This article was published as a part of the Data Science Blogathon.
Introduction
Although artificial intelligence (AI) has made some impressive strides in recent years, it is evident that most of this development is confined to specific fields. Perhaps the least studied area is the realm of understanding known as `intuitive physics,’ which enables our pragmatic engagement with the physical world. Despite considerable effort, current AI systems have a poor understanding of intuitive physics than very young children. Inspired by the study of visual cognition in children, DeepMind researcher Luis Piloto, and his team taught a deep learning system called PLATO (Physics Learning through Auto-encoding and Tracking Objects) about the fundamentals of physics directly from visual data. After learning, PLATO can pick up simple physical rules about the behavior of objects and express surprise when they seem to violate those rules.

source: Industrywired
This article will look at the challenges encountered while developing the object-based PLATO model, the method overview, and the key findings obtained from the evaluation.
Now, let’s begin!
Highlights
-
DeepMind researcher Luis Piloto and his team taught a deep learning system, PLATO (Physics Learning through Auto-encoding and Tracking Objects), about the fundamentals of physics directly from visual data, using object-level representations.
-
PLATO depicts and reasons the world as a set of objects. It predicts where those objects will be in the future based on where objects have been in the past and what other objects they are interacting with.
-
When tested on a wide range of physical concepts, the model exhibits violation-of-expectation (VoE) effects and is highly dependent on the involvement of object-level representations.
-
Opensourced Physical Concepts dataset ports the VoE paradigm to evaluate five physical concepts: object persistence, continuity, solidity, “unchangeableness”, and directional inertia.
Challenges
Most people can easily use their critical skills to understand the physical world. This still presents a challenge for artificial intelligence, as we need these models to share our intuitive understanding of physics to deploy secure and helpful systems in the real world. But those models could be created. We must first address a different problem: how will we gauge how well these models comprehend the physical universe? Specifically, what does it mean to comprehend the physical world, and how can we evaluate/measure it?
Luckily, developmental psychologists have extensively researched what infants know about the physical world. Along the way, they’ve gradually transformed the hazy notion of physical knowledge into a concrete set of physical concepts. Additionally, they’ve developed the violation-of-expectation (VoE) paradigm to test those concepts in infants, which will be utilized in PLATO.
Method Overview
PLATO was created to learn the fundamentals of physics via tracking basic objects. PLATO was trained on 10s of hours of videos of objects, such as balls bouncing, falling, rolling, etc., and also versions that highlighted each object in the scene.
PLATO also analyzed numerical data from the videos to learn which pixel belonged to what object. These videos were supposed to teach PLATO physical concepts like solidity. However, many of them feature nonsensical circumstances and optical illusions.
Goal: To build a model capable of learning intuitive physics directly from visual data using object-level representations and dissect what enables that capacity.
To implement the object-centric approach, the model consists of two main components: a feedforward perceptual module (Fig. 1a-c) and a recurrent dynamics predictor with per-object memory (Fig. 1d). The perceptual module takes an image and segmentation mask as input and converts these into a vector embedding with the help of standard deep-learning auto-encoding methods (Fig. 1a-c and Methods). The perceptual module parses the high-dimensional visual input into a small set of discrete object codes.
On the other hand, the dynamics predictor is based on a structured recurrent neural network (RNN), called an InteractionLSTM (Fig. 1d: ‘IN’ and ‘LSTM’ boxes; Methods). This takes the history of single-frame object-level embeddings as input (Fig. 1, ‘object buffer’) and predicts the set of object codes at the next timestep (Fig. 1, ‘prediction’).
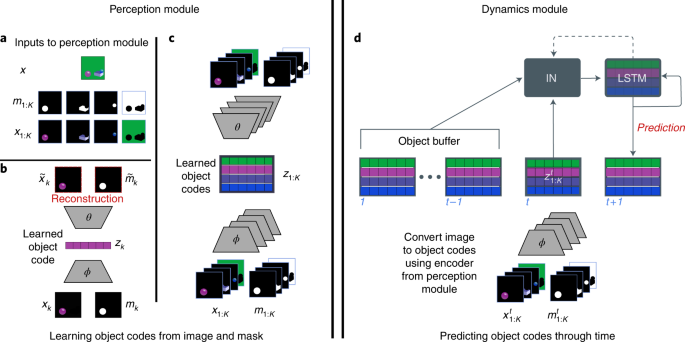
Fig. 1: PLATO makes per-object predictions using both a perceptual and a dynamics model.
At first, object individuation divides the continuous perceptual input of vision into a discrete set of entities, each of which has a unique set of characteristics. Each segmented video frame is divided into a set of object codes via a perception module (Fig. 3a–c), implementing a mapping from visual input to individuated objects.
Second, object tracking, also known as object indexing, assigns an index to the object, enabling a correspondence between object percepts across time and computation of dynamic properties (Fig. 1b,c).In PLATO, the object codes are accumulated and tracked in an object buffer across frames (Fig. 1d). Again, this is made possible by using ground truth segmentation masks, which provide correspondence between objects across frames.
The last piece is the relational processing of these tracked objects, which dynamically processes representations of objects, providing new representations that are directly inflected by their relationship to and interactions with other objects.
Then PLATO is trained on a next-step prediction task, and performance is evaluated on a suite of intuitive physics probes. The physical concept acquisition is quantified by comparing surprise on the two probe types.
Results
The results center on the following four key observations:
-
First, after training the object-based model, PLATO, on videos of simple physical interactions displayed robust VoE effects across all five concepts (continuity, directional inertia, object persistence, solidity, and unchangeableness), despite having been trained on video data in which the specific probe events were absent.
-
Second, it was found that the VoE effects in the model reduced or vanished in well-matched models that didn’t utilize object-centered representations.
-
Third, it was found that PLATO could learn the physical concepts, and reliable VoE effects could be attained with as little as 28 hours of visual training data.
-
Finally, the model’s behavior was assessed on unseen objects and events as a strong generalization test. It was noted that PLATO generalized well to an independently developed dataset involving novel object shapes and dynamics.
-
It learned patterns like continuity, which prevents objects from magically teleporting from one location to another; solidity, which stops objects from perforating; and persistence of the objects’ shape.
Conclusion
To summarize, in this article, we learned the following:
- PLATO was trained on 10s of videos showing simple mechanisms such as a ball rolling down a slope or two balls bouncing off one another, etc., which eventually gained the ability to predict how those objects would behave in various scenarios.
- PLATO represents and reasons about the world as a set of objects. It predicts where objects will be in the future based on where they’ve been in the past and what other objects they’re interacting with.
- The model consists of two main components to implement the object-centric approach: a feedforward perceptual module and a recurrent dynamics predictor with per-object memory.
- After training the object-based model, PLATO, on videos of simple physical interactions displayed robust VoE effects across all five concepts (continuity, directional inertia, object persistence, solidity, and unchangeableness), despite having been trained on video data in which the specific probe events were absent.
- It was found that PLATO could learn the physical concepts, and reliable VoE effects could be attained with as little as 28 hours of visual training data.
- It learned patterns like continuity, which prevents objects from magically teleporting from one location to another; solidity, which stops objects from perforating; and persistence of the objects’ shape.
- The physical concept acquisition is quantified by comparing surprise on the two probe types.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





