This article was published as a part of the Data Science Blogathon.
Introduction
Apache Sqoop is a big data engine for transferring data between Hadoop and relational database servers. Sqoop transfers data from RDBMS (Relational Database Management System) such as MySQL and Oracle to HDFS (Hadoop Distributed File System). Big Data Sqoop can also be used to transform data in Hadoop MapReduce and then export it to an RDBMS. Many of us are still wondering what Apache Sqoop is, its architecture, features, uses, and how it relates to Big Data. In this Sqoop article, we will discuss everything and its requirements. Let’s get started!
.png)
SQOOP = SQL + HADOOP
Why do we need Big Data Sqoop?
The Sqoop Big Data Tool is primarily used for bulk data transfer to and from relational databases or mainframes. Sqoop in Big Data can be imported from entire tables or allow the user to enter predicates to restrict data selection. You can write directly to HDFS as sequential files or Avro. Big Data Sqoop can take data directly into Hive or Hbase with the right command line arguments. Finally, you can also export data back to relational databases using Sqoop in Big Data. A typical workflow with Big Data Hadoop Sqoop is where the data is pushed to Hive so that intermediate processing and transformation tasks can be performed on Apache Hadoop. After processing is complete, the data can be exported back to the database. This is one of many ways to do “data warehouse offloading” where Hadoop is used for ETL purposes.
Before choosing Sqoop for your business, it is important to review the structures, methods, and information indexes in your big data platforms to achieve the best performance.
Features of Sqoop?
These are some features of Apache Sqoop.
• Parallel Import/Export: The Sqoop Big Data Tool uses the YARN framework to import and export data. Sqoop is fault tolerant with parallelism
• Import SQL query results: Big Data Hadoop Sqoop allows us to import the result returned from the results of a SQL query into HDFS
• Connectors for all major RDBMS databases: Sqoop in Big Data provides connectors for multiple RDBMS (Relational Database Management System) databases such as MySQL and MS SQL Server
• Offers full and incremental loading: Big Data Sqoop can load an entire table or parts of a table with a single command. It, therefore, supports both full and incremental loads.
Sqoop Import
Big Data Hadoop Sqoop imports every single table from RDBMS into HDFS. Each row in a table is treated as one record in HDFS. All records are then saved as text data in text file format or as binary data in Avro and Sequence files.
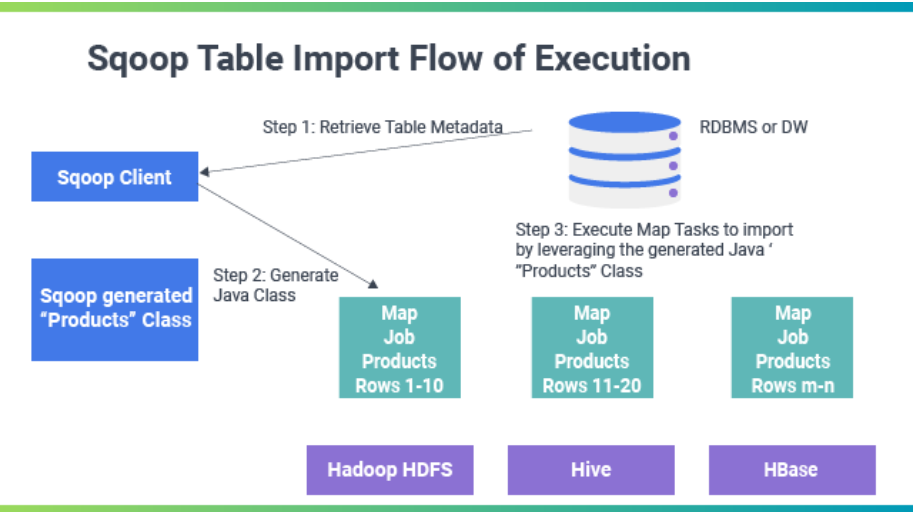
Sqoop Export
Sqoop Big Data Tool exports files from HDFS back to RDBMS. All files given as input to Sqoop contain records called rows in the table. Later, these records are read and parsed into a record set and separated by a user-specified delimiter.
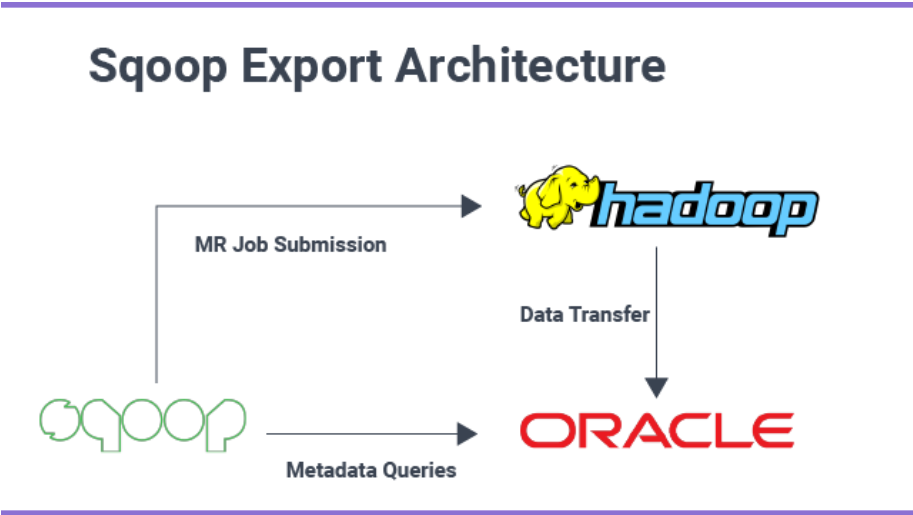
Where should you Sqoop?
One of the largest and largest sources of big data in the modern world is the relational database system. In Hadoop, distributed computing and storage can benefit from processing frameworks like MapReduce, Hive, HBase, Cassandra, Pig, etc., and storage frameworks like HDFS. Data must be transferred between database systems and the Hadoop Distributed File System (HDFS) to store and analyze big data from relational databases. This is where Sqoop in Big Data comes in. Big Data Sqoop acts as an intermediary/layer between Hadoop and relational database systems. Data can be imported and exported between relational database systems and Hadoop and its ecosystems directly using Sqoop.
Let your data support your business growth. Start your Big Data Journey here
Sqoop in Big Data provides a command line interface for end users. Sqoop is also accessible through the Java API. The Sqoop command entered by the user is parsed by Sqoop and runs the Hadoop Map only to import or export data, as the Reduce phase is only required when aggregations are required. Sqoop only imports and exports information; it does not perform aggregations. Big Data Sqoop parses the arguments entered on the command line and prepares the Map task. A map job running multiple mappers depends on the number defined by the user on the command line. During a Sqoop import, each mapper task is assigned a portion of the data to be imported based on the command line. Sqoop distributes the data evenly among the mappers to ensure high performance. Then each mapper creates a connection to the database using JDBC, imports some of the data provided by Sqoop and then writes to HDFS or Hive or Apache HBase, depending on the command line option.
What is the difference between Apache Flume and Apache SQOOP?
Flume works well when streaming data sources generated continuously in a Hadoop environment, such as log files from multiple servers. Apache Sqoop is created to work with any kind of relational database system while providing JDBC connectivity. Sqoop in Big Data can also import data from NoSQL databases such as MongoDB or Cassandra and enable direct data transfer, Hive, or HDFS. To transfer data to Hive using Apache Sqoop, a table must be created for which the schema is taken from the original database. In Apache Flume, data fetches are non-event-driven events, while in Apache Sqoop, data fetches are.
Flume is better when moving bulk data streams from different sources, such as a JMS directory or spoiling. In contrast, Sqoop is an ideal choice. If data is stored in databases like Teradata, Oracle, MySQL Server, Postgres, or any other JDBC compliant database, it is best to use Apache Sqoop. In Apache Flume, data flows from HDFS through multiple channels, while Apache Sqoop HDFS is the destination for importing data.
Apache Flume, Big Data Ingestion has an agent-based architecture, i.e. the code written in the flume is known as an agent, which is responsible for ingesting data. In contrast, in Apache Sqoop, the architecture is based on connectors. Connectors in Sqoop know how to connect to different data sources and retrieve data accordingly.
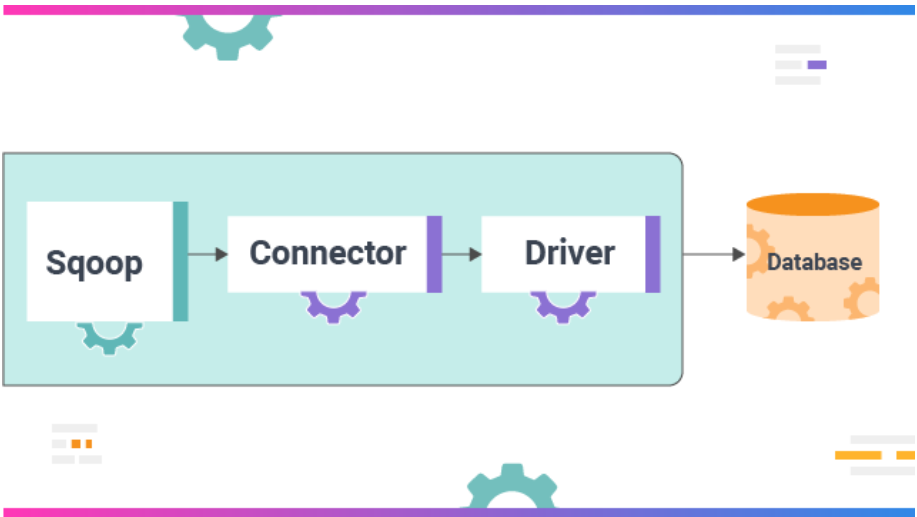
Image From – https://www.educba.com/sqoop/
Sqoop and Flume cannot be used to achieve the same tasks because they were developed specifically for different purposes. Apache Flume agents are developed to retrieve streaming data such as tweets from Twitter or log files from a web server. At the same time, Big Data Sqoop connectors are designed to only work with and retrieve data from structured data sources.
Apache Sqoop is used for parallel data transfers and data imports because it copies data quickly. In contrast, Apache Flume is used for collecting and aggregating data in its distribution, true nature, and highly available backup routes.
Conclusion:
Apache Sqoop is a big data engine for transferring data between Hadoop and relational database servers. Sqoop transfers data from RDBMS (Relational Database Management System) such as MySQL and Oracle to HDFS (Hadoop Distributed File System). Sqoop in Big Data can be imported from entire tables or allow the user to enter predicates to restrict data selection.
- In Hadoop, distributed computing and storage can benefit from processing frameworks like MapReduce, Hive, HBase, Cassandra, Pig, etc., and storage frameworks like HDFS.
- These are some of the Features of Apache Sqoop Parallel Import/Export, Import SQL query results, Connectors for all major RDBMS databases, Offer full and incremental loading
- Big Data Sqoop parses the arguments entered on the command line and prepares the Map task. A map job running multiple mappers depends on the number defined by the user on the command line.
- Sqoop in Big Data can also import data from NoSQL databases such as MongoDB or Cassandra and enable direct data transfer, Hive, or HDFS.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







