This article was published as a part of the Data Science Blogathon.
Introduction
AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The managed service offers a simple and cost-effective method of categorizing and managing big data in an enterprise. It provides organizations with a data integration tool that formats information from different data sources and organizes it in a central repository where it can be used to inform business decisions.
.jpg) Source: – https://aws.amazon.com
Source: – https://aws.amazon.com
How AWS Glue Works
Glue uses ETL jobs to extract data from a combination of other cloud services offered by Amazon Web Services (AWS) and incorporate it into data lakes and data warehouses. It uses an application programming interface (API) to transform the extracted dataset for integration and helps users monitor jobs.
Users can schedule ETL jobs or select events to trigger the job. Once started, Glue extracts the data, transforms it based on code that Glue automatically generates, and loads it into Amazon S3 or Amazon Redshift. The glue then writes the metadata from the job to the embedded AWS glue data catalog.
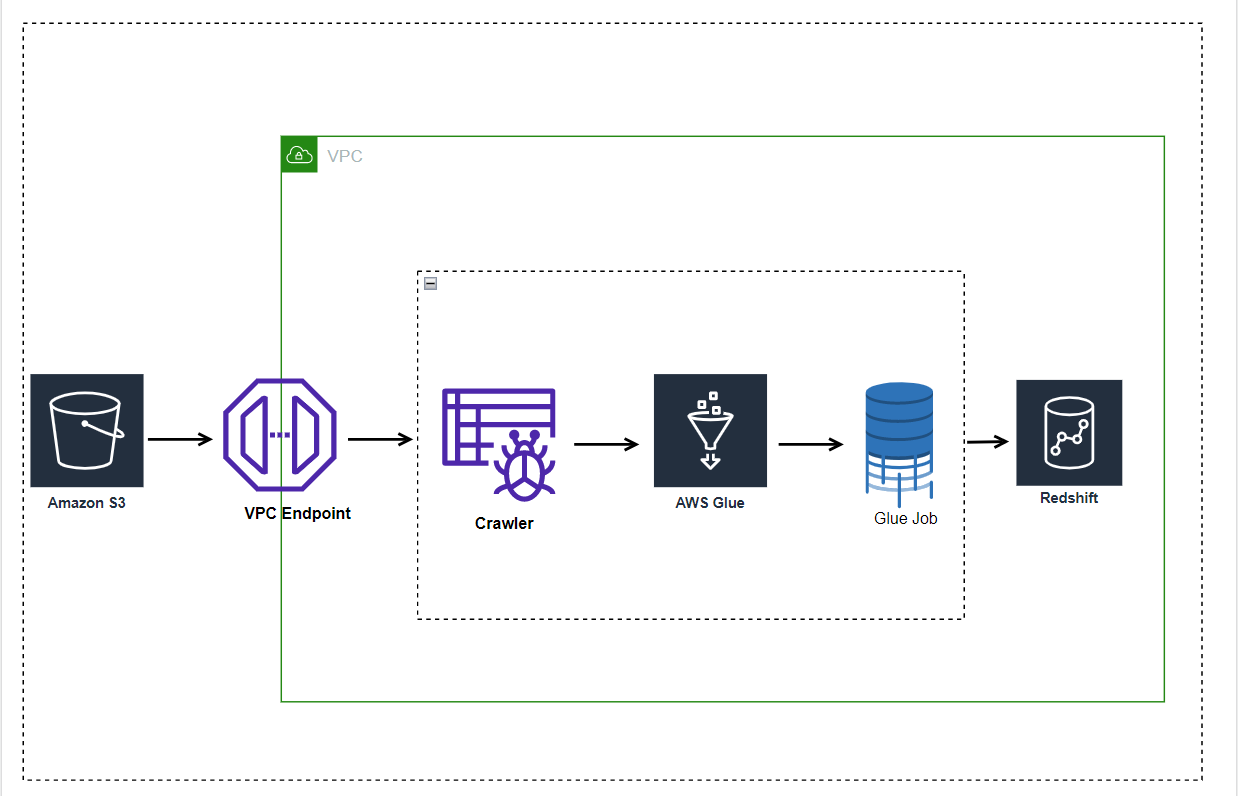
The service can automatically find enterprise structured or unstructured data when it is stored in data lakes in S3, data warehouses in Amazon Redshift, and other databases that are part of the Amazon Relational Database Service. Glue also supports MySQL, Oracle, Microsoft SQL Server, and PostgreSQL databases running on Amazon Elastic Compute Cloud (EC2) instances in the Amazon Virtual Private Cloud.
The service then profiles the data in a data catalog, a metadata repository for all data assets that includes details such as table definition, location, and other attributes. The team can also use Glue Data Catalog as an alternative to Apache Hive Metastore for Amazon Elastic MapReduce applications.
Configure the transform properties in AWS Glue.
Source: – https://kontext.tech/diagram/
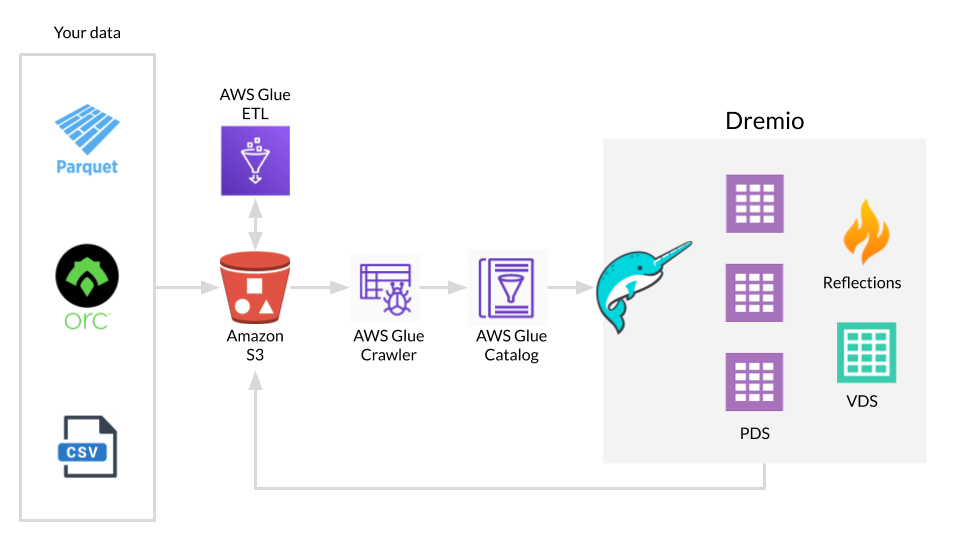
To load metadata into the data catalog, the service uses Glue crawlers that scan the raw data store and extract schema and other attributes. An IT professional can customize browsers as needed.
Properties of AWS Glue
The basic properties of the glue are as follows:
- Automatic schema detection. Glue allows developers to automate crawlers to retrieve schema-related information and store it in a data catalog that can then be used to manage jobs.
- Task scheduler. Paste jobs can be set up and invoked on a flexible schedule using event-based or on-demand triggers. Multiple jobs can run in parallel, and users can specify dependencies between jobs.
- Developer endpoints. Developers can use them to debug Glue and create custom readers, writers, and transforms that can then be imported into custom libraries.
- Automatic code generation. The ETL process automatically generates the code; the only necessary input is the location/path to store the data. The code is either in Scala or Python.
- Integrated data catalog. It is a unique metadata repository for data from different sources in the AWS pipeline. An AWS account has one catalog.
Advantages and Disadvantages of Using Glue
The advantages of AWS glue are as follows:
- Fault tolerance. Failed jobs in Glue can be retrieved, and logs in Glue can be debugged.
- Filtering. Bad data filters.
- Support, support. It supports several non-native Java Database Connectivity (JDBC) data sources.
- Maintenance and deployment. Easy maintenance and deployment because AWS completely manages the service.
Source: -https://aws.amazon.com
Disadvantages of AWS Glue include:
- Limited compatibility. While AWS Glue works with several commonly used data sources, it only works with services running on AWS. Organizations may need a third-party ETL service if the resources are not AWS-based.
- No incremental data sync. All data is first scheduled to S3, so Glue is not the best choice for real-time ETL jobs.
- Learning curve. Teams using Glue should have a good understanding of Apache Spark.
- Relational database queries. Glue has limited support for traditional relational database queries, only SQL queries.
AWS Glue Use Cases
1. Improve speed and reduce costs
Financial is a technology company that specializes in product-related financial services. These products are useful and help financial services companies in Southeast Asia. Its headquarters are in Jakarta, Indonesia. She wanted to elevate and transform everyday ETL jobs. The company opted for many other solutions but could not find the ideal solution for the needs. Ultimately, they decided to use AWS Glue, which paid off as the team could easily load the data, run the processes, and transform it for the next process on Redshift. It also allowed the company to speed up the process and save costs. This association could not only prove to be faster and more efficient, but it was also much cheaper than the proven alternatives. For a startup like Financial, cost savings were one of the deciding factors.
2. Build a data intelligence and analytics platform
Burt Corporation is a start-up data company specializing in data products to transform the new online media landscape. It has New York, Berlin, and Gothenburg (Sweden) offices. Many major online media publishers use Burt’s data intelligence and analytics platform to understand and optimize their online marketing strategies. The platform must have effective data collection, processing, analysis, and decision-making capabilities to meet these requirements. Therefore, the company decided to use AWS Glue, Amazon Redshift, and Amazon Athena to meet these requirements. Burt transformed his data analytics and intelligence platform by integrating Amazon Athena and AWS Glue. As a result, Burt was able to deliver a solution that met the client’s requirements.
3. Optimized cybersecurity environment
One of the world’s most recognized brands needs no introduction. It specializes in the technology sector and specifically in industrial production. Siemens is a German multinational corporation headquartered in Munich, Germany. She wanted to counter cyber threats with a smart system. This system was expected to prepare data, analyze it and make predictions using machine learning. The company decided to turn to Amazon Web Services for a solution. AWS experts recommended Amazon Sage Maker, AWS Glue, and AWS Lambda. AWS Glue played a key role in this process. It is a tool that extracts data and helps data scientists categorize data easily.
 Source: -https://aws.amazon.com
Source: -https://aws.amazon.comETL Engine
After the data is cataloged, it is searchable and ready for ETL jobs. AWS Glue includes an ETL script recommendation system for generating Python and Spark code (PySpark) and an ETL library for running jobs. A developer can write ETL code through the custom Glue library or PySpark code using the AWS Glue console script editor.
A developer can also import custom code or PySpark libraries. In addition, developers could upload code for existing ETL jobs to an S3 bucket and then create a new Glue job to process the code.
Plan and Organize ETL Jobs
AWS Glue jobs can be run on a schedule. A developer can schedule ETL jobs at minimum five-minute intervals. AWS Glue cannot handle streaming data.
The service allows for scheduled, on-demand, and task completion triggers if the development team prefers to organize tasks. A scheduled launcher runs jobs at specified intervals, while an on-demand launcher runs when the user prompts. With the task completion trigger, one or more tasks can be executed after the tasks are completed. These jobs can run concurrently or sequentially and can also be run from an external service such as AWS Lambda.
AWS Glue Price
AWS charges users a monthly fee to store and access metadata in the Glue Data Catalog. With AWS Glue pricing, there is a per-second fee, either a minimum of 10 minutes or 1 minute (depending on the Glue version users have), for the ETL job and crawler execution. AWS also includes a per-second fee for connecting to a development endpoint for interactive development.
Conclusion
It uses an application programming interface (API) to transform the extracted dataset for integration and helps users monitor jobs. The service then profiles the data in a data catalog, a metadata repository for all data assets that includes details such as table definition, location, and other attributes. The team can also use Glue Data Catalog as an alternative to Apache Hive Metastore for Amazon Elastic MapReduce applications.
- AWS Glues has Five Basic properties:- Automatic schema detection, Task scheduler, Developer endpoint, Automatic code generation, and Integrated data catalog.
- The advantages of AWS glue are as follows:- Fault tolerance, Filtering, Support, support, Maintenance, and deployment. Disadvantages of AWS Glue include:- Limited compatibility, No incremental data sync, Learning curve, and Relational database queries.
- A scheduled launcher runs jobs at specified intervals, while an on-demand launcher runs when the user prompts. With the task completion trigger, one or more tasks can be executed after the tasks are completed. These jobs can run concurrently or sequentially and can also be run from an external service such as AWS Lambda.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







