This article was published as a part of the Data Science Blogathon.
Introduction
Face recognition is present in our society in an effusive way. These systems can help many organizations to improve their work environment or even working methods, for example:
- Helping police identify and locate suspects;
- Helping companies control access;
- Helping security guards identify possible intruders.
In cases where the individual collaborates with the face recognition systems, the creation of these systems with good results is easily obtained, since all the system variables are controlled. However, in situations where the individual does not cooperate with the system, we have several factors that will degrade the images and consequently contribute to obtaining poor results. For example, the low resolution of the photos and the use of glasses will contribute to a greater difficulty in recognizing individuals. Therefore, in this article, we will evaluate if the face alignment contributes to better results in this type of environment.
After this article, you will be able to build a system with:
- Good AUC;
- A strategy to improve face recognition in real-world scenarios;
- A good performance in unconstrained scenarios.
This article is organized in 7 main sections:
- Face Alignment Theory;
- Datasets;
- Proposed idea for training;
- Proposed idea for testing;
- Implementation;
- Results;
- Analysis.
Face Alignment Theory
Theoretically, if an image is aligned, the training of the model will be more successful because the centre of the face will be equal for all the images in a dataset.
Also, the vector with the face embeddings, the output of our model, will have certain parts of the face in different places in the vector. For example, if the face is oval, you may have embeddings of that face in places that a rounder face does not have. This way, when calculating the distance or similarity between the two faces, we can get a more accurate result of whether they are the same person.
Datasets
For training, we are going to use CASIA-WebFace. The CASIA-WebFace has 494414 images divided by 10575 real identities. It was also necessary to split the dataset into two sets: 80% for training and 20% for validation.
For testing, we will use (Labeled Faces in the Wild) LFW (available here). The LFW has 13233 images divided by 5749 identities. This dataset is commonly used to test face recognition models. In addition, this dataset contains a list of pairs that will be very useful for doing face verification in the different types of tests.
Proposed Idea for Training
To prove this theory, we need to train our model with an aligned dataset and another model with an unaligned dataset. For this training, we will use the CASIA-WebFace dataset.
To do the first training, we align the entire dataset and send the aligned faces as input to the CNN, as shown in the figure below:
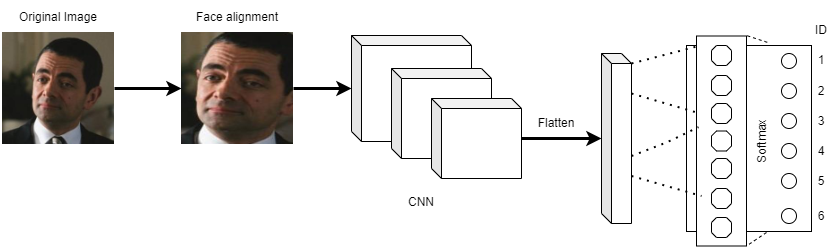
To do the second training, the pipeline is the same as the figure above, but the image is not aligned, i.e. the images passed as input for the CNN are not aligned. For this training, we use the same dataset as the previous one.
Proposed Idea for Testing
To test our model, we want to determine the ROC Curve and accuracy and analyze these results to see the impact of face alignment.
For the first experiment, we didn’t align the dataset used for testing. The model used in this testing was trained with an unaligned dataset.
For the second experiment, we align the entire dataset. After that, we will pass each element of the pairs list as input to a CNN. With this, it is possible to determine the ROC curve and accuracy.
.png)
Pipeline for testing with the aligned dataset
Implementation
For this experiment, we will use a ResNet50 as the backbone and Softmax as an activation function to train the model. The model was implemented using TensorFlow and Keras, as shown below:
# IMAGE_Size = size of the image. In this case [112,112] # ResNet50 backbone backbone = ResNet50(input_shape=IMAGE_SIZE + [3], weights='imagenet', include_top=False)
# IMAGE_Size = size of the image. In this case [112,112] # ResNet50 backbone from tensorflow.python import tf2 from keras.applications import ResNet50
# Put backbone layers trainable for layer in backbone.layers: layer.trainable = True backbone.summary() x = BatchNormalization()(backbone.output) x = GlobalAveragePooling2D()(x) x = Dropout(rate=0.5)(x) x = Flatten()(x) prediction = Dense(numClasses, activation='softmax', activity_regularizer=regularizers.l2(0.01))(x) # create a model object model = Model(inputs=backbone.input, outputs=prediction)
The full code for training and testing is available on my GitHub page.
To align the dataset, we use the script available on this GitHub page. This script uses a (Multi-task Cascaded Convolutional Networks) MTCNN.
This MTCNN has 3 stages:
- In the first stage, the images are fed to a CNN and then the network returns the candidate’s facial windows and their bounding box regression vectors;
- In the second phase, the images are fed to another CNN. This rejects a large number of false candidates, performs calibration with bounding box regression, and conducts NMS;
- In the final stage, the network identifies 5 facial landmarks and returns them.
After these stages, it’s possible to align the faces using the 5 facial landmarks.
Unfortunately, this script has some outdated libraries, so it is necessary to make some changes:
In align_dataset_mtcnn.py:
remove the value, feed_in, dim = (inp, input_shape[-1])
#need to import the following packages
import tensorflow.compat.v1 as tf #ignore the red warning
import imageio # to replace misc.imread() as format: imageio.imread(os.path.join(emb_dir, i))
from PIL import Image # to replace misc.resize as format: scaled = np.array(Image.fromarray(cropped).resize((args.image_size, args.image_size), Image.BILINEAR))
In detect_face.py:
Row 85, replace as format: data_dict = np.load(data_path, encoding='latin1', allow_pickle=True).item()To run the alignment process more effectively, we need to split the process into 4 subprocesses by creating and running the script as follows:
for N in {1..4}; do python3 ../facenet/src/align/align_dataset_mtcnn.py pathToDataset pathToSaveAlignDataset --image_size 224 --margin 32 --random_order --gpu_memory_fraction 0.24 & done
- pathToDataset – Path to the dataset that you want to align;
- pathToSaveAlignDataset – Path where the aligned dataset will be saved;
- image_size – The target size for the images;
- margin – Margin for the crop around the bounding box (height, width) in pixels;
- gpu_memory_fraction – the fraction of the GPU that will be allocated for each subprocess.
After the faces are aligned, we will use the test script available in my GitHub project to test our theory.
In summary, for the first test, the model was trained using an unaligned CASIA-WebFace dataset and tested using an unaligned LFW dataset. For the second test, the model was trained using aligned CASIA-WebFace and tested using aligned LFW.
Results
After running the first test, we obtain this ROC Curve for the unaligned LFW dataset:
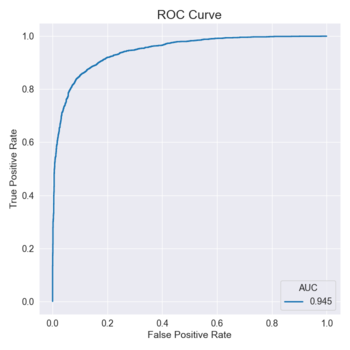
The accuracy of this test was 87.63%. Analyzing the ROC curve and the accuracy, we see that we obtain a good value for the (Area under the ROC Curve) AUC, but the AUC and accuracy could improve if we applied some changes to the test.
To improve the results, we performed the second test with the aligned LFW dataset. After running this test, we obtain this ROC Curve (orange curve):
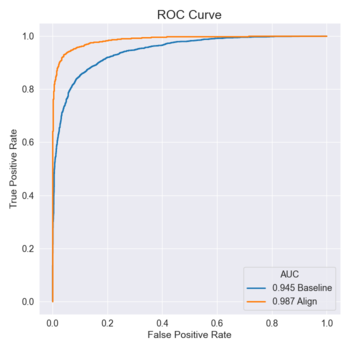
This figure contains the two tests that were performed. The orange curve refers to the second test and the blue curve refers to the first test.
Comparing the two curves, it can be seen that the alignment of the faces contributed to a steeper ROC curve and consequently a higher AUC than the blue curve. Also, the accuracy improves significantly, reaching 94.52% on the second test.
Analysis
Given the results, it can be detected that the face alignment theory holds true for face recognition cases. Whenever the alignment was applied, we obtained better results than when it is not applied. In summary, we can conclude that face alignment effectively contributes to better results in face recognition systems.
Conclusion
Face recognition systems are available in our society in many forms and are applied in many domains.In these systems, aligning the faces will improve the AUC significantly and help you get better results in cases where the variables of the system aren’t controlled. Therefore, we can conclude that facial alignment has the following advantages:
- Improve the AUC;
- Improve the capacity of a model to recognize individuals;
- Improve systems with unconstrained scenarios (e.g., surveillance environments).
In summary, we can conclude that face alignment has an important role in face recognition systems.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.





