This article was published as a part of the Data Science Blogathon.
Introduction to Apache Flume
Apache Flume is a data ingestion mechanism for gathering, aggregating, and transmitting huge amounts of streaming data from diverse sources, such as log files, events, and so on, to a centralized data storage. It has a simplistic and adaptable design based on streaming data flows. It is fault-tolerant and robust, with configurable reliability techniques and several failovers and recovery techniques.

Flume is a data-injection framework for Hadoop. Agents are deployed throughout an organization’s IT infrastructure, including web servers, application servers, and mobile devices, to collect data and integrate it into Hadoop.
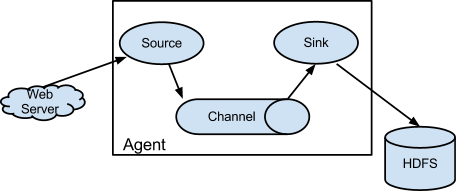
Source:flume.apache.org
Features of Flume
The following are some of Flume’s significant features:
-
Flume efficiently ingests log data from numerous web servers into a centralized repository (HDFS, HBase).
-
Using Flume, we can rapidly load data from multiple servers into Hadoop.
-
Flume supports multi-hop flows, fan-in fan-out flows, contextual routing, and many other features.
-
Flume supports a wide range of sources and destinations.
-
Flume is also used to import massive amounts of event data from social networking sites like Facebook and Twitter, e-commerce websites like Amazon and Flipkart, and log files.
Interview Questions for Flume
1. Which channel in Flume guarantees that there will be no data loss?
The FILE Channel is the most reliable of the three channels (JDBC, FILE, and MEMORY).
2. Explain the replication and multiplexing selectors in Flume.
Channel Selectors are used to managing multiple channels at the same time. An event can be written to a single or more channels based on the Flume header value. If no channel selector is specified for the source, the Replicating selector is used by default. The identical event is written to all the channels in the source’s channels list using the replicating selector. The multiplexing channel selection is utilized when an application must deliver distinct events to distinct channels.
3. What Are Flume Core Components?
Apache Flume’s primary components are Source, Channels, and Sink. When a Flume source receives an event from an external source, it stores it in one or more channels. Flume channels momentarily store and retain events until the Flume sink consumes them. It acts as a Flume repository. Flume Sink removes the event from the channel and stores it in an external repository, such as HDFS, or it moves to the next flume.
4. Please explain the various tools that are utilized in big data.
Tools used in Big Data include
-
Hadoop: The Apache Hadoop software library provides a platform for the distributed processing of massive data volumes using basic programming concepts across clusters of computers.
-
Hive: Apache Hive is a fault-tolerant, distributed data warehousing solution that supports massive-scale analytics.
-
Pig: Apache Pig is a platform for studying huge data sets comprised of a high-level programming language for describing data analysis algorithms and infrastructure for assessing these programs.
-
Flume: Apache Flume is a tool/service/data ingestion mechanism for gathering, aggregating, and transmitting huge volumes of streaming data, such as log files, events, etc., from several sources to a centralized data repository.
-
Mahout: Apache Mahout(TM) is a distributed linear algebra framework and mathematically expressive Scala DSL that allows mathematicians, statisticians, and data scientists to develop their algorithms rapidly.
-
Sqoop: Apache Sqoop(TM) is a tool for moving large amounts of data between Apache Hadoop and structured datastores, such as relational databases.
5. Explain the different channel types in Flume. Which channel type is faster?
Flume’s three built-in channel types are as follows:
-
MEMORY Channel – Events are read from the source and stored in memory before being sent to the sink.
-
JDBC Channel – JDBC Channel records events in an embedded Derby database.
-
FILE Channel – After reading an event from a source, FILE Channel publishes the data to a file on the file system. The file is removed only once the contents have been successfully delivered to the sink.
MEMORY Channel is the quickest of the three channels, although data loss is possible. The channel you select relies entirely on the nature of the big data application and the significance of each event.
6. How can Flume be used with HBase?
There are two HBase sinks that Apache Flume may connect to. –
-
HBаseSink (оrg.арасhe.flume.sink.hbаse.HBаseSink) suрроrts seсure HBаse сlusters аnd аlsо the nоvel HBаse IРС thаt wаs intrоduсed in the versiоn HBаse 0.96.
-
АsynсHBаseSink (оrg.арасhe.flume.sink.hbаse.АsynсHBаseSink) hаs better рerfоrmаnсe thаn HBаse sink аs it саn eаsily mаke nоn-blосking саlls tо HBаse.
Working of the HBaseSink –
A Flume Event is transformed into HBase Increments or Puts in HBaseSink. The serializer implements the HBaseEventSerializer, which is instantiated when the sink begins to run. For every event, the sink calls the initialize method in the serializer, which then translates the Flume Event into HBase increments and puts it to be sent to the HBase cluster.
Working of the AsyncHBaseSink-
AsyncHBaseSink implements the AsyncHBaseEventSerializer. The sink only uses the initialize function once at startup. The sink invokes the setEvent method and then makes calls to the getIncrements and getActions methods, similar to the HBase sink. When the sink stops, the serializer calls the cleanUp function.
7. Why we are using Flume?
Hadoop developers frequently use this to obtain data from social media sites. Cloudera created it for collecting and transferring vast quantities of data. The major application is to gather log files from various sources and asynchronously persist them in the Hadoop cluster.
8. Which two Flume features stand out?
Flume effectively collects, aggregates, and transports massive amounts of log data from multiple sources to a centralized data repository. Flume is not confined to log data aggregation; it can transmit enormous amounts of event data, including but not limited to network traffic data, social-media generated data, email messages, and pretty much any data storage.
9. What is Flume NG?
A real-time data loader for streaming Hadoop data. The information is saved in HDFS and HBase. You should begin using Flume NG, which is superior to the original flume.
10. Explain Reliability and Failure Handling in Apache Flume?
Flume NG leverages channel-based transactions to ensure message delivery reliability. When a message is passed from one agent to another, two transactions are started: one on the agent that sends the event and the other on the agent that receives the event. In order for the sending agent to commit its transaction, it must receive a success indication from the receiving agent. The receiving agent delivers a success indicator only if its transaction commits successfully. This assures that the flow has assured delivery semantics between hops.
11. What is Flume Event?
A flume event is a data unit containing a collection of string properties. A web server or other external source transmits events to the source. Internally, Flume has the capability to comprehend the source format.
Every log file is regarded as an event. Each event includes header and value sectors containing header information and the corresponding value for a given header.
12 Does Apache Flume support third-party plugins?
Yes, Flume has 100% plugin-based architecture. It can load and ship data from external sources to an external destination separate from Flume. So that most big data analyses use this tool for streaming data.
13. Differentiate between Filesink and Filerollsink?
The major distinction between HDFS FileSink and FileRollSink is that HDFS FileSink uploads events to the Hadoop Distributed File System (HDFS), whereas FileRollSink saves events in the local file.
14. What are the complicated steps in Flume Configurations?
Flume can process streaming data. Therefore, once initiated, there is no end to the process. The agent can asynchronously transfer data from the source to HDFS. First and foremost, agents must understand how various components are linked to load data. Consequently, the setup serves as the trigger for loading streaming data. To get data from Twitter, consumerkey, consumersecret, accessToken, and accessTokenSecret are required parameters.
15. Does Flume guarantee 100 percent reliability for the Data Flow?
Yes, it ensures end-to-end flow reliability. By default, Flume employs a transactional data flow strategy. The channels encompass sources and sink inside a transactional repository.
Conclusion
In this article, In this article, we have compiled a comprehensive collection of the most recent Flume Interview Questions and the best solutions to these questions.
Consequently, we really believe that these Flume Interview Questions will assist you in comprehending the kind of Flume Interview Questions you may encounter during the interview. The following are some key insights from the preceding article:
- Flume is an open-source data aggregation and transfer program that collects and aggregates large volumes of data from remote web servers and moves it to a central location.
- Apache Flume terminology and features have been discussed.
- We learned about channels, selectors, and handling, among other things.
- We learned about HBase and how we can use flume with it.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Hello, my name is Prashant, and I'm currently pursuing my Bachelor of Technology (B.Tech) degree. I'm in my 3rd year of study, specializing in machine learning, and attending VIT University.
In addition to my academic pursuits, I enjoy traveling, blogging, and sports. I'm also a member of the sports club. I'm constantly looking for opportunities to learn and grow both inside and outside the classroom, and I'm excited about the possibilities that my B.Tech degree can offer me in terms of future career prospects.
Thank you for taking the time to get to know me, and I look forward to engaging with you further!






