Understanding Loss Function in Deep Learning
Machine learning allows for prediction, classification and decisions derived from data. In research, machine learning is part of artificial intelligence, and the process of developing a computational model has capabilities mimicking human intelligence. Machine learning and related methods involve developing algorithms that recognize patterns in the information that is available, and perform predictive or classification of Loss Function.
This article was published as a part of the Data Science Blogathon.
Table of contents
What Are Loss Functions in Machine Learning?
The loss function helps determine how effectively your algorithm model the featured dataset. Similarly loss is the measure that your model has for predictability, the expected results. Losses can generally fall into two broad categories relating to real world problems: classification and regression. We must predict probability for each class in which the problem is concerned. In regression however we have the task of forecasting a constant value for a specific group of independent features.
What is Loss Function in Deep Learning?
In mathematical optimization and decision theory, a loss or cost function (sometimes also called an error function) is a function that maps an event or values of one or more variables onto a real number intuitively representing some “cost” associated with the event.
In simple terms, the Loss function is a method of evaluating how well your algorithm is modeling your dataset. It is a mathematical function of the parameters of the machine learning algorithm.
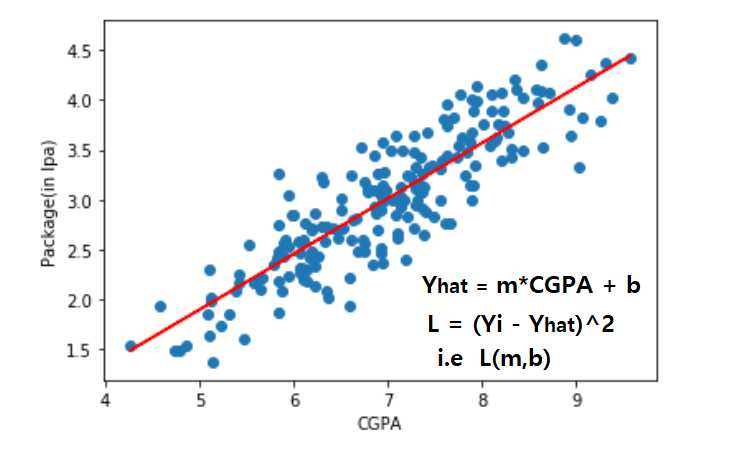
In simple linear regression, prediction is calculated using slope (m) and intercept (b). The loss function for this is the (Yi – Yihat)^2 i.e., loss function is the function of slope and intercept. Regression loss functions like the MSE loss function are commonly used in evaluating the performance of regression models. Additionally, objective functions play a crucial role in optimizing machine learning models by minimizing the loss or cost. Other commonly used loss functions include the Huber loss function, which combines the characteristics of the MSE and MAE loss functions, providing robustness to outliers in the data.
Why is the Loss Function Important in Deep Learning?
In mathematical optimization and decision theory, a loss or cost function (sometimes also called an error function) is a function that maps an event or values of one or more variables onto a real number intuitively representing some “cost” associated with the event.
In simple terms, the Loss function is a method of evaluating how well your algorithm is modeling your dataset. It is a mathematical function of the parameters of the machine learning algorithm.
In simple linear regression, prediction is calculated using slope (m) and intercept (b). The loss function for this is the (Yi – Yihat)^2 i.e., loss function is the function of slope and intercept. Regression loss functions like the MSE loss function are commonly used in evaluating the performance of regression models. Additionally, objective functions play a crucial role in optimizing machine learning models by minimizing the loss or cost. Other commonly used loss functions include the Huber loss function, which combines the characteristics of the MSE and MAE loss functions, providing robustness to outliers in the data.
Also Read: Basic Introduction to Loss Functions
Cost Functions in Machine Learning
Cost functions are vital in machine learning, measuring the disparity between predicted and actual outcomes. They guide the training process by quantifying errors and driving parameter updates. Common ones include Mean Squared Error (MSE) for regression and cross-entropy for classification. These functions shape model performance and guide optimization techniques like gradient descent, leading to better predictions.
Role of Loss Functions in Machine Learning Algorithms
Loss functions play a pivotal role in machine learning algorithms, acting as objective measures of the disparity between predicted and actual values. They serve as the basis for model training, guiding algorithms to adjust model parameters in a direction that minimizes the loss and improves predictive accuracy. Here, we explore the significance of loss functions in the context of machine learning algorithms.
In machine learning, loss functions quantify the extent of error between predicted and actual outcomes. They provide a means to evaluate the performance of a model on a given dataset and are instrumental in optimizing model parameters during the training process.
Fundamental Tasks
One of the fundamental tasks of machine learning algorithms is regression, where the goal is to predict continuous variables. Loss functions such as Mean Squared Error (MSE) and Mean Absolute Error (MAE) are commonly employed in regression tasks. MSE penalizes larger errors more heavily than MAE, making it suitable for scenarios where outliers may have a significant impact on the model’s performance.
For classification problems, where inputs are categorized into discrete classes, cross-entropy loss functions are widely used. Binary cross-entropy loss is employed in binary classification tasks, while categorical cross-entropy loss is utilized for multi-class classification. These functions measure the disparity between predicted probability distributions and the actual distribution of classes, guiding the model towards more accurate predictions.
The choice of a loss function depends on various factors, including the nature of the problem, the distribution of the data, and the desired characteristics of the model. Different loss functions emphasize different aspects of model performance and may be more suitable for specific applications.
During the training process, machine learning algorithms employ optimization techniques such as gradient descent to minimize the loss function. By iteratively adjusting model parameters based on the gradients of the loss function, the algorithm aims to converge to the optimal solution, resulting in a model that accurately captures the underlying patterns in the data.
Overall, loss functions play a crucial role in machine learning algorithms, serving as objective measures of model performance and guiding the learning process. Understanding the role of loss functions is essential for effectively training and optimizing machine learning models for various tasks and applications.
Loss Functions in Deep Learning
Regression Loss Functions
1. Mean Squared Error/Squared loss/ L2 loss
The Mean Squared Error (MSE) is a straightforward and widely used loss function. To calculate the MSE, you take the difference between the actual value and the model prediction, square it, and then average it across the entire dataset.
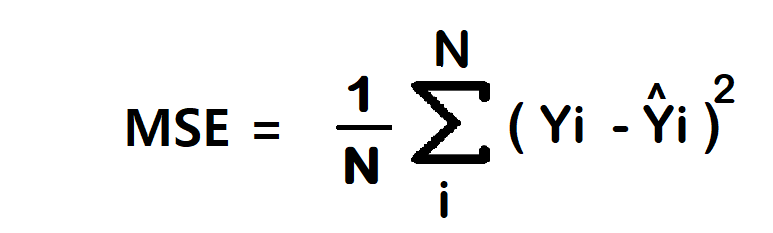
Advantage
- Easy Interpretation: The MSE is straightforward to understand.
- Always Differential: Due to the squaring, it is always differentiable.
- Single Local Minimum: It has only one local minimum.
Disadvantage
- Error Unit in Squared Form: The error is measured in squared units, which might not be intuitively interpretable.
- Not Robust to Outliers: MSE is sensitive to outliers.
Note: In regression tasks, at the last neuron, it’s common to use a linear activation function.
2. Mean Absolute Error/ L1 loss Functions
The Mean Absolute Error (MAE) is another simple loss function. It calculates the average absolute difference between the actual value and the model prediction across the dataset.
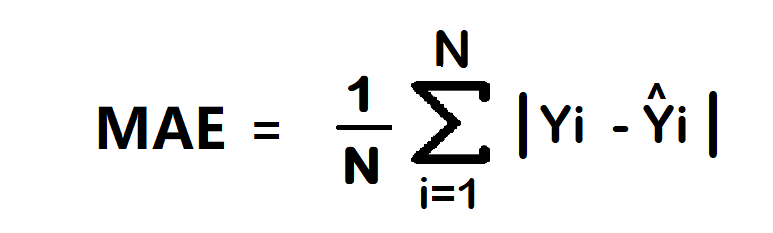
Advantage
- Intuitive and Easy: MAE is easy to grasp.
- Error Unit Matches Output Column: The error unit is the same as the output column.
- Robust to Outliers: MAE is less affected by outliers.
Disadvantage
- Graph Not Differential: The MAE graph is not differentiable, so gradient descent cannot be applied directly. Subgradient calculation is an alternative.
Note: In regression tasks, at the last neuron, a linear activation function is commonly used.
3. Huber Loss
The Huber loss is used in robust regression and is less sensitive to outliers compared to squared error loss.
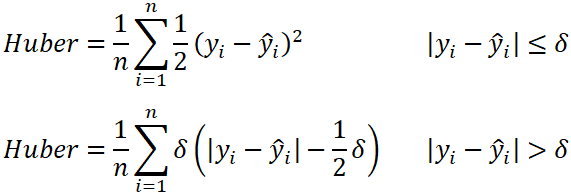
- n: The number of data points.
- y: The actual value (true value) of the data point.
- ŷ: The predicted value returned by the model.
- δ: Defines the point where the Huber loss transitions from quadratic to linear.
Advantage
- Robust to Outliers: Huber loss is more robust to outliers.
- Balances MAE and MSE: It lies between MAE and MSE.
Disadvantage
- Complexity: Optimizing the hyperparameter δ increases training requirements.
Classification Loss
1. Binary Cross Entropy/log loss Functions in machine learning models
It is used in binary classification problems like two classes. example a person has covid or not or my article gets popular or not.
Binary cross entropy compares each of the predicted probabilities to the actual class output which can be either 0 or 1. It then calculates the score that penalizes the probabilities based on the distance from the expected value. That means how close or far from the actual value.
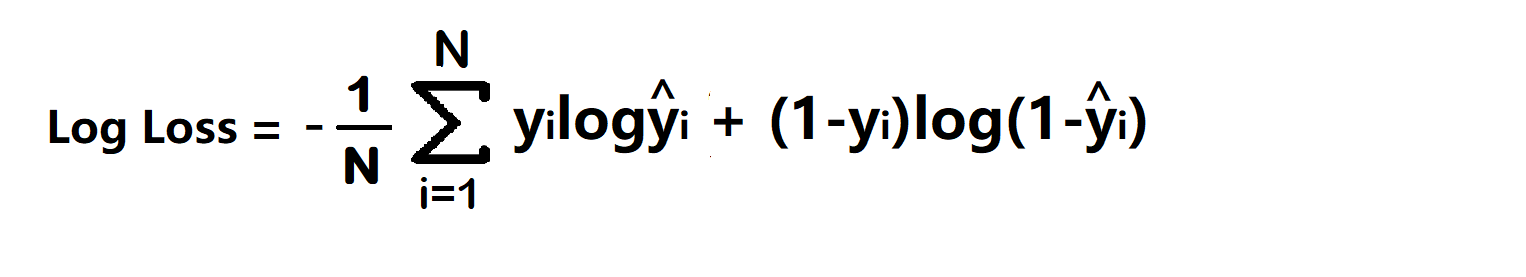
- yi – actual values
- yihat – Neural Network prediction
Advantage –
- A cost function is a differential.
Disadvantage –
- Multiple local minima
- Not intuitive
Note – In classification at last neuron use sigmoid activation function.
2. Categorical Cross Entropy
Categorical Cross entropy is used for Multiclass classification and softmax regression.
loss function = -sum up to k(yjlagyjhat) where k is classes
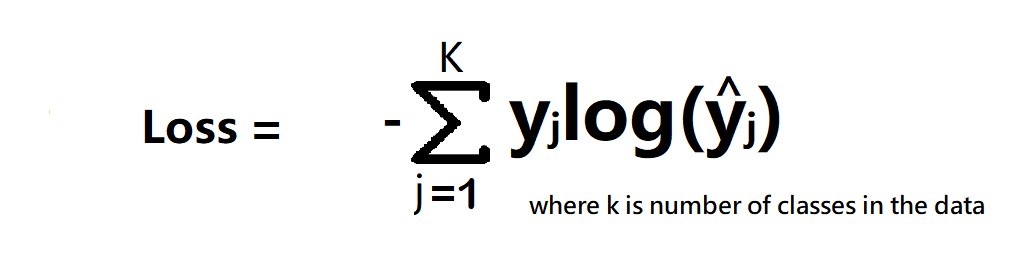
cost function = -1/n(sum upto n(sum j to k (yijloghijhat))
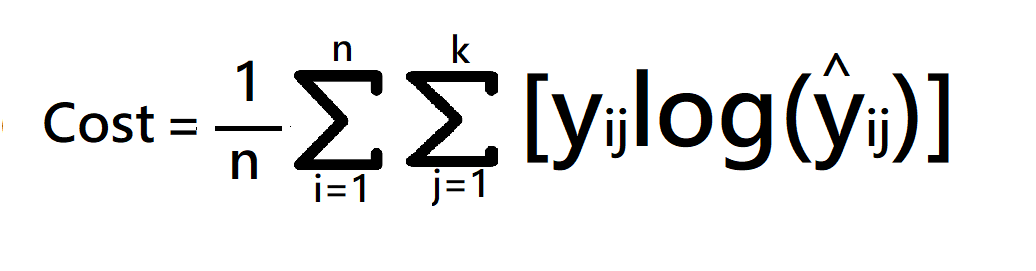
where
- k is classes,
- y = actual value
- yhat – Neural Network prediction
Note – In multi-class classification at the last neuron use the softmax activation function.
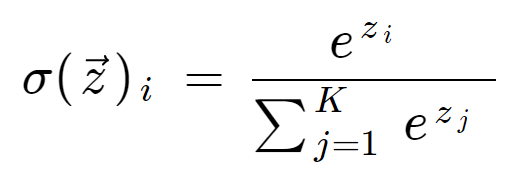
if problem statement have 3 classes
softmax activation – f(z) = ez1/(ez1+ez2+ez3)
When to use categorical cross-entropy and sparse categorical cross-entropy?
If target column has One hot encode to classes like 0 0 1, 0 1 0, 1 0 0 then use categorical cross-entropy. and if the target column has Numerical encoding to classes like 1,2,3,4….n then use sparse categorical cross-entropy.
Which is Faster?
Sparse categorical cross-entropy faster than categorical cross-entropy.
Conclusion
The significance of loss functions in deep learning cannot be overstated. They serve as vital metrics for evaluating model performance, guiding parameter adjustments, and optimizing algorithms during training. Whether it’s quantifying disparities in regression tasks through MSE or MAE, penalizing deviations in binary classification with binary cross-entropy, or ensuring robustness to outliers with the Huber loss function, selecting the appropriate loss function is crucial. Understanding the distinction between loss and cost functions, as well as their role in objective functions, provides valuable insights into model optimization. Ultimately, the choice of loss function profoundly impacts model training and performance, underscoring its pivotal role in the deep learning landscape.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Frequently Asked Questions?
A. A loss function is an extremely simple method to assess if an algorithm models the data correctly and accurately. If you predict something completely wrong your function will produce the highest possible numbers. The better the numbers, the more you get fewer.
A. It’s a simple loss function called 0 to one loss. This literally counts the number of errors a hypothesis function makes in a training course. In each example it suffers 0 in cases of incorrect projection.
A. It counts both negative and positive deviations from production and inflation targets in calculating losses. If the sample period is longer then output growth beyond targets is often regarded as gains and inflation rates lower than targets.
A. They are vital to assessing model performance. The Loss function is an effective way to measure the difference in prediction values, guide the models through the training process and determine the optimal parameter set – minimising the loss.









