Audio-textual Cross-modal Learning for Conversational ASR
This article was published as a part of the Data Science Blogathon.
Introduction
Utilizing conversational context in ASR systems has shown to be an effective approach for improving conversational ASR performance. As a result, numerous methods have been proposed. However, the existing methods present some issues, like the recognized hypothesis of the current utterance could be biased due to the inevitable historical recognition errors. This is problematic and needs to be resolved. To address this problem, researchers have proposed an audio-textual cross-modal representation extractor, which we will explore in this article.
Now, let’s get started…
Source: Canva|Arxiv
Highlights
-
An audio-textual cross-modal representation extractor consists of two pre-trained single-modal encoders, a pre-trained speech model called Wav2Vec2.0 and a language model called RoBERTa, and a cross-modal encoder to learn contextual representations directly from preceding speech is proposed.
-
Some input tokens and input sequences of each modality are randomly masked. Then a modal-missing or token-missing prediction with a modal-level CTC loss on the cross-modal encoder is carried out.
-
While training the conversational ASR system, the extractor is frozen to extract the textual representation of the preceding speech; extracted representation is then used as context fed to the ASR decoder through the attention mechanism.
-
The textual representation extracted from the current and previous speech is sent to the decoder module of ASR, which reduces the relative CER by up to 16% on three Mandarin conversational datasets (MagicData, DDT, and HKUST).
What was the problem with the existing methods?
As we discussed briefly in the Introduction section, the existing methods usually rely on extracting contextual information from transcripts of preceding speeches in conversations. However, hypotheses of the preceding utterances are used during inference rather than ground truth transcripts to extract contextual representations. Consequently, new errors could be introduced by the inaccuracies in historical ASR hypotheses when the current utterance is recognized, which is an issue that needs to be resolved.
Now that we have looked into the problem, let’s look at the proposed method, which aims to resolve the aforementioned challenge.
Method Overview
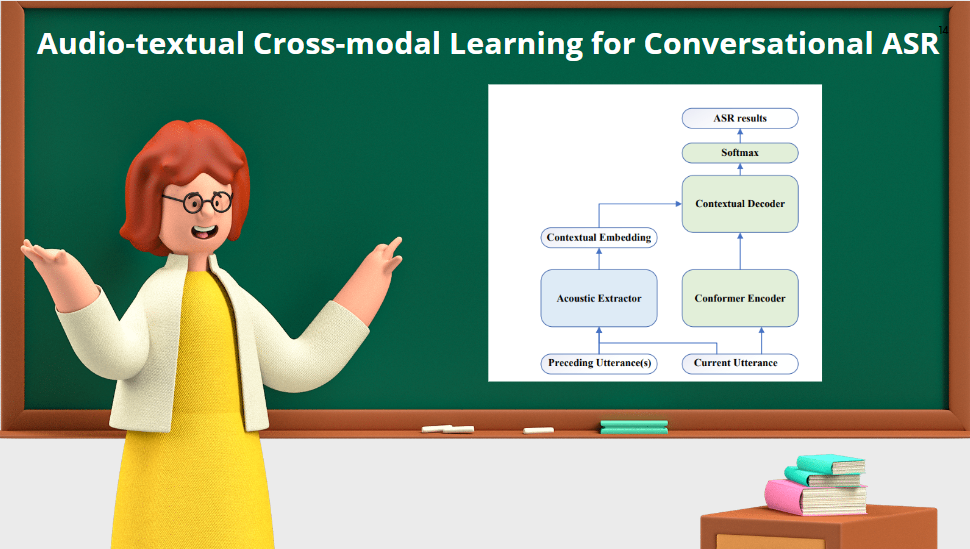
Figure 1 shows the diagram of the proposed conversational ASR system. The cross-modal representation extractor was introduced, which takes the advances from the pre-trained speech model Wav2Vec2.0 and language model RoBERTa, and a cross-modal encoder to extract contextual information from speech.
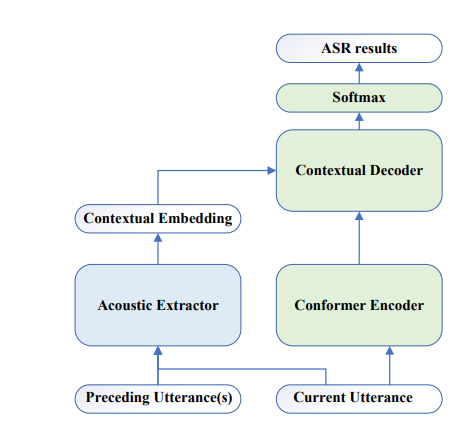
Figure 1: Diagram illustrating the proposed method, where speech sequences are the inputs.
The proposed conversational ASR system is trained in the following two stages:
Stage 1: In the first stage, the contextual representation extractor is trained, as demonstrated in Figure 2. The textual and audio embeddings are derived from paired speech and transcripts using the text encoder and the speech encoder, respectively. After that, the obtained embeddings are sent to a cross-modal encoder to extract the cross-modal representations. Using multitask learning, the representation extractor learns correlations between paired speech and transcripts in different data granularities.
Stage 2: The text encoder in the multi-modal representation extractor is repudiated in the second stage. Alternatively, the extractor learns the contextual representation from speech. During the training and testing of the ASR module, the contextual representations are incorporated into the decoder of the ASR module by the attention mechanism.
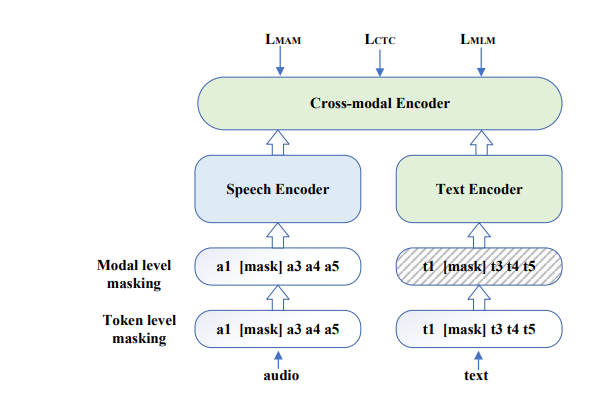
Figure 2: Diagram illustrating the proposed contextual representation extractor. (Source: Arxiv)
Furthermore, some input tokens and sequences of each modality are randomly masked. Then a modal-missing or token-missing prediction with a modal-level CTC loss on the cross-modal encoder is carried out. In this manner, the model captures the bi-directional context dependencies in a particular modality and the relationships between the two modalities.
Additionally, while training the conversational ASR system, the extractor is frozen to extract the textual representation of the preceding speeches; extracted representation is then used as context fed to the ASR decoder through the attention mechanism.
In the following subsection, we will briefly discuss each component:
i) Speech Encoder: The speech encoder consists of a pre-trained speech representation model ie. Wav2vec2.0 large model trained on WenetSpeech, and a linear layer.
ii) Text Encoder: The pre-trained language model RoBERTawwm-ext is used as the text encoder, which is trained on in-house text data, including news, encyclopedia, and question answering webs.
iii) Cross Model Encoder (CME): The cross model encoder comprises three transformer blocks. The speech embedding (A) and text embedding (T) obtained from the speech encoder and the text encoder, respectively, are sent into the CME to get high-dimensional cross-modal contextualized representations.
iv) Contextual Conformer ASR Model:
A) Conformer Encoder: Conformer combines self-attention with convolutions in ASR tasks, which learns the interaction of global information via the self-attention mechanism and also learns the representation of local features via a convolution neural network (CNN), leading to improved performance. Conformer blocks are stacked together as the encoder of the ASR model, where each conformer block comprises a convolution layer (CONV), a multi-head self-attention layer (MHSA), and a feed-forward layer (FFN).
B) Contextual Decoder: Contextual decoder consists of a transformer with an additional cross-sectional layer. First, the textual embeddings of the everyday speech, as well as previous speech, are generated. For this, the speech to be processed is sent to the extractor together, along with a dummy embedding. Then the current textual embedding with the previous contextual embedding is spliced to obtain the final contextual embedding. The obtained contextual embedding is fed into each decoder block to enable the decoder to learn the context information extracted by the textual extractor. Finally, the output of the last layer of the decoder is used for predicting the character probabilities via a softmax function.
Results
1. Effect of Acoustic Contextual Representation: Considering the results shown in rows 1, 3, and 5 in Table1, it can be inferred that the proposed method improves the recognition accuracy even when only the contextual representation of the current speech utterance Ai is extracted. The speech recognition performance is further improved after including the contextual representation of the previous speech utterance Ai−1 and the current speech utterance Ai simultaneously.
It should be noted that in the following Table 1, AcousticCur refers to the model that uses the textual embedding of the current sentence, AcousticCon refers to the model that uses the textual embeddings of current sentences and the previous sentences, and “ExtLM” denotes additional language models that are used in ASR decoding.
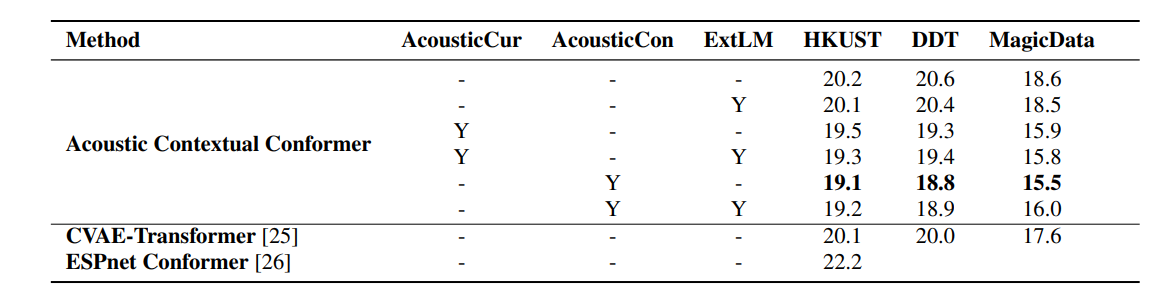
Table 1: CER comparison of various end-to-end models on three for Mandarin. (Source: Arxiv)
2. The Contextual Information of Wav2vec2.0: As illustrated in Table 2, even though the pre-trained Wav2Vec2.0 model improves recognition accuracy compared to the baseline model, the proposed method (AcousticCon) noticeably yields better results. This indicates that the proposed model utilizes the pre-trained model’s representation ability and successfully obtains the cross-modal textual representation.
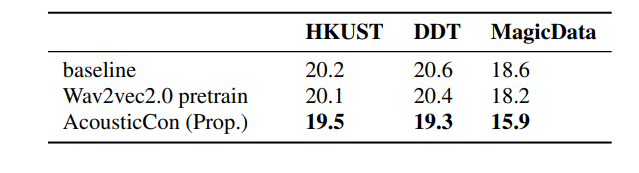
Table 2: CER comparison to Wav2vec2.0 pre-trained model (without LM)
3. The Length and Location of Historical Information: The performance of ASR models is typically influenced by the location and length of historical speech utterances used to extract contextual representations. The effects of history length and locations on HKUST and MagicData sets were investigated. From Table 3, it can be inferred that the more similar the sentence is to the current sentence, the more helpful it is to boost the recognition accuracy of the current sentence. However, inputting the textual features of the previous two sentences simultaneously doesn’t produce better results. This may be due to the decoder’s inability to learn appropriate concerns from the extensive historical data.
In the following table, AcousticConone refers to AcousticCon with the previous sentence, and AcousticContwo refers to AcousticCon using the penultimate sentence.
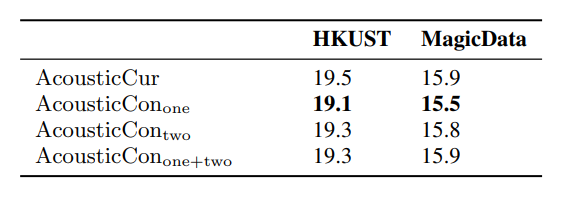
Table 3: A comparison of length and location based on historical information. (Source: Arxiv)
Conclusion
To sum it up, in this article, we learned the following:
1. Contextual information can be leveraged to boost the performance of the conversational ASR system. In light of this, a cross-modal representation extractor is proposed to learn contextual information from speech and use the representation for conversational ASR via the attention mechanism.
2. The cross-modal representation extractor was introduced, which comprises two pre-trained modal-related encoders, a pre-trained speech model (Wav2Vec2.0) and a language model (RoBERTa), extracts high-level latent features from speech and the corresponding transcript (text). And a cross-modal encoder that aims to learn the correlation between speech and text.
3. While training the conversational ASR system, the extractor is frozen to extract the textual representation of the preceding speech; extracted representation is then used as context fed to the ASR decoder via the attention mechanism.
4. The textual representation extracted from the current and previous speech is sent to the decoder module of ASR, which reduces the relative CER by up to 16% on three Mandarin conversational datasets (MagicData, DDT, and HKUST), as well as outperforms the vanilla Conformer model and the CVAE-Conformer model.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







