With the increased volumes of structured and unstructured data, advanced big tools face many challenges. The expansion of data encompasses not only its sheer volume but also the increasing diversity and authenticity of information. Within this landscape, Hive, operating atop Hadoop, emerges as a crucial solution to sustain the value inherent in Big Data. Hive serves as a dedicated tool employed by data scientists and analysts to transform raw data into actionable insights, thereby unlocking its potential for informed decision-making. In this article we will be discovering all about apache hive!
This article was published as a part of the Data Science Blogathon.
Table of contents
What is Apache Hive?
Apache Hive is an open-source ETL and data warehousing infrastructure that processes structured data in Hadoop. It facilitates the reading, writing, summarizing, querying, and analyzing of massive datasets stored in distributed storage systems using Structured Query Language. Hive is helpful in performing frequent data warehousing jobs like Adhoc-querying, Data Encapsulation, and Analysis of massive datasets stored in distributed file systems like HDFS (Hadoop Distributed File System), which integrates Hadoop.
Apache Hive enables analytics at a vast scale and enhances fault tolerance, performance, scalability, and loose coupling with its input formats. What makes Hive unique is the ability to abstract the complexity of MapReduce jobs. Instead of writing the complex MapReduce jobs, we can write simple SQL-like queries, which reduces the overhead of remembering complex Java codes.
Facebook developed Hive to process their large volume of data(around 20TB per day), but the Apache Software Foundation later took it up. In addition, MNCs like Amazon and Netflix use it to query and analyze their data.
Features of Apache Hive
Below are the main features of Apache Hive that fabricate it into one of the most valuable data processing and analyzing tools for the current as well as the future industries:
Query massive datasets
Hive facilitates access to the files stored either directly in HDFS or in other data storage systems such as HBase and manages the vast datasets.
File Formats
It supports various types of file formats like textfile, ORC, Parquet, LZO Compression, SEQUENCE FILE, RCFILE (Record Columnar File), etc.
Hive-Query Language
This language is similar to SQL. Only the basic knowledge of SQL is enough to work with Hive, such as tables, rows, columns, schema, etc. It makes learning more accessible by utilizing familiar concepts found in relational databases, such as columns, tables, rows, schema, etc. The most significant difference between HiveQL and SQL is that Hive performs queries on Hadoop’s infrastructure, whereas SQL performs queries on a traditional database.
Fast
Hive is a Fast, scalable, extensible tool that enhances the querying on Hadoop.
Partition Support
To improve the query performance, Hive uses directory structures to “partition” data. The partitions and buckets lead to fast data retrieval.
UDF Support
Programmers can define Hive user-defined functions (UDFs) for jobs like data cleansing and filtering as per their requirements. Built-in UDFs manipulate strings, dates, and other data-mining and warehousing tools.
Storage Support
Apache Hive supports various storage types such as HDFS, Apache Hbase, plain text, CSV, XML, etc.
ETL Support
Apache Hive supports the ETL Functionalities, i.e., extract, transform, and load data into tables coupled with joins, partitions, etc.
Table Structure
Hive manages and processes only structured data, similar to RDBMS. So, firstly tables and databases get created; then data gets loaded into the respective tables. At the time of query execution, the Metadata storage in an RDBMS reduces the time to function semantic checks.
Ad-hoc Queries
Ad-hoc queries are variable-dependent queries whose value depends on some other variable, and Apache Hive also supports these queries.
Open-Source
There is no need to pay while using Apache Hive as it is an open-source tool.
Apache Hive Architecture and Components
Apache Hive architecture consists mainly of three components:
- Hive Client
- Hive Services
- Hive Storage and Computer

Let’s explore the core components of Apache Hive!
Hive Client
The Hive client is the interface through which we can submit the hive queries. It supports the applications written in any programming language like python, java, C++, Ruby, etc. With the help of JDBC, ODBC, and thrift drivers, it performs any queries on the Hive with the preferred language. Apache Hive clients are of three types:
- Thrift Clients: As Apache Hive is thrift-based, it can handle the request from a thrift client.
- ODBC Client: ODBC(Open database connectivity) client is the Apache Hive’s driver that allows client applications based on ODBC protocol to connect to Hive.
- JDBC Client: Java database connectivity(JDBC) is used by Hive to connect with java applications that support JDBC protocol. Thrift is used by JDBC drivers to communicate with the Hive Server.
Hive Services
To perform all queries and Hive client integration, Hive offers multiple services like the Beeline, Hive server, Hive compiler, etc. If a customer wants to perform any Hive-related operations, then they can contact Hive Services.
Apache hive offers these services:
Apache Hive Server
Hive server1 is built on Apache Thrift protocol and is also referred to as Thrift Server. Thrift Server handles the cross-platform communication with Hive and allows various client apps to submit requests to Hive and retrieve the final results. But the problem with HiveServer1 is its inability to handle concurrent requests from multiple clients. To overcome this issue, we use HiveServer2 as the successor of HiveServer1. HiveServer2 provides the best support for open API clients like JDBC and ODBC and handles concurrent requests from multiple clients.
Apache Hive Driver
The Apache Hive driver receives the HiveQL statements from different sources like web UI, CLI, Thrift, and JDBC/ODBC. Then, it creates the session handles and transfers the query to the compiler.
Beeline
HiveServer2 supports a command shell named the Beeline, which users use to submit their queries and commands to the system. SQL LINE CLI-based Beeline is a JDBC client.
Hive Compiler
The job of the Hive compiler is to parse the query, perform semantic analysis, and type-checking on the various query expressions and query blocks with the help of metadata stored in the meta store. It generates the execution plan as a DAG(Directed Acyclic Graph) and converts HiveQL queries into MapReduce jobs.
Optimizer
To improve the scalability and efficiency of an execution plan, the Optimizer splits the task and performs the transformation operations.
Execution Engine
The execution engine executes the logical plan generated by the compiler and optimizer according to their dependencies with the help of the Hadoop cluster.
Metastore
Metastore is a relational database and a central repository that stores the metadata information about the table structure and partitions. It also stores information about a column and its type, serializer, and deserializer, needed for the reading and writing data operations, and related HDFS files where data is stored. For meta store configuration, we can choose any of the two modes:
- Embedded: In this mode, the client can use JDBC to interact with the meta store directly.
- Remote: In this mode, the meta store is helpful for non-Java apps and acts as a Thrift service.
HCatalog
HCatalog is built on the top of Hive meta store and used as Hadoop’s storage management layer. It exposes the tabular data of Hive’s meta store and enables users with various data processing tools like YARN, Pig, etc., to quickly get and put data on the grid/table.
WebHCat
WebHCat is an HTTP interface that performs Hive metadata operations and acts as REST API for HCatalog. It is a service provider to the user for running Hadoop MapReduce, Hive, and Pig tasks.
Hive Storage and Computing
In Hive computing, services like Meta Store, file system, and work clients communicate with Hive storage and perform the following actions for the Hive repositories.
- Hive chooses the Meta storage database to store the Metadata information of tables, schemas, columns in a table, their respective data types, and HDFS mapping.
- Hive is built on top of Hadoop, so it uses the HDFS of the Hadoop cluster to store the query results and data loaded in the tables.
Working of Apache Hive
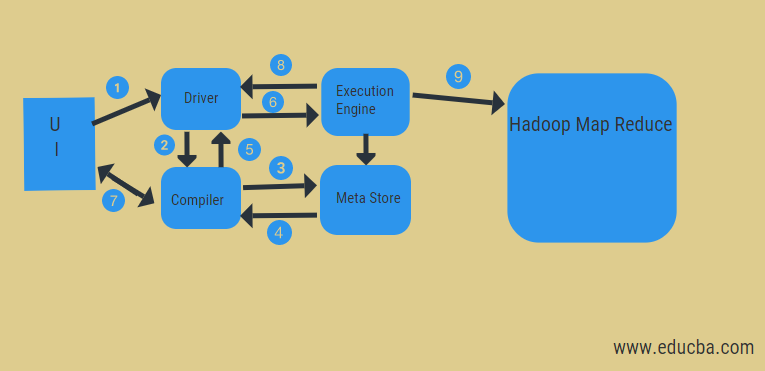
Want to know hoe apache hive works? Refer to the steps below:
- Execute Query
Executed query by data analysts on the User Interface (UI), such as the Web user interface or Command Line Interface. This Hive interface sends the queries to the driver and performs the task of query execution. In this, UI calls the execute interface to any database driver such as JDBC, ODBC, etc.) to execute.
- Get a Plan
The Driver then interacts with the compiler to parse the query, track the requirements, and perform syntax analysis. To make the execution plan, the driver creates a session handle for the query and transfers the query to the compiler.
- Get Metadata
Now, the compiler sends the metadata request to any database like the Meta store to retrieve the necessary metadata from the meta store.
- Send Metadata
Metastore sends metadata as an acknowledgment to the compiler, which is used for semantic analysis of the expressions in the query tree.
- Send Plan
After checking all the requirements, the compiler transfers the generated execution plan to the driver for query execution.
- Execute a Plan
After getting the execution plan from a compiler, the driver forwards the execution plan to the execution engine.
- Submit jobs to MapReduce
Now the execution engine transfers the job to the JobTracker, which is present in the Name node, and then assigns this job to the DataTracker, which is present in the Data node. In this step, the query executes the MapReduce job, and the Execution Engine performs metadata operations with the meta store.
- Fetch Results
The execution engine fetches the results from Data nodes to the User Interface.
- Send Results
The results are sent to the driver by the execution engine and loaded on the front end (UI).
What is HiveQL?
HiveQL stands for Hive Query Language, a high-level SQL-like programming language used by Hive to process and analyze structured or semi-structured data in a Metastore. Hive offers a command-line interface (CLI) to write queries using HiveQL. HiveQL is the best-known tool for traditional data warehousing tasks that focuses on users who are familiar with SQL. In addition, it detaches users from the complexity of MapReduce programming and reuses the concepts of RDBMS like tables, schema, rows, and columns, to accelerate learning. Hive uses MySQL for multiple user metadata storage and derby for single user metadata storage.
Difference between SQL and HiveQL

This table outlines the key differences between Apache Hive and SQL in terms of their purposes, data analysis capabilities, architecture, data types, multitable inserts, MapReduce support, OLTP, schema support, and views.
| Feature | Apache Hive | SQL |
|---|---|---|
| Purpose | Batch and Interactive Query Processing | Relational Database Management System |
| Data Analysis | Complex Data Processing | Detailed Data Querying |
| Architecture | Data Warehousing Project | RDBMS-Based Programming Language |
| Data Types | 9 Types Supported | 5 Types Supported |
| Multitable Inserts | Supported | Not Supported |
| MapReduce | Supports MapReduce | No MapReduce Concept |
| OLTP | Not Supported | Supports OLTP |
| Schema Support | Supported | Used for Data Storage |
| Views | Read-Only Format | Updateable Views |
| Data Size | Can handle petabytes of data | Can only handle terabytes of data |
Introduction to the Apache Hive Shell Commands
To communicate with Hive, a very powerful tool is used called HiveQL Shell. Firstly, we have to install the Hive successfully over the Hadoop Ecosystem; then, only we can communicate with the Hive environment with the help of Java API and the HiveQL Shell. We can open any remote client access software like putty to start the Cloudera and type Hive to enter in the Hive Shell. Hie Shell allows you to write HivdeQL statements and queries the structured data.

Following are the basic HiveQL commands:
1. Create a Database
To create a database in the Apache Hive, we use the statement “Create Database.” The database in Hive is nothing but a namespace or a collection of two or more tables.
Syntax:
create databaseExample:

2. Show Database
The statement “show databases” is used to display all the databases available in your Hive prompt.
Syntax:
show databasesExample:

3. Use Database
The statement “use” is used to enter a specific database in Hive. Whenever you want to check your current database or the database name where you are working, the function “current_database()” is used.
Syntax:
UseExample:

4. Create a Table
To create a table in Hive, HiveQL uses the “create table” statement.
Syntax:
CREATE TABLE
( ,.. )COMMENT 'Add if you want(optional)'LOCATION 'Location On HDFS(optional)'ROW FORMAT DELIMITEDFIELDS TERMINATED BY ',' ;Explanation:-
- Comment:- An optional comment can be added to the table as well as to any specific column.
- Location:- An optional location can override the default database location.
- ROW FORMAT DELIMITED:- This is a compulsory option representing that every new line means a new record entry.
- FIELDS TERMINATED BY ‘,’:- It represents that all the column values are separated using a comma.
Example:

5. Describe
Describe statement is used to see the table’s metadata, which means it will show all the columns of a table with their data types.
Syntax:
DescribeExample:

6. Load Data
Like we use the insert command in SQL to add data into the tables, we use the Load data statement in Hive. We can insert our pre-created entries from the local system or HDFS in the Hive table.
Syntax:
Load data [local/HDFS] inpath '' INTO table
;Example:

7. Select
Select statement of HiveQl is similar to the SQL and retrieves the entire table data.
Syntax:
SELECT [ALL | DISTINCT] expression1, expression2, ...
FROM table-name;Example:

8. Alter
HiveQl uses alter table statement for mainly two purposes:
To rename the table
HiveQL statement “RENAME TO” will rename the table.
Syntax:
Alter table RENAME TOExample:

To Add Columns
HiveQL statement “ADD COLUMNS” is used to add new columns to the existing table.
Syntax:
Alter table
ADD COLUMNS(col1 data type, col2 data type, …);Example:

Note:- Alter command is also used to drop columns from an existing table, change the column name or data type of an existing column, and replace an existing column with a new column.
9. Drop Table
Dropping a table from the Hive meta store deletes the entire table with all rows and columns.
Syntax:
Drop table
;Example:

Conclusion
The hive itself is a very vast concept; in this guide, we learned about some basic concepts of Apache Hive and HiveQL.
- We learned about Hive, its features, architecture, and its components.
- This guide also discussed how to interact with the Hive shell and perform various Linux-based HiveQL commands.
- We also made a comparison of HiveQL with the structured query language.
- We don’t have to install Hive explicitly. Instead, we can open the Cloudera to run these Linux-based Hive commands.
- Cloudera and Apache natively support Apache Hive.
I hope this guide on Hive has helped you to gain a better understanding of how Hive works.
Frequently Asked Questions
Q1. What is Apache Hive used for?
A. Apache Hive is a data warehousing and SQL-like query language system built on top of Hadoop. It enables users to perform data analysis, querying, and summarization on large datasets stored in Hadoop’s distributed storage, making it easier to work with big data.
Q2. What is the difference between Hadoop and Apache Hive?
A. Hadoop is a framework that facilitates distributed storage and processing of big data across clusters. At the same time, Apache Hive is a data warehousing and querying tool that provides a SQL-like interface to query and manage data stored in Hadoop’s HDFS.
Q3. Is Apache Hive an ETL tool?
A. Apache Hive is not a traditional ETL (Extract, Transform, Load) tool. While it does offer some data transformation capabilities, its primary function is to provide a SQL-like querying language for data analysis and reporting on large datasets stored in Hadoop.
Q4. What is Apache Hive vs Spark?
A. Apache Hive and Apache Spark are tools used for big data processing, but they serve different purposes. Hive primarily focuses on querying and analyzing data stored in Hadoop. In contrast, Spark is a general-purpose data processing framework that can perform various tasks, including data processing, machine learning, and real-time analytics.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.






