In this article, we are going to learn object detection using the Yolo algorithm. For this, we will be using the YOLO V5 version which is easy, simpler, and faster. Now we will see how to detect different objects and also we will use a custom dataset for training our model. And this is all we will do in the Collab notebook which is easy for everyone to use. In our application when the image is provided to it then it will detect all the objects present in the image. And we have an option to capture the live image and then detect the objects present in yolo deep learning.
This article was published as a part of the Data Science Blogathon.
Basically, Computer Vision deals with anything that humans can see and perceive. Moreover, it enables computers and systems to derive complete, meaningful information from digital photos, videos, and other visual inputs.
There are two main approaches to object detection. They are the Machine learning approach and the Deep learning approach. Both these are capable of learning and identifying the object, but the execution of both is far different from each other.
Machine Learning is the application of Artificial Intelligence in which computers learn from the data given and make decisions or predictions based on it. It is usually the process of using algorithms to analyze data and then learning to make predictions and determine things based on the given data.
Machine Learning methods for object detection are SIFT, Support Vector Machine (SVM), and Viola jones object detection.
Deep Learning, also known as deep structured learning, comprises a class of machine learning algorithms. Deep Learning uses a multi-layer approach to extract high-level features from the data that is provided to it.
The Deep Learning model doesn’t require any feature to be provided manually for classification. Instead, it tries to transform its data into an abstract representation. Most deep learning methods implement neural networks to achieve results.
Deep Learning methods for object detection are R-CNN, Faster R-CNN, and YOLO object detection.
Now let’s see how to make our own custom dataset. For that, first, make a folder for all images, and in that, make two more folders naming train_dataset and test_dataset.
In each folder, create two additional folders: Train_images and Train_labels, and Test_images and Test_labels. The Train_images folder will house all training images, while Train_labels will contain corresponding annotation text files in YOLO object detection for object detection format detailing bounding box annotations. Similarly, the test_images folder will store testing images, and test_labels will hold label files corresponding to test images.
Now let’s move to the Collab notebook and start using the YOLO V5 algorithm for object detection using the Custom dataset.
Now we will see how to draw bounding boxes for the images.
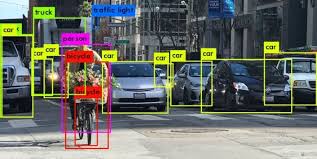
For drawing bounding boxes, there are many ways. And in that now, we will see how to use makesense.ai to draw them.
First, open makesense.ai in any browser, then click on “Get Started”. Next, upload all the images you want to annotate with bounding boxes. Once uploaded, proceed to “Object Detection”. Click on “Start Project”, and then add labels in the correct order to ensure accurate object identification by the model. You can manually list the classes or import a file with predefined classes. Begin annotating by drawing bounding boxes on each image. After completing annotations, click “Actions” at the top left, select “Export Annotations”, and choose “Zip package containing files in YOLO deep learning format”.
You can see a zip folder with all text files downloaded.
Here is a simplified explanation of the four points::
This makes it easier for YOLO algorithm for object detection to find objects in the image. It only needs to look at one square at a time, instead of the entire image.
It does this by using a deep learning model. The model has been trained on a lot of images and labels. This means that the model knows how to identify different types of objects in images.
It achieves this by employing a technique known as non-maximum suppression. Consequently, this method eliminates any overlapping predictions, ensuring that YOLO v5 Algorithm generates only one prediction for each object in the image.
A rectangle is a box that surrounds an object in an image. An object label is a name for the type of object in the box.
These outputs the remaining guesses as rectangles and object labels. This means that YOLO v5 Algorithm outputs a box and a name for each object that it finds in the image.

The YOLO algorithm divides an image into a grid system; within each grid, it detects objects. Recently, ultralytics launched the latest version, YOLO deep learning V5. This algorithm represents the pinnacle of object detection methods. Moreover, it stands out as the simplest, easiest, and fastest option available. Notably, it excels in accuracy when detecting objects.
Visit documentation of YOLO.
First, mount the google drive.
from google.colab import drive drive.mount('/content/drive')Mounted at /content/drive
Now create a folder custom_object_detection and in that create another folder called yolov5 and then move on to that yolov5 folder.
%cd /content/drive/MyDrive/custom_object_detection/yolov5
/content/drive/MyDrive/custom_object_detection/yolov5The Github link for YOLO V5 is
Clone this GitHub repository in the yolov5 folder.
!git clone https://github.com/ultralytics/yolov5 # clone %cd yolov5 %pip install -qr requirements.txt # installimport torch from yolov5 import utils display = utils.notebook_init() # checksYOLOv7 is the latest iteration of the YOLO v5 Algorithm (You Only Look Once) algorithm for object detection. Operating as a single-stage detection method, it can swiftly identify objects in a single image scan. Consequently, YOLOv7 excels in speed, rendering it ideal for real-time applications requiring rapid object detection.
YOLOv7 is also very accurate, achieving state-of-the-art results on several object detection benchmarks. Additionally, it can detect multiple objects in a single image and can be trained to recognize a diverse range of object classes.
Here are some of the key features of the YOLOv7 algorithm:
YOLOv7, a powerful object detection algorithm, finds application in diverse fields like self-driving cars, video surveillance, and robotics.
Here are some examples of how YOLOv7 can be used:
Overall, YOLOv7 is a powerful and versatile object detection algorithm that can be used for a wide variety of applications.
To achieve this, first, navigate to the custom_object_detection folder. Inside, create a dataset folder. Within the dataset folder, create two more folders: images and labels. Within the images folder, create two subfolders: train and val. Similarly, within the labels folder, create train and val subfolders. Place all training images and corresponding labels in the train folders, and validation images and labels in the val folders. Finally, upload these folders to your Colab notebook.
Now we have to modify custom_data.yaml file that is present inside the data folder which is inside the yolov5 folder. Change it according to your problem.
The file should contain like this.
train: ../dataset/images/train
val: ../dataset/images/val
# Classes
nc: 10 # number of classes
names: ['laptop',
'mobile',
'tv',
'bottle',
'person',
'spoon',
'backpack',
'vase',
'dog',
'calculator',
] # class namesFor train and val enter the path of the train and val images folders.
First, enter the number of classes, followed by entering all those classes in the correct order as they were labeled for drawing bounding boxes.
I just gave some example classes here. You can add all classes that are there for your object detection project.
Now finally we are ready to train our model. For training the model just run the following command.
!python train.py --img 640 --batch 8 --epochs 10 --data custom_data.yaml --weights yolov5s.pt --cacheYou can increase the number of epochs to increase the accuracy.
finally, you will find this at last.
Results saved to runs/train/exp14
here your model will be saved.
The model trained with a training dataset and is now prepared for testing.
We can test the model for images, for videos, and also we can detect objects for live video too. We can use the webcam for that. For each of these, we have different commands. The commands are,
First, we will for image object detection.
$ python detect.py --source ../Test/test1.jpeg --weights ../Model/weights/best.ptHere we have to paste the path to the image.
For Video object detection,
$ python detect.py --source ../Test/vidd1.mp4 --weights ../Model/weights/best.ptSimilarly here also paste the path of the video.
Finally, when it comes to webcam,
$ python detect.py --source 0 --weights ../Model/weights/best.ptFinally, you will get this,
Results saved to runs/train/exp14
So when you go to that folder then you will find images or videos after object detection.
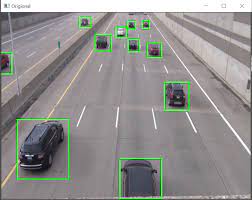
This article primarily focuses on custom object detection using the YOLOv5 algorithm, highlighting its improved ease, simplicity, and speed compared to earlier versions of YOLO deep learning. Notably, one key advantage is eliminating the need to retrain the model during testing once it has been initially trained. The narrative progresses from an introduction to computer vision to exploring different approaches for object detection, followed by the creation of a custom dataset and learning to annotate bounding boxes using makesense.ai. They subsequently implement the YOLOv5 algorithm, culminating in training and testing the model.
A. Yes, YOLO (You Only Look Once) is a CNN-based algorithm designed for real-time object detection, seamlessly integrating classification and localization tasks within a single network.
A. YOLO is better than traditional CNNs for object detection because it performs detection in a single pass, making it faster and more efficient while maintaining high accuracy.
A. The best YOLO algorithm as of now is YOLOv5, known for its improved speed, accuracy, and ease of use compared to earlier versions.
A. Yes, YOLO uses deep learning techniques, specifically convolutional neural networks, to perform real-time object detection and classification.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








nicely presented in a short and understandable form. thankyou
Sir, how send a alert message in telegram after certain specific species of animal detected.