This article was published as a part of the Data Science Blogathon.
Introduction
Nowadays, it appears like everyone is working on artificial intelligence, but nobody ever discusses one of the most crucial components of every artificial intelligence project: Data labelling.
The people who are undertaking this time-consuming, boring task without the flare that usually encircles A.I. Without their dedicated work, it is impossible to develop algorithms, so I thought it is time to sing an ode to the superheroes of Artificial Intelligent development: Data annotators.
Artificial Intelligent technology is gradually encroaching on our daily lives, so data and its wise usage can greatly impact contemporary society.
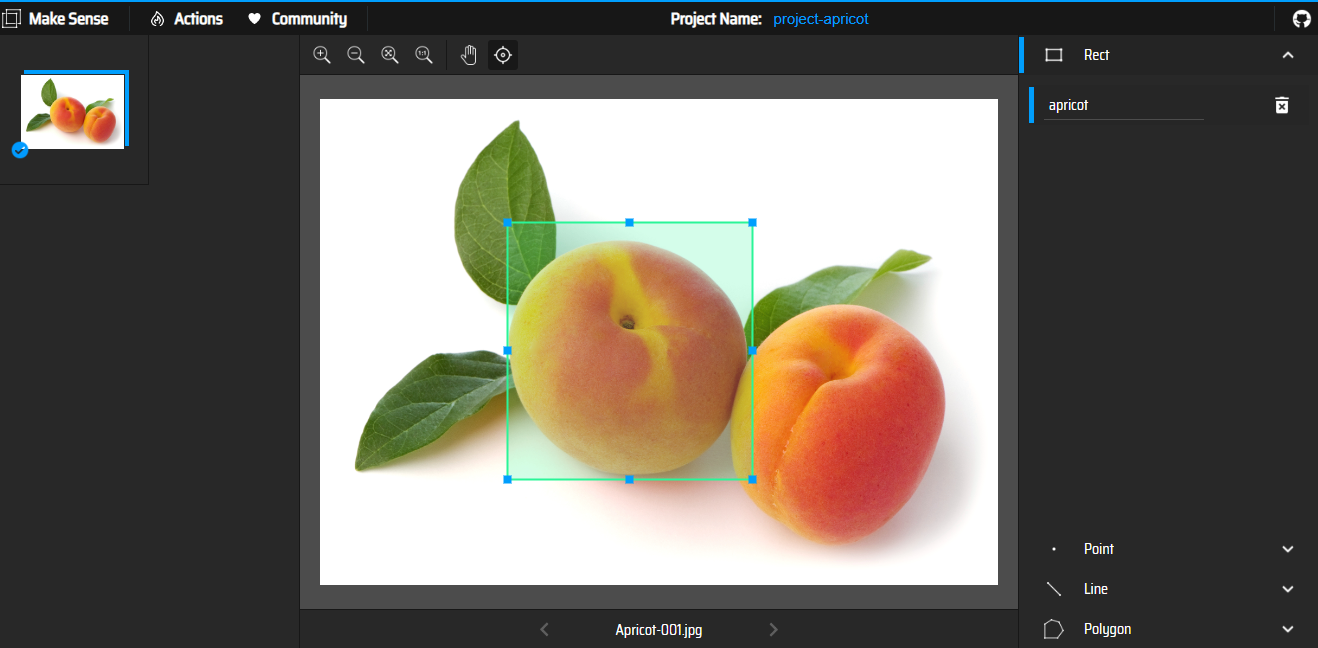
Source – Makesense.ai
What is data annotation/data labelling?
Data labelling or annotation in machine learning is the process of classifying unlabelled data (such as pictures, audio, videos, etc.) and adding one or more insightful labels to give the data context so that a machine learning model may learn from it. Labels might say, for instance, if a photograph shows a bird or an automobile, which words were spoken in an audio recording, or whether a tumour is visible on an x-ray. Data labelling is necessary for many use cases, such as computer vision, natural language processing, and speech recognition.
Without humans labelling what’s in a picture, how to recognize music or how to read the text in different languages, even the most advanced Artificial Intelligent algorithms are useless. For machines to successfully engage with our human environment, human data annotators put in a lot of effort.
Data Labelling — Function
Nowadays, supervised learning is used in most real machine learning models, using an algorithm to map one input to one output. A labelled collection of data that the model can learn from and use to make wise judgments is necessary for supervised learning to function. A common starting point for data labelling is to solicit opinions from people regarding a certain set of unlabelled data.
Labellers might be required, for instance, to tag all the pictures in a collection with the value true for “does the picture contain a bird.” The tagging might be as basic as a yes/no question or as detailed as identifying the precise pixels in the bird’s image. In a process known as “model training,” the machine learning model employs labels provided by humans to discover the underlying patterns.
For example,
 Source – https://www.petsittersireland.com/cat-sitter-dublin/
Source – https://www.petsittersireland.com/cat-sitter-dublin/
Let’s say you want to have an algorithm to spot cats in pictures.
It sounds easy, right?
You describe it as a furry animal with two eyes. You describe its size, colour and how its cheek looks. But a computer doesn’t understand legs,
eyes, or what fur is in the first place. That’s where annotators come in. You will need millions of photos, where those photos that have a cat in them are appropriately labelled as having a cat.
That way, a neural network can be trained through supervised learning to recognize pictures with cats in them. So, you won’t tell the algorithm what a cat is, but you feed it with millions of examples to help it figure it out by itself.
What are some typical data labelling formats?
According to what we’ve seen so far, data labelling mostly concerns the task we want a machine-learning system to carry out using our data. These popular artificial intelligence domains are included with appropriate data annotator types.
Natural Language Processing:
To create your training dataset for natural language processing, you must first manually pick out key text passages or classify the text with particular labels. For instance, you could wish to classify proper nouns like locations and people, identify parts of speech, determine the sentiment or meaning of a text blurb, and recognize text in photos, PDFs, or other media.
To accomplish this, you can manually transcribe the text in your training dataset after drawing bounding boxes around it. Sentiment analysis, entity name identification, and optical character recognition all use natural language, processing models.
Computer Vision :
To develop a training dataset for a computer vision system, you must first label images, pixels, or key spots or draw a bounding box around a digital image. Images can be categorized in a variety of ways, such as by content (what is really in the image), quality (such as product vs lifestyle images), or even down to the pixel level. Then, using this training data, you can create a computer vision model that can be used to automatically segment an image, locate objects in an image, identify key points in an image, and categorize images.
Audio Processing:
All types of sounds, including speech, animal noises (barks, whistles, or chirps), and construction noises (breaking glass, scanners, or alarms), are transformed into structured formats during audio processing, so they can be employed in machine learning. It is frequently necessary to manually convert audio files into text before processing them. The audio can then be tagged and categorized to reveal more details about it. Your training dataset is this audio that has been categorized.
What methods can be used to efficiently label your data?
Large amounts of high-quality training data serve as the foundation for effective machine learning models. However, the procedure for gathering the training data required to develop these models is frequently expensive, challenging, and time-consuming. For the vast majority of models developed today, data must be manually labelled by a human for the model to develop the ability to make wise decisions. This problem can be solved by utilizing a machine learning model to automatically label data, which will increase the efficiency of labelling.
A machine learning model for labelling data is first trained on a portion of your raw data that humans have already annotated in this process. Based on what it has discovered thus far, the labelling model will automatically attach labels to the raw data in situations with high confidence in its outcomes. The data will be given to humans to label in cases where the labelling model is less confident in its findings. The labelling model is then given the human-generated labels, so it can learn from them and become better at automatically labelling the subsequent set of raw data. The model can gradually label an increasing amount of data automatically and greatly speed up the production of training datasets.
Conclusion
Almost all AI algorithms operate under the presumption that the real-world data they are given is 100 per cent true. Human error in data annotation frequently prevents these models from operating at their peak capacity, lowering prediction accuracy as a whole.
Thus, one of the main obstacles to the widespread adoption of AI in companies is the labelling and annotation of data. An important component of every successful ML project is accurate and thorough data annotation, which may bring out the best in any ML model.
Some of the key takeaways from the article are:
- We gained knowledge of Data Annotation and its Components of Data Annotation.
- We take in the fundamentals of Data Annotation.
- We gained knowledge about how to choose the annotation method for our case.
Thanks for reading!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm Parthiban and I have more than one year experience in Machine Learning and Deep Learning. A Mechanical Engineering enthusiast with the passion to learn more about Machine Learning and emerging technology in the world. Study and transform data science prototypes and Design machine learning systems. Research and implement appropriate ML algorithms and tools. Develop machine learning applications and select appropriate datasets and data representation methods. Perform statistical analysis and fine-tuning using test results, and extend existing ML libraries and frameworks.






