This article was published as a part of the Data Science Blogathon.
Introduction on Apache HBase
With the constant increment of structured data, it is getting difficult to efficiently store and process the petabytes of data. Apache HBase is a column-oriented, open-source NoSQL database, part of the Big data technology stack. To provide a massive amount of storage and accountable processing, it utilizes the Hadoop distributed files system (HDFS). Being a highly scalable database in the Hadoop cluster increases the efficiency of structured data. HBase is Hadoop’s most reliable database option while implementing the business domains such as web and Internet, sports, e-commerce, healthcare, Bank, and insurance for data analytics.
Some MNCs like Facebook, Twitter, Netflix, Yahoo, Adobe, and Pinterest utilize it to process high-volume data running up to 10 million tasks every second.
What is Apache HBase?
![]()
HBase is a data model modeled after Google’s Bigtable, a distributed database management system for structured data. HBase is a distributed open-source system developed by the Apache Foundation and written in Java. HBase is a necessary element of our Big Data’s Hadoop ecosystem and runs on top of HDFS (Hadoop Distributed File System). HBase is quite similar to Bigtable; Bigtable acted upon Google’s file system, and similarly, Hbase acted upon the HDFS. HBase is aimed to host huge tables with billions of columns and rows on top of clusters of commodity hardware and stores massive amounts of data from terabytes to petabytes. The popularity of HBase can be judged by the decision of Facebook to shift from Apache Cassandra to HBase in November 2010. HBase fulfilled Facebook’s requirements of building a highly robust and scalable infrastructure that can handle a variety of services like messages, chats, and email in a real-time conversation.
Apache HBase Features
Below are the significant features of HBase that fabricate it into one of the most useful databases for the present as well as the future industries:
-
Real-time, random ample data access: The internal data storage architecture used by HBase is Log-Structured Merge-tree (LSM-tree), which reduces the disk seeks by merging tiny files to the bigger files recurrently.
-
HDFS/Hadoop integration: HBase is highly capable of running on top of various other file systems, but HDFS is the best choice. The reason is that HDFS provides data distribution and high accessibility with the help of distributed Hadoop.
-
Automatic failover support and load sharing: HDFS is internally distributed and automatically recovered by using the multiple block allocation and replications, and as we know, HBase runs on the top of the HDFS, so HBase is retrieved automatically. With the help of HBase and RegionServer replication, the failover is also facilitated.
-
MapReduce: A built-in support of the Hadoop MapReduce framework is offered by HBase, which provides fast and parallel processing of stored data in HBase.
-
Automatic sharding: HBase table is composed of various regions handled by RegionServers. On different DataNodes, these regions are distributed throughout the RegionServers. Now, in order to reduce I/O time and overhead, HBase caters to the automatic and manual splitting of these multiple regions into smaller subregions once it reaches a threshold size.
-
Java API for client access: HBase offers easy development and programmatic access as it has solid Java API support (client/server).
-
Thrift gateway and RESTful web service: For non-Java front-ends, HBase not only supports Thrift and RESTful gateways but also web service gateways to enable accessing and working with HBase.
-
Distributed storage: HBase supports distributed storage as it works when used with HDFS. It establishes coordination with Hadoop and supports the distribution of tables, high availability, and consistency.
-
Linear scalability: A high scalability is supported by HBase in both linear and modular forms. By the term scaling, we emphasize scale-out, not scale-in, which means that we don’t have to focus on making servers more powerful instead, we need to add more machines to its cluster.
-
Column-oriented: Most relational databases are row-oriented and offer row-based storage, but HBase stores each column separately. So in HBase, columns are stored contiguously, which leads to faster data access and decreases memory usage.
-
Sparse, multidimensional, sorted map database: While using HBase, users don’t have to worry about the presence of thousands of null values or multiple values as HBase is a sorted map-based database that is suited for sparse and multidimensional data.
-
HBase shell support: HBase offers a full-fledged command-line tool to interact with HBase and perform simple operations like creating tables, adding data, scanning data, removing data, and many other administrative and non-administrative commands.
HBase Architecture and Components
HBase architecture consists mainly of five components
-
HMaster
-
HBase Regions
-
HRegion server
-
Zookeeper
-
HDFS

Let’s explore them one by one.
HMaster
HMaster is nothing but the implementation of Master Server in HBase. It is a lightweight process in which regions are assigned to the server region in the Hadoop cluster for the sake of load balancing. The roles and responsibilities of HMaster are:
-
Monitoring and the management of the Hadoop Cluster
-
Performing the Administration tasks(loading, balancing, creating, updating, and deleting data or tables)
-
Controlling the failover or load balancing
-
Handling the DDL operations on HBase tables.
-
HMaster takes the charges of schema or metadata modifications as per the client’s requests.
The client establishes a bi-directional communication with both HMaster as well as the ZooKeeper. For read and write operations, it contacts HRegion servers directly. HMaster assigns regions to the HRegion server and, in turn, checks the health status of the regional server.
HBase Regions
HBase Regions are the essential building elements of the Hadoop cluster that are comprised of Column families. It carries a separate store for each column family and consists of two major components, the Memstore and the HFile.
HRegionServer
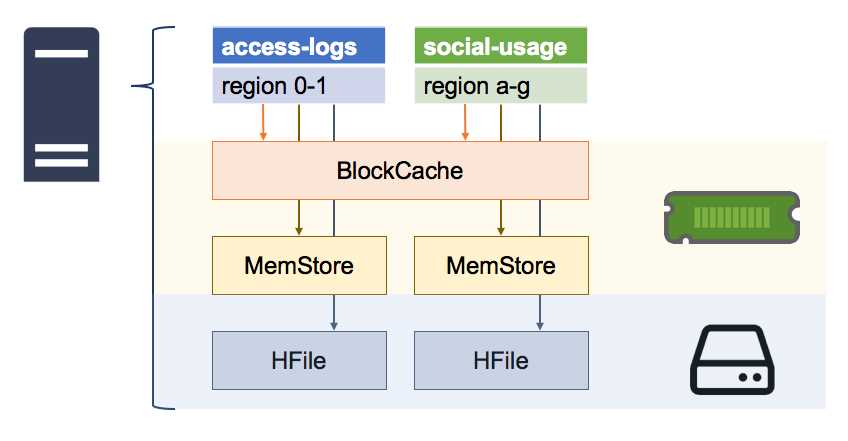
HBase Region Server acts as a worker node that handles the client’s request for reading, writing, updating, and deleting operations. The lightweight Region Server runs on all the HDFS nodes which are present in the Hadoop cluster. The components of the HBase Region Server include –
- Block Cache – Block cache acts as the read cache and stores the most frequently read data. The most recently used data gets evicted in case of block cache overflow.
-
MemStore– MemStore acts as the write cache and stores the latest data that is not yet written to the disk. MemStore is present in a region of every column family.
-
Write-Ahead Log (WAL)- WAL is a file that is used to store the latest data which is not persisted in permanent storage.
-
HFile- HFile is the original storage file that stores the rows as sorted key values on a disk.
The primary functions performed by the region server are:
- Save the data in areas and perform customer requests.
- Use the Auto-Sharding method to perform load balancing by distributing the HBase table dynamically when it becomes extensively large after data insertion.
Zookeeper
Zookeeper is an open-source project which acts as a coordinator in HBase. It offers facilities like server failure notification, naming, providing distributed synchronization, maintaining configuration information, etc. HMaster and HRegionServers register themselves with ZooKeeper, and if the client wishes to communicate, the Zookerpeer acts as a communication bridge across the architecture. In the HBase cluster, whenever a node failure occurs, ZKquoram is responsible for triggering the error message and starting the repairing of failed nodes. Zookeeper is responsible for keeping track of all region servers present in the cluster and storing their information, like how many region servers are available and which servers are carrying which DataNode. Hence, to get all these region server pieces of information, the HMaster contacts ZooKeeper. Zookeeper also offers many other services like –
- Establishing communication between client and region servers.
- Maintaining the Configuration Information
- Keeping track of server failure and network partitions.
- Provides ephemeral nodes that represent many region servers.
HDFS
HDFS(Hadoop Distributed File system) comes in contact with the HBase components in order to store a large volume of data in a distributed format. HDFS maintains the fault-tolerance by keeping each file in multiple blocks and replicating them across a Hadoop cluster. HDFS uses cheap commodity hardware and works with low-cost material to add nodes to the cluster and process them, giving the customer better results than the existing hardware.
Introduction to the HBase Shell Commands
To communicate with HBase, a very powerful tool is used called HBase Shell. The shell is built with the help of ruby programming language and supports both the Data Definition and Data Manipulation Language in it. Firstly, we have to install the HBase successfully over the Hadoop Eco-System then, only we can communicate with the HBase environment with the help of Java API and the HBase Shell.
How to Login to HBase Shell?
Step1:- Start a remote access client software such as putty, MobaXterm, Xserver, etc. I preferred putty to run HBase commands.
Step2:– Enter the HBase Server’s IP address and provide the login credentials like User ID and Password.
Step3:- After the successful user login, type “HBase shell” on the prompt and hit the enter button. And that’s it; if you are logged in as a user, it will take 2 to 3 minutes to start the HBase shell.
Command:-
HBase shell
Output

Types of HBase Shell Commands
There are three types of HBase Shell Commands supported by Hadoop:
- Informative Commands
- Data Definition Language
- Data Manipulation Language
Informative Commands
These are general commands that give information about the system and the user. The informative HBase commands are:
a. Version
This command provides us with information about the current version of HBase running in our system.
Command:-
Version
Output

b. Status
This command provides us with the status of the system and the information about the number of HBase Master, HBase Region Server, and HBase Servers running on the system.
Command:-
status
Output

c. Whoami
This command provides us the user information, including its user id and the group of users it belongs to.
Command:-
whoami
Output

d. table_help
This command helps us to understand how to use table-referenced commands in HBase.
Command:-
table_help
Output

Data Definition Language
DDL commands are the table management commands which are responsible for the definition and creation of database schema. The HBase DDL commands are:-
a. Create Table
With the help of creating a table command, we can specify a table by providing the table name and column family name.
Command:-
create 'school','sno','student_name','roll_no’
Output

b. List Table
This command provides us with a list of all the tables present in the HBase.
Command:-
list
Output

c. Describe Table
To get detailed information about the table, we use the describe command. It will provide information related to the column family.
Command:-
describe 'school'
Output

d. Disable Table
Whenever you want to delete or drop any table from the HBase Environment, you have to disable that first; otherwise, the table will never delete.
Command:-
disable 'school'
Output

e. Disable_all Table
Whenever you want to disable multiple tables matching a specific pattern or regular expression, then the disable_all command will help.
Command:-
Disable_all ‘school’
Output:

Explanation: In the above example, we disabled all the tables having the word ‘student’ in their filename.
f. Enable Table
The disabled table cannot perform any task. So first, we have to enable the tables to start working with them.
Command:-
enable 'school'
Output

g. Show_filters
There are many filters like DependentColumnFilter, KeyOnlyFilter, ColumnCountGetFilter, etc. are present in the HBase. The show_filter command of HBase shows us all these filters.
Command:-
show_filters
Output

h. Drop-Table
Drop command is used to drop or delete the disabled table of the HBase environment.
Command:-
disable ‘Shikha’ drop 'Shikha'
Output

i. Drop_all Table
Whenever we need to delete multiple tables at the same time and follow the regular expression, we use the ‘drop_all’ command just after the ‘disable_all’ command.
Command:-
Disable_all ‘shik_.*’ drop_all 'shik_.*'
Output

j. Is_enabled
Whenever you need to check whether your table is enabled or not, the ‘is_enable’ command is used. It will reflect true for the enabled tables.
Command:-
is_enabled 'school'
Output

k. Alter Table
Alter table command is used to modify the schema of the existing HBase table. For example, it will help to add or delete multiple column families in the HBase table.
Command:-
Alter ‘school’ NAME=’student_age’, VERSION=>5
Output

Data Manipulation Language
DML commands are responsible for manipulating or altering data stored in the database rather than changing the schema. The HBase DML commands are:
a. Count
As the name suggests, the count command is used to display the total number of rows present in the HBase table.
Command:-
count 'school'
Output

b. Scan
Whenever you need to test whether the input value is inserted correctly in the table or not, or you have to view the complete data, then you can simply write the scan command.
Command:-
scan 'school'
Output

c. Put
Put command is used to add or insert the data in an existing HBase table.
Command:-
put 'school' , '1', 'student_name:first_name', 'shikha'
Output

d. Get
To get the specific content of a particular table, we use the get command. It will help to read data from the database table and allow us to add time_stamp, time_range, filters, and version.
Command:-
get 'school' , '1', 'student_name'
Output

e. Delete
By specifying the specific row and column of the table, we can quickly delete the individual cell.
Command:-
delete 'school' , '1', 'student_name'
Output:

f. Delete all
We can delete all the cells from the particular row in the HBase table. Command:-
delete all 'school' , '2', 'student_name'
Output

g. Truncate
This command suits you the most whenever you are interested in deleting the table data instead of schema.
Command
truncate 'school'
Output

Difference Between HBase and RDBMS
Both the Apache HBase and the Relational Database Management System are data processing tools, but both are very different. Let’s see the feature-based differences between RDBMS and HBase!
-
Type of Database
As we know, HBase is a column-oriented non-relational database management system that defines each column as a contiguous unit of the page. In contrast, RDBMS is a row-oriented database management system.
-
Type of Schema
HBase provides a very flexible schema where you can add columns on a fly, whereas RDBMS offers a very restricted schema.
-
Handling Sparse Values
HBase holds very strong management to handle the multiple null values, whereas RDBMS is not suitable for sparse datasets.
-
Scale-up/ Scale-out
HBase offers the scale-out feature, which means whenever we need more disk or memory processing power, we can easily add new servers to the cluster. Still, in the case of RDBMS, which supports the scale-up feature, we have to upgrade the older server only, and we’re not allowed to add new servers.
-
Data Structure
HBase is suitable for structured and semi-structured data, but RDBMS is only suited for structured data.
-
Speed
The data retrieval speed of HBase is much faster than RDBMS.
-
Nature and Scalability
The HBase is a highly scalable and dynamic database, whereas RDBMS is not a scalable and static database.
-
Rule
The HBase follows the CAP rule, which means the Consistency, Availability, and Partition-tolerance Rule, whereas the RDBMS follows the ACID rule, which means Atomicity, Consistency, Isolation, and Durability Rule.
Conclusion on Apache HBase
In this guide, we learned about the Apache Hbase, which runs on the top of HDFS and is a column-oriented non-relational database to store and process a massive volume of sparse data.
-
We discussed HBase, its features, architecture, and its components.
-
In this guide, we also discussed how to interact with the HBase shell and perform various Linux-based DDL and DML commands.
-
We also made a comparison of HBase with the relational databases.
-
We don’t have to install HBase explicitly. Instead, we can open the Cloudera to run these Linux-based HBase commands.
-
Cloudera and Apache natively support Apache HBase.
I hope this guide on HBase has helped you to gain a better understanding of how HBase works. If you have any queries, let me know in the comment section.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






