This article was published as a part of the Data Science Blogathon.
Introduction
Every day the internet generates billions of bytes of data. Every time you put on a dog filter, watch cat videos or order food from your favourite restaurant, you generate data. Imagine how much data millions of other people are doing the same things every hour and day must be generating. A lot of data, right, terabytes and petabytes of data. This is called big data. Sometimes it becomes imperative to collect and analyse user-generated data to provide better services. But handling this amount of data is easy; we essentially need highly efficient technologies to manage and analyse this amount of data. This article will briefly discuss tools that help store, maintain, and analyse big data.
Any Big data handling process can roughly be divided into four layers, each with its tools. These layers are:
- Data Ingestion
- Data Storage
- Resource Management
- Data Processing and analysis
- Data Access
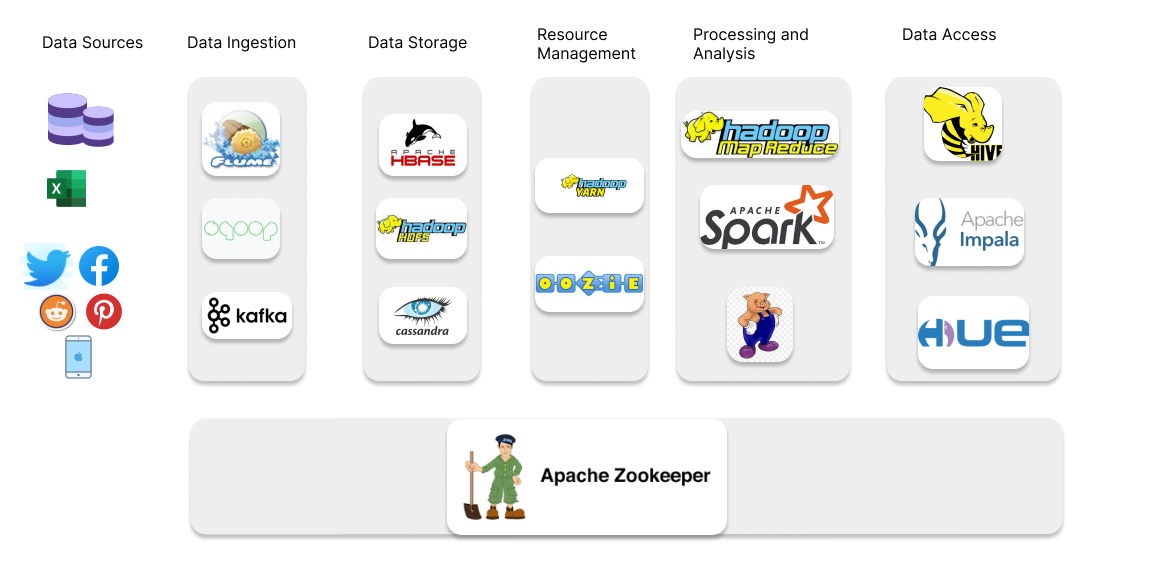
Before getting to the above topics, first, let’s understand Hadoop?
What is Hadoop?
Suppose you run a business, and every day you need to store and process gigabytes of data. You have a single storage unit powered by a relational database system to do that. Now imagine what can go wrong with this setup?
- Scalability – The entire system can not scale as and when needed, and we can not add new hardware to the existing without downtime. And the cost of adding specialised memory and CPU could be too expensive.
- Fault Tolerance – If the system is compromised, maybe because of a malicious attack or natural calamity, we could lose all the valuable data worth millions.
- Convenience – Bringing a vast amount of data to process and find patterns could be very difficult.
- Unstructured Data – Major chunk of data needed by businesses is undeveloped. Traditional RDBMS are technically incapable of processing unstructured data.
The answer to everything mentioned above is Hadoop, developed by Doug Cutting and Mike Cafarella. The core principle of Hadoop is to divide and distribute data to various nodes in a cluster, and these nodes carry out further processing of data. The job tracker schedules jobs on these nodes, and when it is done, the output is returned.
The core components of Hadoop are HDFS, YARN, and Map Reduce. To facilitate the entire Big Data process, we also have other libraries and software packages installed with or on top of core components, and these components are interdependent.
Data Ingestion
Data ingestion is the first layer of Big Data Architecture. The data is generated from various sources such as social media. Sensors, IoT devices, and SaaS platforms need to be collected and brought to a single warehouse or a database. There are three types of data ingestion techniques.
- Real-time: When the data is very time-sensitive. For example, data from a power grid needs to be monitored from time to time.
- Batch Ingestion: It is useful when the data is required at regular intervals.
- Lambda: This is the hybrid of both Real-time and batch.
Primary tools used for data ingestion are Flume, Sqoop and Kafka.
Flume
Flume is a data ingestion tool to collect, aggregate and transfer vast amounts of data from one source to another. The data generated from various sources are often required to be written on HDFS, Hbase. Flume acts as a middleman to facilitate seamless, convenient writing of data from sources to the storage systems like HBase and HDFS. It can collect data in real-time as well as batch. It is reliable, scalable, extensible, fault-tolerant, manageable, and customisable.
Sqoop
Apache Sqoop is another data ingestion tool that mainly works with relational databases. We might need to transfer structured data from different sources to HDFS, where we use Sqoop. It can efficiently work with almost all SQL databases like MySQL, Postgre, SQLite etc. It has two primary operations, import and export, and it can import data and export data to other sources.
Kafka
Kafka is another open-source tool designed to build real-time data pipelines and streaming applications. Kafka is also often used as a message broker solution, a platform that processes and mediates communication between two applications.
Data Storage
This is the backbone of Big Data Architecture. The ability to store petabytes of data efficiently makes the entire Hadoop system important. The primary data storage component in Hadoop is HDFS. And we have other services like Hbase and Cassandra that adds more features to the existing system.
HDFS
HDFS stands for Hadoop Distributed File System, and it is designed to run on commodity servers. A typical HDFS architecture consists of a Name node and several data nodes. Nodes can be thought up as a single computer, and a collection of nodes constitute a cluster, and each cluster could boast 1000s of nodes.
When HDFS receives data, it converts the data file into small chunks of data, mostly 64 or 128 MB. The chunk size depends on the system configuration. While partitioning and replicating the data, HDFS follows a principle called rack awareness. A rack is a collection of 40-50 data nodes. Each copy of chunked data gets stored in different racks, thus making it highly fault-tolerant.
HDFS follows a master-slave architecture for data processing. The master node is also called the Name node, while the data nodes are secondary. The master server or the Name node manages the file system namespace and regulates access to files by clients. The data nodes contain the storage attached to the node and execute read and write operations from file system clients. Also, they are responsible for the deletion, replication and block creation upon request from the Name node.
The entire process can be summed up in the below picture
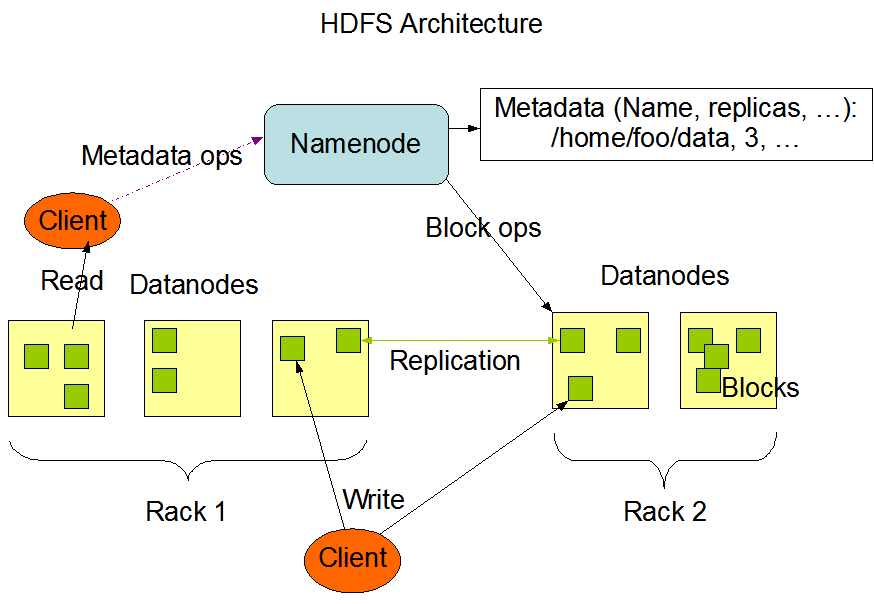
The master-slave architecture has one critical weakness: the cluster operation will halt if the Name node or Master node is compromised.
HBase
We discussed HDFS, and now we will move on to HBase, a column-oriented non-relational database management system that runs on top of HDFS. It operates similarly to HDFS; it has a master node to manage clusters, and slave nodes or region servers store the portion of the table and perform read and write operations. It has a unique concept of clubbing columns into a column family. These column families can be changed as and when needed making them flexible to changing application requirements. It is ideal for analysing real-time data and random read-write access to voluminous data.
Cassandra
Cassandra is a non-relational database management system ideal for semi-structured data, though it can work with structured and unstructured data except for image data. The Cassandra follows a masterless or peer-peer architecture, making it almost invincible to failure, unlike HDFS, which can go down if the master server goes down. It has a unique ability to read/write data on nodes available in an entirely different geography, which makes it ideal for companies with a user base spanning across the globe; on top of that, it provides high fault tolerance.
Resource Management
Resource management is one of the critical concepts of Big Data architecture. After all, the optimum use of resources will fetch us optimum performance. Hadoop depends on YARN for resource management, and it is also one of the core components of the Hadoop ecosystem.
YARN
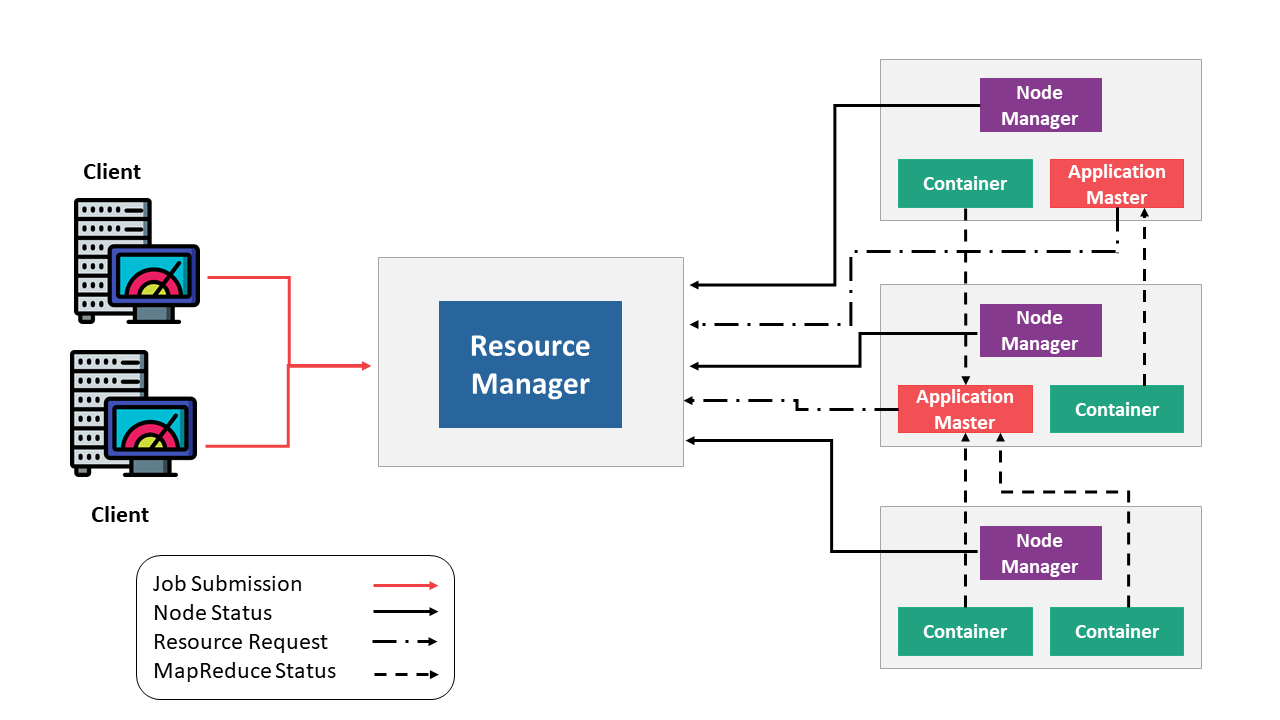
YARN stands for Yet Another Resource Negotiator. In Hadoop 1.0, map-reduce was responsible for processing and job tracking tasks. But the utilisation of resources turned out to be highly inefficient. Then came YARN which took over the task of resource distribution and job scheduling from map-reduce. The YARN now sits in the middle of HDFS and map-reduce. There are four critical components in YARN.
- Resource Manager: The master node is chiefly responsible for resource allocation and directing Node managers to perform real processing. A scheduler is responsible for scheduling jobs, and resource distribution and an Application manager takes care of the job submissions and is accountable for running application masters in a cluster.
- Node Manager: A node manager runs a slave daemon. It is responsible for running assigned jobs on each node. It periodically sends heartbeats to signal the active status of the respective nodes.
- Application Masters: It negotiates resources from Resource Manager and coordinates with node managers to execute tasks.
- Containers: Containers are the hardware resources available in a cluster, such as CPUs, RAMs, disk space etc. It grants access to applications to use specific amounts of resources.
Oozie
Apache OOzie is an open-source Java web application for workflow scheduling in a distributed cluster. It combines multiple jobs into a single unit, and Oozie supports various jobs from Hive, Map Reduce, pig etc. There are three types of Oozie jobs.
- Oozie Workflow jobs: These are Directed Acyclic Graphs (DAGs) which specify a sequence of actions to be executed.
- Oozie Coordinator jobs: These are recurrent Oozie Workflow jobs triggered by time and data availability.
- Oozie Bundle: It provides a way to package multiple coordinators and workflow jobs and manage the lifecycle of those jobs.
Data Processing and Analysis
This could be thought of as the nervous system of Big Data architecture. Map Reduce, another core component of Hadoop, is primarily responsible for data processing. We will also discuss other software libraries that take part in data processing and analysis tasks.
Map Reduce
Map Reduce is responsible for processing a huge amount of data in a parallel distributed manner. It has two different jobs: Map and the other is Reduce. Just as the name Map always proceeds to Reduce. The data is processed and converted into key-value pairs or tuples in the Map stage. the output of the map job is fed to the reducer as inputs. Before being sent to the reducer, the intermediate data is sorted and organised, and the reducer then aggregates the key-value pair to output a smaller set of outputs. Final data is then stored in HDFS.
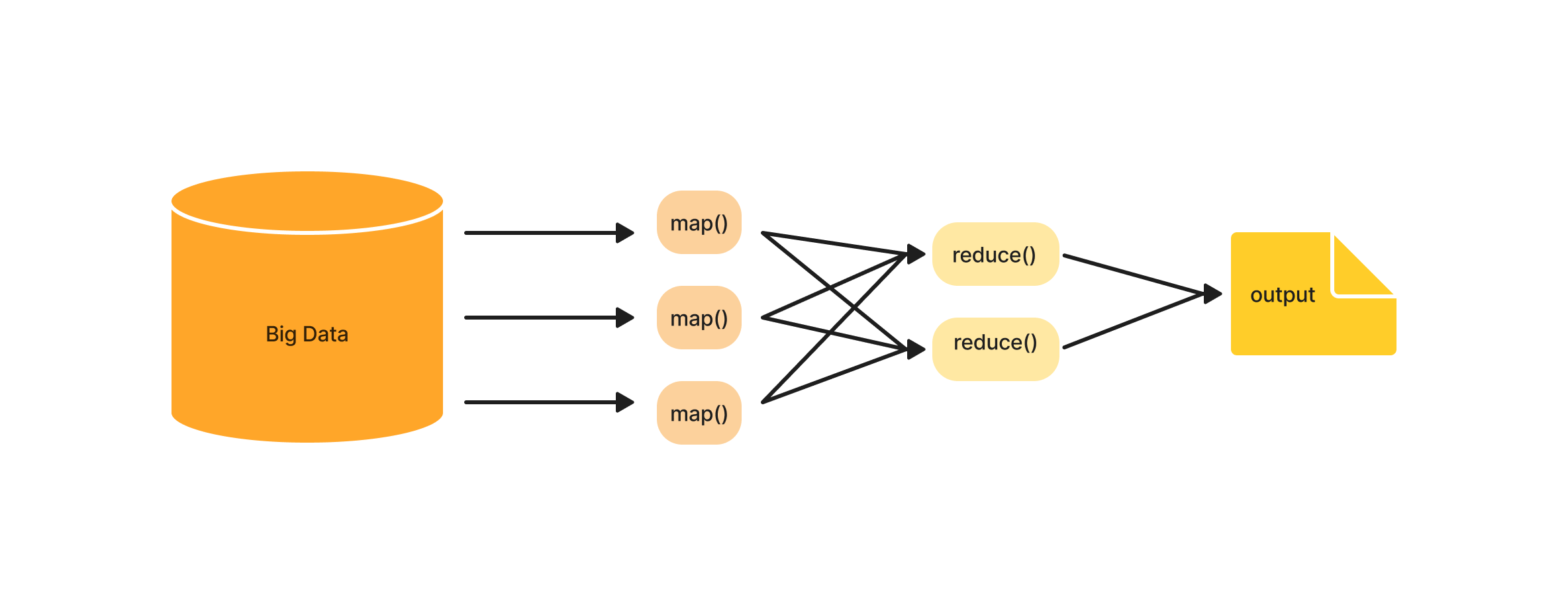
Just like HDFS, Map Reduce follows a master-slave design to accomplish tasks. Each Name node has a Job tracker, which divides and tracks the job submitted by the clients. Each job is then distributed among data nodes. These data nodes house task trackers, periodically sending a heartbeat indicating the node is alive. This way job tracker tracks the entire process. In case of a data node failure, the job tracker assigns the job to another node, thus making the system fault-tolerant.
.png)
Pig
Yahoo developed Apache Pig to analyse large amounts of data. This is what map-reduce does, too, but one fundamental problem with Map Reduce is it takes a lot of code to perform the intended jobs. This is the primary reason why Pig was developed. It has two significant components Pig Latin and Pig engine.
Pig Latin is a high-level language that is used to perform analysis tasks. 10 lines of Pig Latin code can achieve the same task as 200 lines of map-reduce code. The pig codes internally get converted to map-reduce jobs with the help of the pig engine. Thus making the entire process easier. The Pig Latin language is similar to SQL.
Spark
One of the critical concerns with map-reduce was that it takes a sequential multi-step process to run a job, and it has to read cluster data to do the operation and write it back to nodes to perform a job. Thus, map-reduce jobs have high latency, making them inefficient for real-time analytics.
To overcome the shortcoming, Spark was developed. The key features that set Apache Spark apart from map-reduce are its in-memory computation capability and reusability of data across parallel operations. This makes it almost 100 times faster than Hadoop map-reduce for large scale data processing.
The Spark framework includes The spark core, Spark SQL, MLlib, streaming and Graphx.
- Spark Core: This is responsible for memory management, scheduling, distributing, monitoring jobs, and fault recovery. And it was interacting with storage systems. It can be accessed by different programming languages such as Java, Scala, Python and R via APIs.
- MLlib: Library consisting of machine algorithms to do regression, classification, clustering etc.
- Streaming: It helps ingest real-time data from sources such as Kafka, Twitter, and Flume in mini-batches and perform real-time analytics on the same using codes written for batch analytics.
- Spark SQL: Distributed querying engine that provides highly optimised queries up to 100x faster than map-reduce. It supports various data sources out-of-the-box including Hive, Cassandra, HDFS etc.
- Graphx: It is a distributed graph processing unit that provides ETL, Graph computation and exploratory analysis at scale.
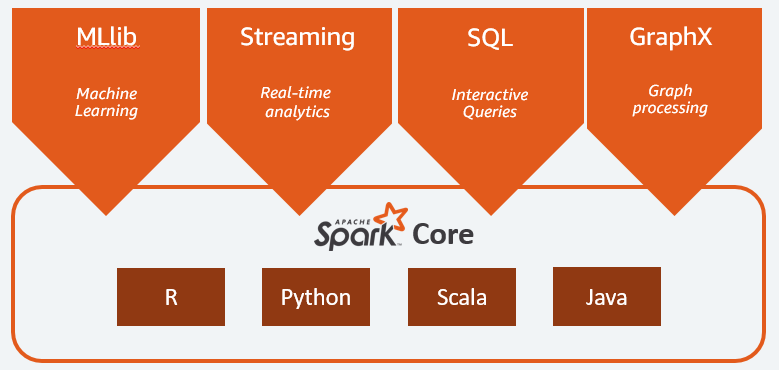
Source: Amazon AWS
Spark is an ecosystem in itself. It has its cluster manager called standalone manager, Spark SQL for accessing data, streaming for batch and real-time data processing etc. Honestly, it deserves an article in itself.
Data Access
Once the data is ingested from different sources and stored in cluster nodes, the next step is to retrieve the right data for our needs. There are a bunch of software that helps us access the data efficiently as and when needed.
Hive
Hive is a data warehousing tool designed to work with voluminous data, and it works on top of HDFS and Map Reduce. The Hive query language is similar to SQL, making it user-friendly. The hive queries internally get converted into map-reduce or spark jobs which run on Hadoop’s distributed node cluster.
Impala
Apache Impala is an open-source data warehouse tool for querying high volume data. Syntactically it is similar to HQL but provides highly optimised faster queries than Hive. Unlike Hive, it is not dependent on map-reduce; instead, it has its engine, which stores intermediate results in memory, thus providing faster query execution. It can easily be integrated with HDFS, Hbase and amazon s3. AS Impala is similar to SQL, and the learning curve is not very steep.
Hue
Apache Hue is an open-source web interface for Hadoop components developed by Cloudera. It provides an easy interface to interact with Hive data stores, manage HDFS files and directories, and track map-reduce jobs and Oozie workflows. If you are not a fan of Command Line Interface, this is the right tool to interact with various Hadoop components.
Zookeeper
Apache zookeeper is another essential member of the Hadoop family, responsible for cross node synchronisation and coordination. Hadoop applications may need cross-cluster services; deploying Zookeeper takes care of this issue. Applications create a znode within Zookeeper; applications can synchronise their tasks across the distributed cluster by updating their status in the znode. Zookeeper then can relegate information regarding a specific node’s status change to other nodes.
Conclusion
So, in this article, we took a glance at different layers of the Big data ecosystem and explored brief tools and frameworks to deal with Big data at each stage. The entire article can be summarised below:
- Apache Flume and Sqoop are responsible for data ingestion into HDFS.
- HDFS is the de facto file system in Hadoop and Hbase, a non-relational column-oriented database that runs on top of HDFS. At the same time, Cassandra is a NoSQL database management system with lower latency and zero points of failure.
- YARN is a Hadoop core component that is responsible for resource management. Oozie is another software that helps multiple coordinate jobs.
- MapReduce is the centre of Hadoop processing which maps, shuffles, and reduces jobs into smaller outputs. Spark is another alternative to MapReduce, which uses in-memory computation to achieve faster outcomes.
- Hive, Hue and Impala etc., are responsible for querying required data for analysis.
This was all about the Big Data ecosystem. I hope you enjoyed my article on the Hadoop ecosystem.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Meet your author Sunil kumar Dash, a developer and a writer. Has diverse interests in tech, pop culture, wellness, philosophy and Anime. Exploring underrated music is his hobby. And loves to doom scroll Twitter when bored.







I really liked the article