This article was published as a part of the Data Science Blogathon.
Introduction on Kafka
In old days, people would go to collect water from different resources available nearby based on their needs. But as the technology emerged, people have automated the process of getting water for their use without having to collect it from different resources by using a single resource for all needs. A Data pipeline in general terms is very similar to this example. It is like a set of steps that involve storing and enriching the data from the source to the destination. Which further helps to gain insights. It also helps to automation of the storing and transformation of the data.
When we hear the term “data pipeline,” the following questions immediately deserve a mention:
- What is a data pipeline?
- What is its purpose?
- What distinguishes it from ETL?
In the case of a data producer and a data consumer, the producer cannot send the data before doing some data processing, data governance, and data cleaning.
The type of data pipeline is determined by the purpose for which it is being utilized. It might be used for data science, machine learning, or business analytics, among other things.
Types of Data Pipelines
1. Real-Time Data Pipeline
2. Batch Data Pipeline
3. Lambda Architecture (Real-Time and Batch)
The producer can send either batch or real-time data.
Batch Data: CSV, database and mainframe are examples of traditional data. For example, weekly or monthly billing systems.
Real-Time Data: This information comes from IoT devices, satellites, and other sources. For instance, traffic management systems.
Before entering the central data pipeline, batch data goes through batch ingestion, while real-time data gets through stream ingestion.
What are Batch and Stream Ingestion?
Batch ingestion is the processing of data acquired over a period of time. In contrast, because stream ingestion involves real-time data, the processing is done piece by piece.
The data pipeline is made up of several separate components. Consider an ODS (Operational Data Store) where the batch data is staged after processing. Stream data can also be staged in a Message hub using Kafka. A NoSQL database, such as MongoDB, can be used as a messaging hub.
Organizations will be able to collect data from a number of sources and store it in a single location thanks to ODS. Kafka is a distributed data storage that may be used to create real-time data pipelines. Even if all of this data has already been analyzed, it is still possible to enrich it. MDM can be used to do this (Master Database Management). It assists with data by reducing errors and redundancies.
When the data is ready, it may be delivered to the intended destination, such as a Data Lake or a Data Warehouse. Which the customer may utilize to create business reports, machine learning models, and dashboards, among other things.
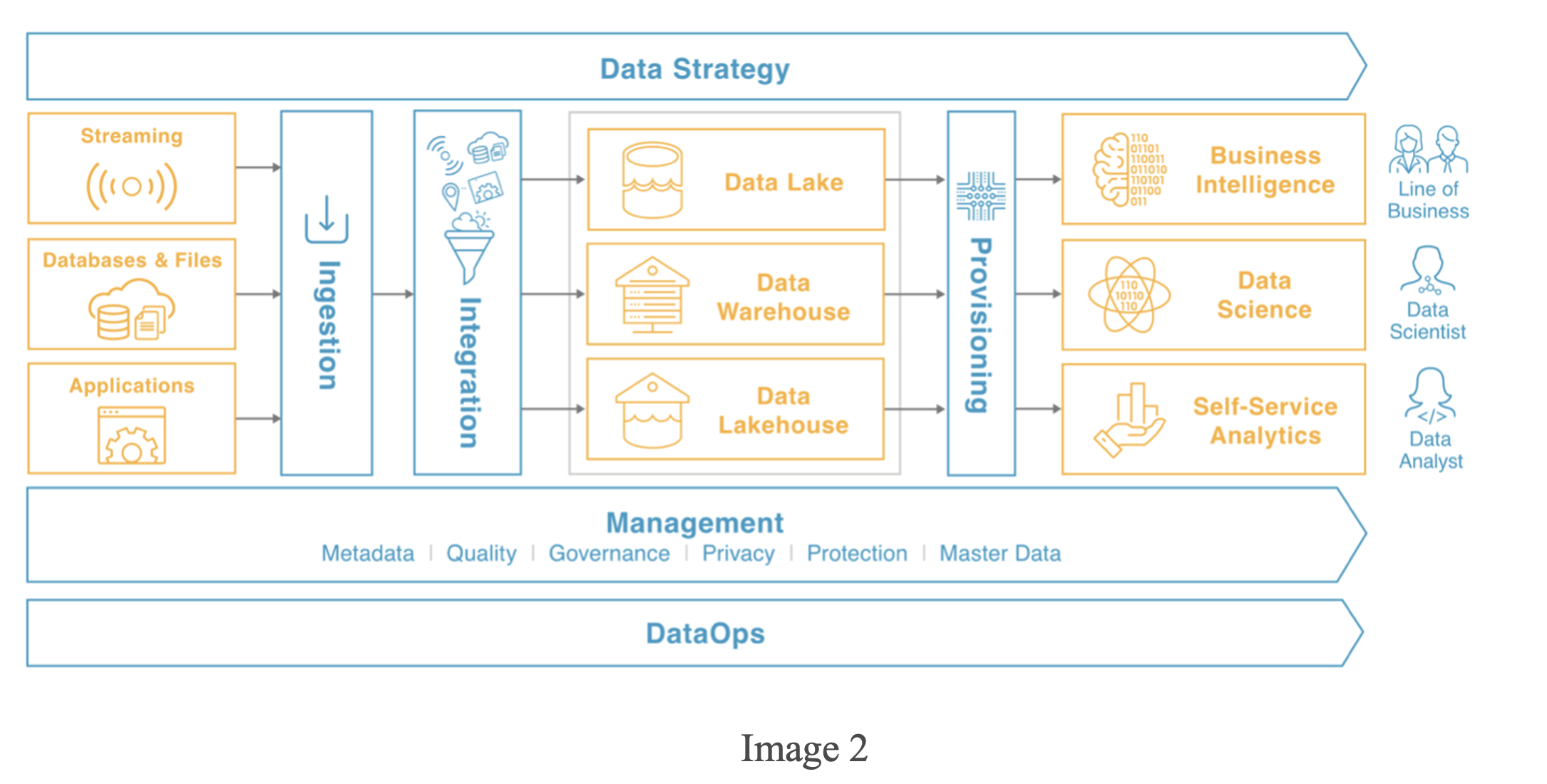
But How is it Different from ETL?
The data is put into a database/data warehouse at the end of the ETL pipeline. The Data Pipeline, on the other hand, is clearly different since it involves more than just importing data. It serves as a link between the source and the destination. Here, the ETL pipeline may be thought of as a subset of the data pipeline.
Let’s dive into Apache kafka,
Linkedin developed Kafka before handing it to the Apache Foundation. Apache Kafka is an open-source platform that works with events. To fully understand the event-driven approach, we must first understand the differences between the data-driven and event-driven approaches.
Data-driven: Consider an online retailer such as Amazon. When customer A purchases product X on date 1, the database records the transaction. But what would happen if we had to consider more than 200 million customers? All of the data is kept in several databases, which should communicate with one another and the online site.
Event-driven: This approach uses the same sort of interaction with the company website. However, all data is kept in a queue. The database may get the information it needs from the queue.
What is an Event?
It might be a single activity or a group of business actions. For example, if customer A purchases product X on date 1, an event is recorded with the following information:
Customer id-123
Name– A
Order ID– 001
Date– 1.
Kafka encourages the use of queues to store events. Any customer can use this queue to get the information they need.
The next question that should come to mind is: How does Kafka differ from other middleware?
1. We can store large amounts of data for any period of time.
2. It is unique for each event (even if the same customer places a second purchase because he or she may be purchasing product Y on a different date).
Another notable role of Kafka is that it uses the “Log” data structure. The OFFSET field in the log indicates where the data is taken. It will never overwrite existing data; instead, it will append the data at the end.
Log Data Structure: The log is the most basic data structure for describing an append-only sequence of records. Immutable log records are added to the end of the log file in an exact sequential manner.
Message– Row(it is the smallest unit of Kafka architecture)
Topic- Table
Partition– View
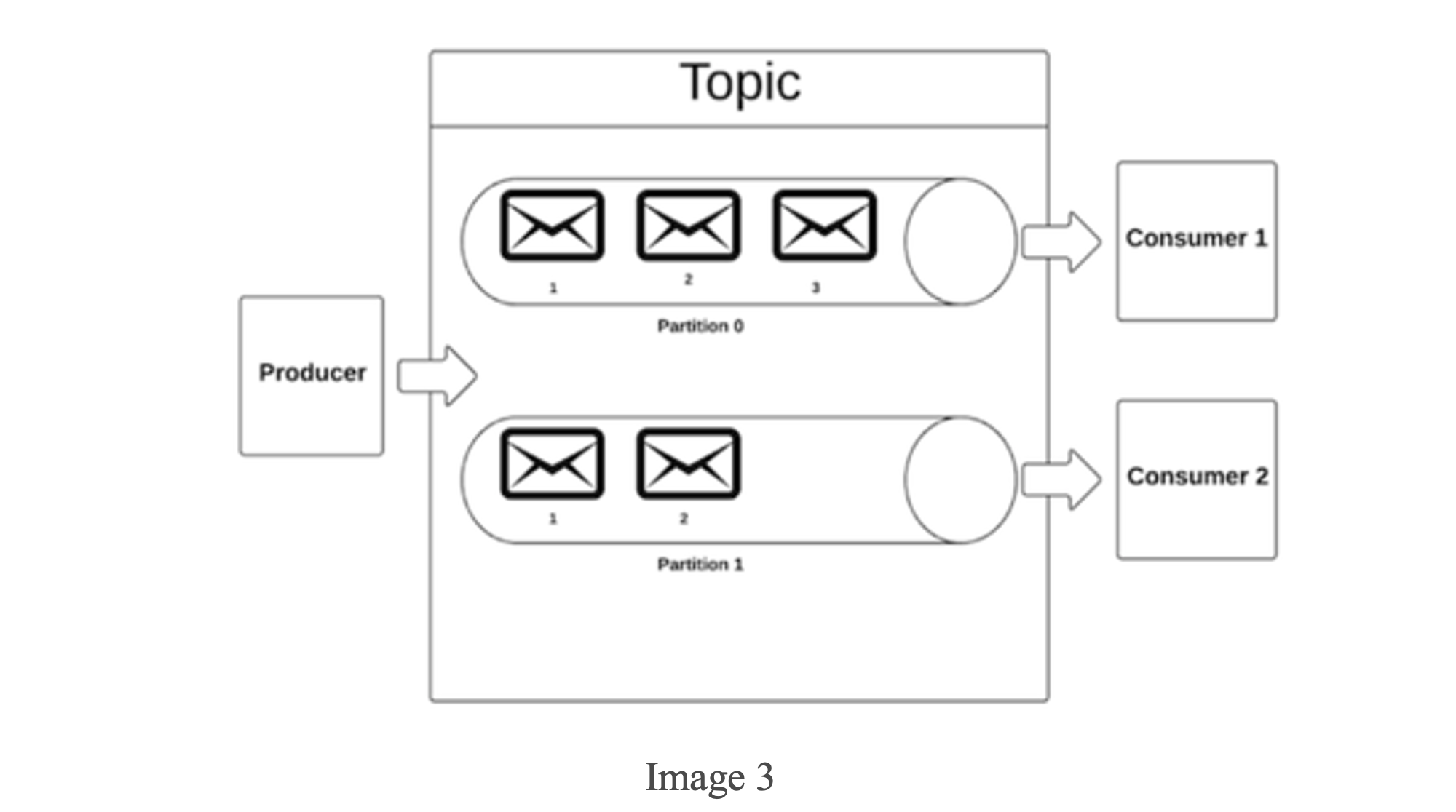
The messages (mail symbol), topics (cylindrical pipe), and partitions are all plainly visible in the above image. For fault-tolerance and scalability, these divisions are kept in multiple settings. The events can be sorted or sequenced within one partition only.
Kafka Cluster:
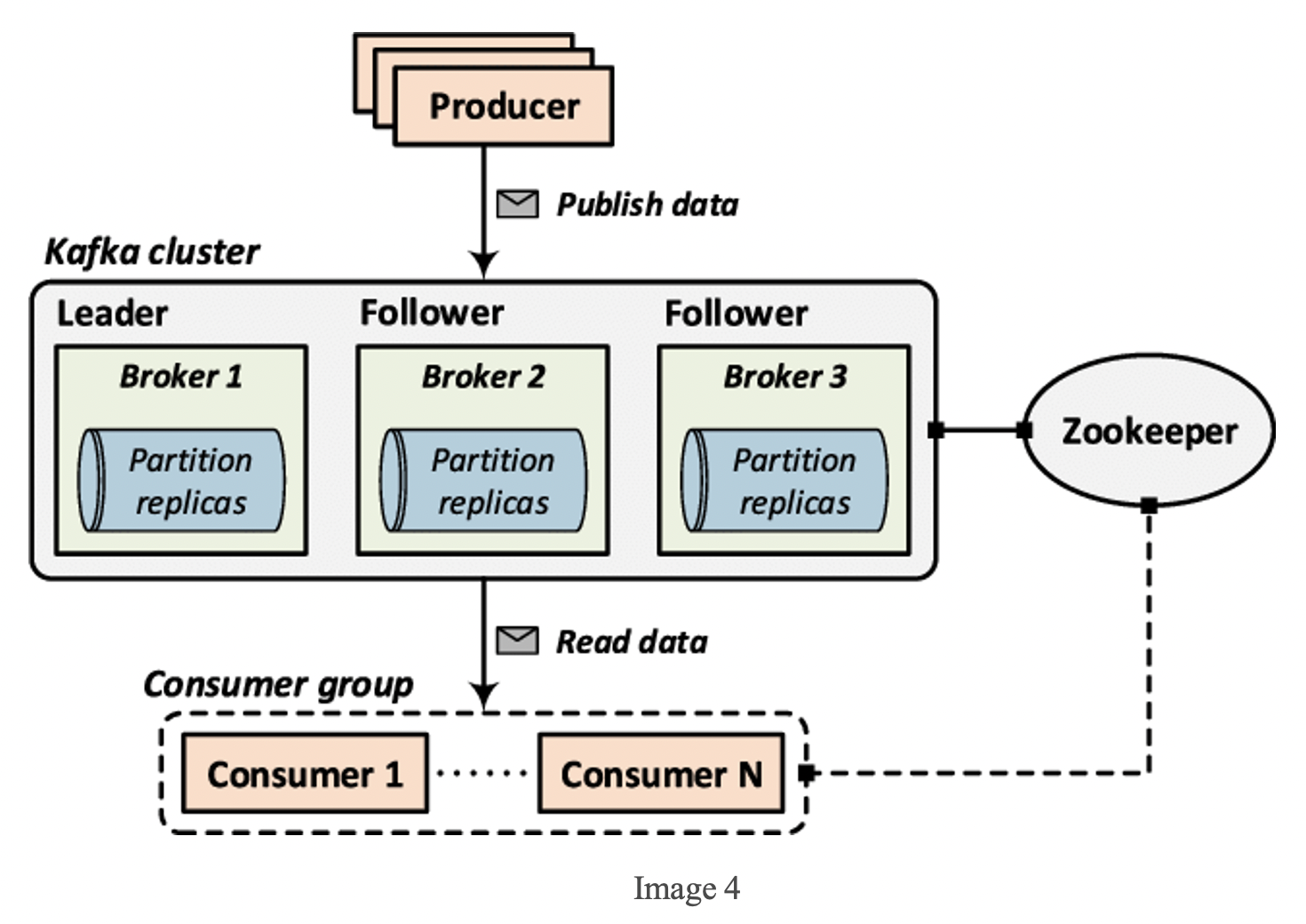
A Kafka broker is another name for a Kafka server. They get data storage and retrieval instructions from the producer and consumer. Data replicates are also kept in separate brokers from the leader. In the event of a failure, the replicated broker will exercise authority. Leaders will always interact with producers and consumers. A Kafka cluster is a collection of many brokers.
To explore further there are Kafka products:
1. Kafka Core (topics, logs, partitions, brokers, and cluster)
2. Kafka Connect (Connecting Mainframe to DB)
3.kSQL (SQL designed for Kafka)
4. Kafka Client ( To connect client)
5. Kafka Streams (manage stream ingestion into Kafka)
Advantages
1. Loose decoupling ( Flexible environment)
2. Fully distributed (Fault tolerance)
3. Event-based approach
4. Zero downtime ( Scalable architecture)
5. No vendor lock-in (Open software)
Conclusion
We can clearly see that this concept of the data pipeline is useful for real-world problems by automation and making data available for the consumers at a single source for them to access and making it easier to gain insights and progressive analysis. It provides a flexible environment.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hi, I’m Usha!
As a Data Science professional with a Master's from Indiana University and a Bachelor's in Computer Science & Engineering, I excel in transforming complex data into actionable insights. I specialize in advanced data visualization, AI solutions, and regulatory reporting, using tools like Python, R, and SQL.
I have a proven track record of enhancing productivity and reducing errors through innovative AI solutions and data analysis. My strong analytical skills are complemented by my ability to communicate complex concepts clearly and work effectively in collaborative environments.
Passionate about driving innovation and making data-driven decisions, I am eager to leverage my expertise in digital media and other dynamic industries. If you're looking for a skilled data scientist who can turn data into strategic assets, let's connect!






