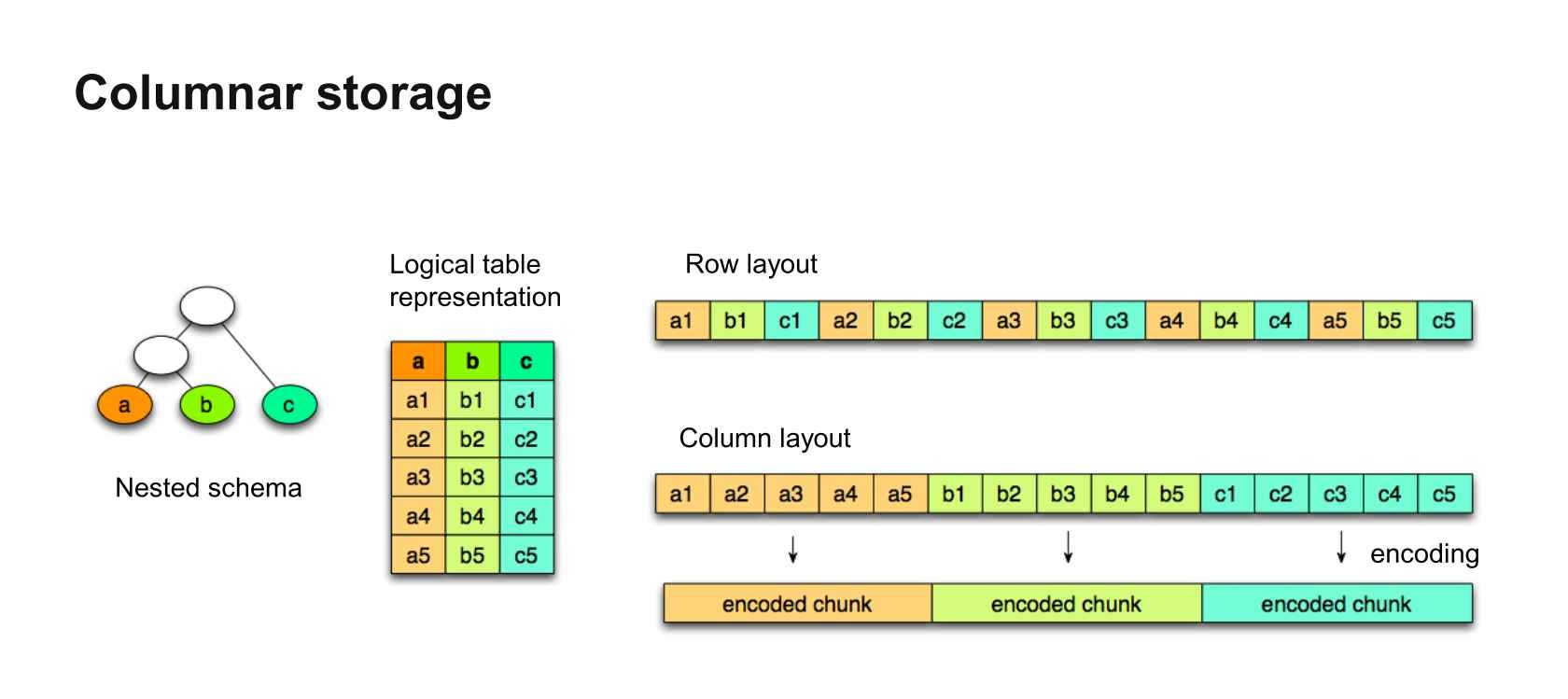
Suppose you have a huge data with 200 columns and you want to update only one column then the columnar storage format will be more efficient in this case. In rows format, it will load the whole data and then try to find the column and record where modification is needed. While in the columnar storage format it will read only the needed columns and update your data in that particular column as per your need.
So, the columnar format increases the performance of your query. The cost and time associated with searching, modification and deletion of records will reduce.
Let’s see some examples for a better understanding:
The below table contains three fields Id(Int), Name (Varchar), and Department (Varchar).
| Id | Name | Department |
| 1 | Emp1 | Dept1 |
| 2 | Emp2 | Dept2 |
| 3 | Emp3 | Dept3 |
Now the above data in the row wise-format first store all the data present in the first row and then repeat the same for the other rows (2nd and 3rd), it will look like this:-
| 1 | Emp1 | Dept1 | 2 | Emp2 | Dept2 | 3 | Emp3 | Dept3 |
In columnar format the whole data present in the “Id” column gets stored, then the “Name” column data and finally it will store the data of the “Department” column.
| 1 | 2 | 3 | Emp1 | Emp2 | Emp3 | Dept1 | Dept2 | Dept3 |
In the Parquet file format, we can access the individual field from the nested fields without reading all the fields present in the nested structure.
ORC File Format

The Optimized Row Columnar( ORC) file format provides an effective way to store the data. Facebook was an early adopter of this format. It was designed in such a way that it can handle the limitations of other file formats. This file format stores the data in a compact manner and skips the irrelevant parts without the need for large, complex, or manually maintained indices. It addresses all of these issues.
It is a column-oriented data storage format same as Parquet.
The advantages of ORC file formats are:-
- The compression ratio is very high, it reduces the size of the original data by up to 75%.
- It generates a single file as output for each of the tasks, by doing this it reduces the load from the NameNodes.
- A concurrent read of the same file is possible with the help of RecordReaders.
- It has the ability to split the files without scanning the markers.
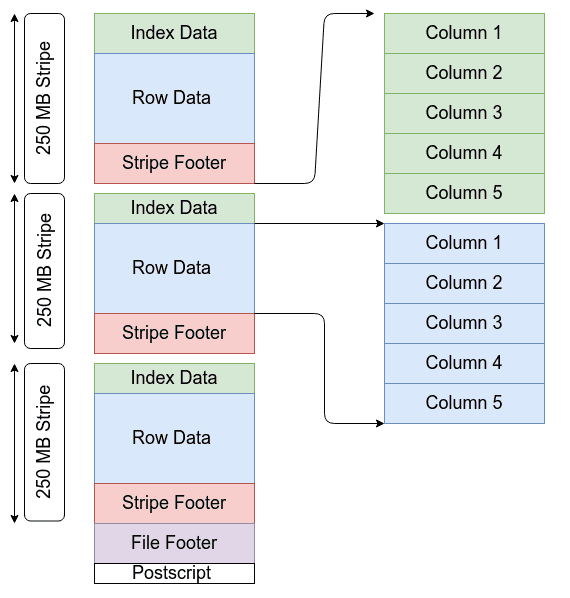
ORC files are self-describing and it has no dependency on Hive Metastore or any other external metadata. The file contains all the types and encoding information for objects that are stored in the file. Also, there is no dependency on the user’s environment for correctly interpreting the file contents.
It contains groups of row data called stripes and auxiliary information in a file footer. The default stripe size is 250 MB. A larger stripe size helps in the effective reading of data from HDFS.
It provides three levels of indexing with each file:-
- File-level – ORC provides the statistics about the values in each column across the entire file.
- Stripe level – It provides statistics about the values in each column for each stripe.
- Row-level – In this, it provides the statistics about the values in each column for each set of 10,000 rows within a stripe.
Conclusion
In this article, we have discussed different types of file formats that we used to handle the data. The selection of a particular file format is use case-dependent. For OLTP, the row-based file format is most suited while for OLAP, the column-based file format. The reduction in file size is more in columnar format. So choose your file format wisely.
The key learnings from this article are:-
- The need for different file formats.
- Different types of file formats.
- Rows vs Columnar based storage format.
- Handling of unstructured data in different file formats.
- The need to partition the files.
I hope this article helps you to understand the file formats. If you have any opinions or questions, then comment down below. Connect with me on LinkedIn for further discussion.
Happy Learning!!!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hello 👋,
I am a Data Engineer with a proven track record of working in the information technology and services industry. I am skilled in Apache Spark, Hive, SQL, Python, Hadoop, Databricks and Cloud.







Wow! Thank You Kishan for such a great Blog. This Actually helped me to revise the topic quickly!