Tokenizer-free Language Modeling with Pixels
This article was published as a part of the Data Science Blogathon.
Introduction
Tired of tokenizers or subwords? Check out PIXEL (Pixel-based Encoder of Language), a pre-trained language model that effectively eliminates the need for a tokenizer by processing text as images, allowing for the transfer of representations across languages based on orthographic similarity or pixels co-activation.
In this article, we will delve deeper into “Language modeling with Pixels,” the idea originally proposed by Phillip Rust et al.

Source: Canva|Arxiv
Highlights
-
A tokenizer-free pre-trained language model, PIXEL, render text as images, which makes it possible to transfer representations across languages based on orthographic similarity or the co-activation of pixels.
-
PIXEL model reconstructs the pixels of masked patches rather than predicting a distribution over tokens.
-
PIXEL model is trained on the same English data as BERT and evaluated on syntactic and semantic tasks in typologically diverse languages, including non-Latin scripts.
-
PIXEL outperforms BERT on syntactic and semantic processing tasks on scripts that are not present in the pretraining data, but PIXEL is slightly weaker than BERT when dealing with Latin scripts.
-
PIXEL is more resilient to noisy text inputs than BERT, further confirming the effectiveness of modeling language with pixels.
Why is a PIXEL-like Model Needed?
Language models are usually defined over a finite set of inputs, which entails a vocabulary bottleneck when attempting to scale the number of supported languages. Addressing this bottleneck results in a trade-off between what can be represented in the embedding matrix and computational challenges in the output layer.
Method Overview
Pixel-based Encoder of Language (PIXEL) is built on the Masked Autoencoding Visual Transformer (ViT-MAE). ViT-MAE is a Transformer-based encoder-decoder model trained to reconstruct the pixels in masked image patches. It comprises three key components: a text renderer, which draws text as an image; an encoder, which encodes the unmasked regions of the rendered image; and a decoder, which reconstructs the masked regions at the pixel level (See Fig. 1).
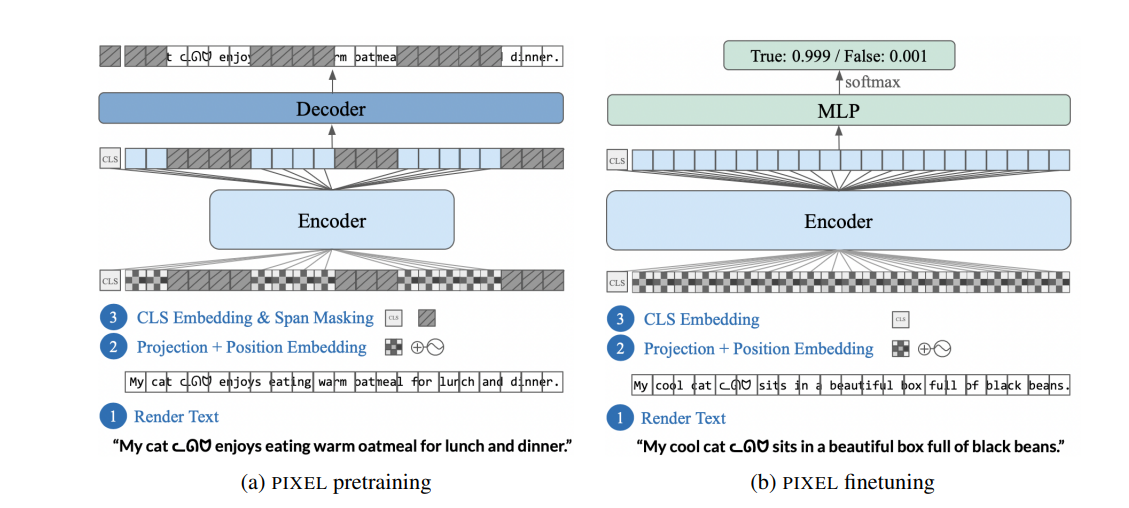
Figure 1: Overview of PIXEL’s architecture (Source: Arxiv)
PIXEL does not have a vocabulary embedding layer; rather, it renders text as a sequence of fixed-sized patches and processes the patches using a Vision Transformer encoder. PIXEL also doesn’t need a computationally expensive output layer when it reconstructs the pixels of the masked patches. In essence, PIXEL eliminates the bottleneck constraint without paying the cost of absurdly long sequences.
The key objective behind training the PIXEL model is to reconstruct the pixels of masked patches instead of predicting a distribution over tokens. PIXEL model is trained on the same English data as BERT and is evaluated on syntactic and semantic tasks (like part-of-speech tagging, question answering, dependency parsing, language understanding tasks, etc.) in typologically diverse languages, including various non-Latin scripts.
One advantage of this approach is that it can handle different languages, emojis, etc., without the embedding tables’ size exploding; this approach doesn’t include any pre-defined vocabulary.

Figure 2: Examples of the rendered text. (Source: Arxiv)
Figure 2 illustrates that most writing systems, color emojis, and complicated text layouts such as right-to-left writing and ligatures are natively supported by PIXEL. Black patches act as separators and end-of-sequence (EOS) markers. And the blank patches to the right of the EOS marker are treated as sequence padding. For word-level tasks, horizontal spacing is augmented such that each image patch is assigned to exactly one word.
PIXEL can be finetuned for downstream NLP tasks just the way BERT-like encoders are fine-tuned by just replacing the PIXEL decoder with a suitable classification head. Moreover, by truncating or interpolating the sinusoidal position embeddings, we can finetune with sequences shorter or longer than 529 patches, respectively.
Note that the PIXEL decoder doesn’t have to compute an expensive softmax over a subword vocabulary and doesn’t even need the subword embedding weights. PIXEL is trained using a normalized mean squared error (MSE) pixel reconstruction loss which measures the discrepancy between normalized target image patches and reconstructed patches. This loss is only calculated for masked and non-blank (text) patches.
Gradio Demo for PIXEL
The researchers have also created the following Gradio demo for PIXEL (See GIF), which is hosted on Hugging Face Spaces. To gain insights into the effectiveness of the proposed model, you can play with the examples or just simply input any text of your choice. You can also try tweaking the hyper-parameters like “Span masking ratio,” “Masking span length,” and “random seed.”
If I were to share my opinion, I would be quite impressed with this model. Although a few masked words were not correctly predicted, I’m fascinated by the idea of processing text as images, and considering that this method is still nascent, I give it a thumbs up!
.gif)
Link to the Gradio demo: https://huggingface.co/spaces/Team-PIXEL/PIXEL
Results
PIXEL was fine-tuned on various common NLP tasks. It was evaluated for its syntactic and semantic processing abilities in English, as well as its adaptability to unseen languages, and the evaluation results are as follows:
i) Syntactic Tasks: Table 1 shows POS tagging and dependency parsing results. In the monolingual setting (ENG), BERT performed slightly better than PIXEL. However, PIXEL outperformed BERT in the remaining languages.
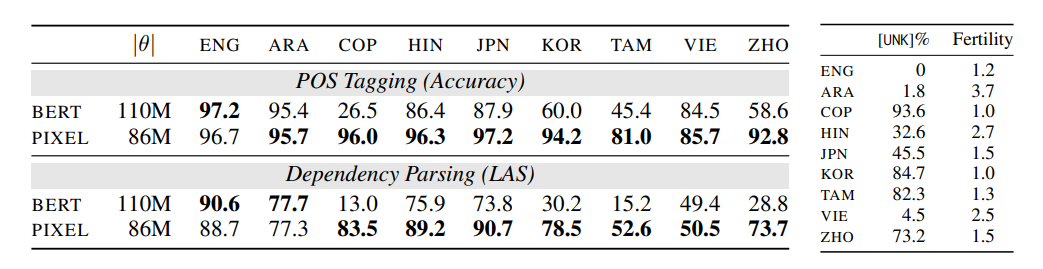
Table 1: Evaluation outcomes for PIXEL and BERT fine-tuned for POS tagging and dependency parsing on various Universal Dependencies treebanks.
ii) Semantic Tasks: The results for the NER task are presented in Table 2. It was noted that BERT consistently outperformed PIXEL in their pretraining language ENG. Likewise, this observation holds even for the languages that use the Latin writing system. Notably, all the languages considered for evaluating PIXEL on the NER task except AMH use Latin script.

Table 2: Evaluation results for PIXEL and BERT fine-tuned for NER
Furthermore, for languages like KOR, JPN, and TEL in QA, where BERT only partially covers the script, PIXEL consistently outperformed BERT, sometimes by notable margins. For cases where BERT doesn’t cover certain languages, BERT completely fails whereas PIXEL outperforms for the most part. In other words, PIXEL overcame the vocabulary bottleneck of subword-based pre-trained language models (PLMs) in semantics-driven tasks.

Table 3: Evaluation results for PIXEL and BERT fine-tuned on extractive QA datasets.
iii) Orthographic Attacks: Informal text, commonly used on social media, often includes orthographic noise, such as typos and other variations. To evaluate PIXEL’s robustness to textual noise and variation, researchers experimented with the Zeroé benchmark, which covers a variety of low-level orthographic attacks, as shown in Table 4.
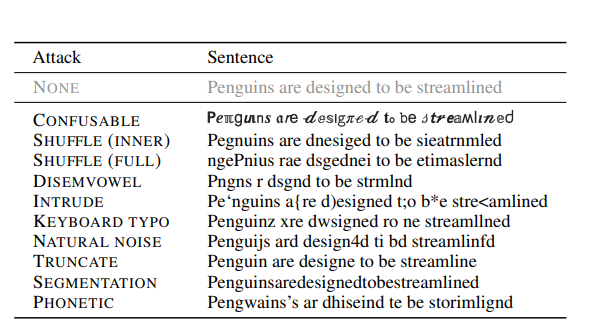
Table 5: Examples of low-level orthographic attacks (Zeroé benchmark)
The findings (as shown in Figure 4) demonstrate that PIXEL is more resistant to most of these attacks than BERT.
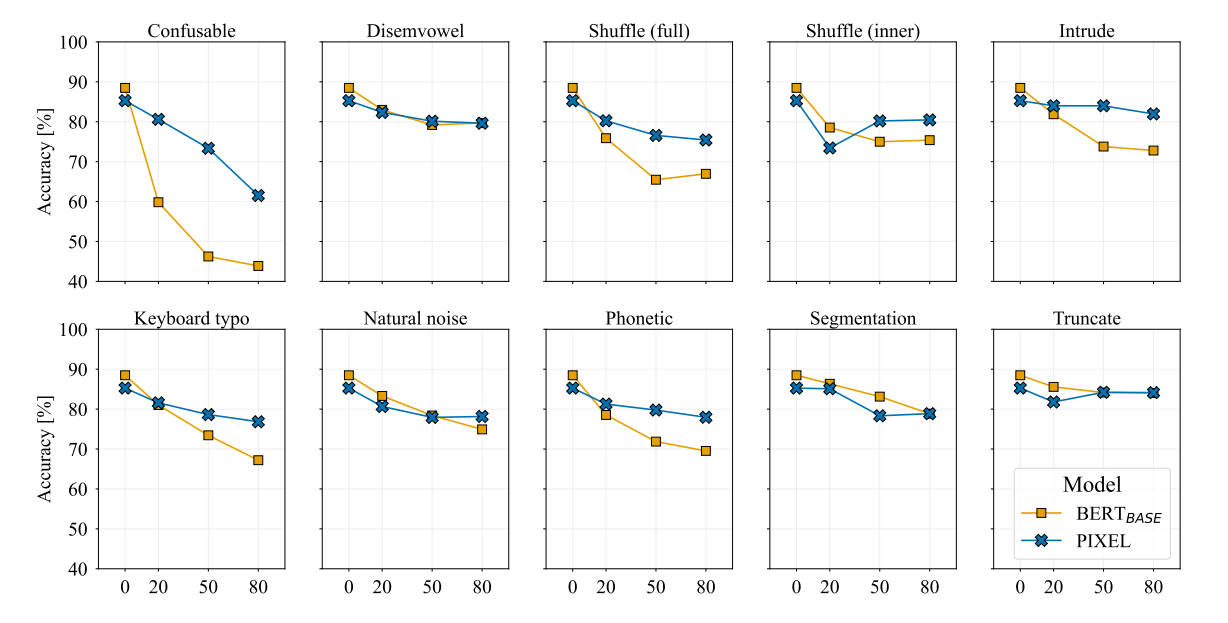
Figure 4: Graphs illustrating the test set accuracy for a single run of PIXEL and BERT across varying noise levels introduced via various orthographic attacks in SNLI.
Limitations
1. PIXEL is primarily pre-trained on English text written in the Latin script. However, English may not be the best source language for cross-lingual transfer.
2. PIXEL appears to be less sample-efficient than subword-based pre-trained language models like BERT. PIXEL performs well at syntactic tasks after being pre-trained for the same number of steps/data points as BERT; however, it still falls short on semantic tasks.
3. Working with languages written right to the left presents some difficulties. The way that PIXEL currently interprets sentences in these languages from the end to the beginning could cause it to learn features that are inadequate for sentence separation and position embeddings.
4. PIXEL can’t be used for language generation tasks since it is not possible to generate discrete words from the pre-trained decoder.
5. Reading text from a file requires less disc space than rendering text as images. This can be circumvented by caching the dataset in a compressed format or rendering the images on the fly. However, rendering images on the fly creates additional overhead when training for multiple epochs.
Conclusion
To sum it up, in this article, we learned the following:
1. A tokenizer-free pre-trained language model, PIXEL, renders texts as images, that allow representing any written language that can be typeset using its text renderer.
2. PIXEL model is trained on the same English data as BERT and is evaluated on syntactic and semantic tasks (like part-of-speech tagging, question answering, dependency parsing, language understanding tasks, etc) in typologically diverse languages, including various non-Latin scripts.
3. Although PIXEL readily adapts/transfers to unseen scripts, it performs worse than BERT when processing languages written in the Latin script, including English. However, PIXEL is more resistant to low-level orthographic attacks than BERT. This suggests that pixel-based representations offer a strong foundation for cross-lingual and cross-script transfer learning.
4. The subword embedding weights and an expensive softmax computation are not necessary for the PIXEL decoder to function. PIXEL is trained with a normalized mean squared error (MSE) pixel reconstruction loss measuring the discrepancy between normalized target image patches and reconstructed patches.
5. One advantage of the proposed method is that it can handle different languages, emojis, etc., without the embedding tables’ size exploding; this approach doesn’t include any pre-defined vocabulary.
That concludes this article. Thanks for reading. If you have any questions or concerns, please post them in the comments section below. Happy learning!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







