This article was published as a part of the Data Science Blogathon.
Introduction
A graph database is a specialized, one-of-a-kind platform for creating and manipulating graphs. Graphs have nodes, edges, and properties that represent and store data in ways relational databases cannot.
Another commonly used term is graph analytics, which refers to analyzing data in a graph format using data points as nodes and relationships as edges. A database that can support graph formats is required for graph analytics. It could be a dedicated graph or a converged database that supports multiple data models, including graphs.
What is Graph?
A graph in the context of computing comprises of two elements: a node and a relationship. Each node represents an entity, such as a person, place, thing, category, or piece of data. This general-purpose structure enables you to model a wide range of scenarios, from a road system to a network of buildings.
From devices to a population’s medical history, relationships define everything. For example, consider Twitter, which has 30 million users and is still growing. The image depicts a graph.
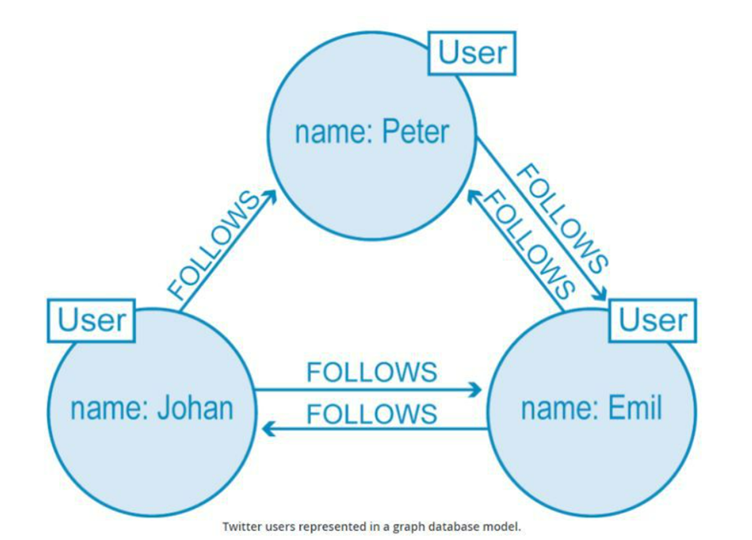
Source – codingnote.cc
A representation of a few users and their interactions.
Even though Leonhard Euler presented the fundamentals of graphs in his solution to the famous Königsberg bridge problem, the abstraction of problems to edges (relationships) and numbers (nodes) piqued mathematicians’ interest in using this intuitive method to solve complex problems.
It is now one of the most complicated branches of mathematics.
What is Graph Database?
As the name implies, a graph data store is any database that uses basic graph principles to store and process data in the form of nodes and relationships. Relationships take precedence in a graph data store. As a result, the schema and actual data are tightly coupled. A graph data store’s flexibility allows it to easily add new domain objects, relationships, and properties without compromising the existing setup.
A graph database’s data model is significantly simpler and more expressive than a relational or other NoSQL database. In the realm of graphs, relationships are first-class citizens, and the entire system revolves around the efficiency of storing, maintaining, and traversing relationships. In the real world, which is densely packed with interconnected data, graph data stores provide a framework and paradigm that intuitively mimic semantic relationships.
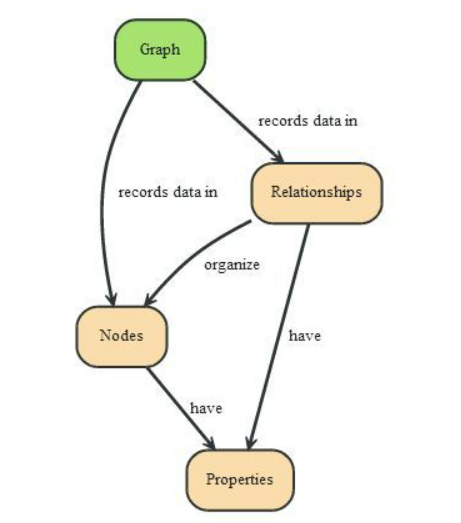
Source – codingnote.cc
Technically, a native graph database differs from other databases in the following ways:
Graph Storage
A graph database’s storage is highly optimized for storing nodes and relationships. Graph data, for example, is stored in Neo4J in store files, each of which contains data for a specific part of the graph, such as nodes, relationships, labels, and properties. This method of dividing the storage allows for highly performant graph traversals. Native graph storage is designed from the ground up to handle highly interconnected data sets, making it the most efficient for storing and retrieving interconnected data.
Figure 2: Conceptual Illustration of Native Graph Storage (Neo4J). Please note that APIs and Transaction Management are built directly on disc storage, making them lightning fast.
Graph Processing Engine
The graph engine uses highly optimized storage, with connected nodes physically pointing to each other. This is known as “index-free adjacency.” During the data load in an index-free adjacency world, each node stores the pointer (RAM location) of the adjacent node. As a result, no additional address resolution is required.
In the diagram above, we can get from A to B directly. However, in RDBMS or NoSQL, the address is resolved at run time using third-party indexes, making it a query time variable. So, to get to D from C, we must first determine where D is located using index resolution and then proceed to D.
Why are Graph Databases Used?
The graph data store is well-suited for storing, analyzing, and leveraging relationships. When used at scale, this opens up a slew of possibilities that would be impossible to realize with traditional “relational” technologies. A graph database is designed specifically to handle highly connected data and can handle all of the problems listed above. Because of the graph’s following characteristics, businesses have begun to warm up to it.
Simplicity: You Model Exactly What You Want
The graph provides a data storage method that is independent of implementation. What you write down is what you save in the database. They offer data modeling flexibility based on relationships. From highly constrained relational databases to graphs with no rules, it is a significant step toward enabling business users to solve actual problems. Graph data stores can add as much or as little semantic meaning as required by the domain or business. This can happen without considering constraints such as normalization or data restructuring via denormalization.
Flexibility
Graph not only allows for model flexibility, but it also aids in database evolution. Users can add or remove a new entity or relationship, extend a model to integrate a new business, or evolve the existing model intuitively.
Operations and Analytics: Operations and analytics support
Because the graph data store is designed not to touch unrelated data, it is optimized to support transactional operations. The graph structure facilitates integration with out-of-the-box algorithms along with standard CRUD operations. With data relationships at their core, graphs are incredibly efficient in query speed, even for deep and complex problems. Graphs are rapid to find all associated relationships and related information because they do not have to scan entire tables to find relations.
Example
Suppose we want to find out which department Alice, an employee of a company, belongs to.
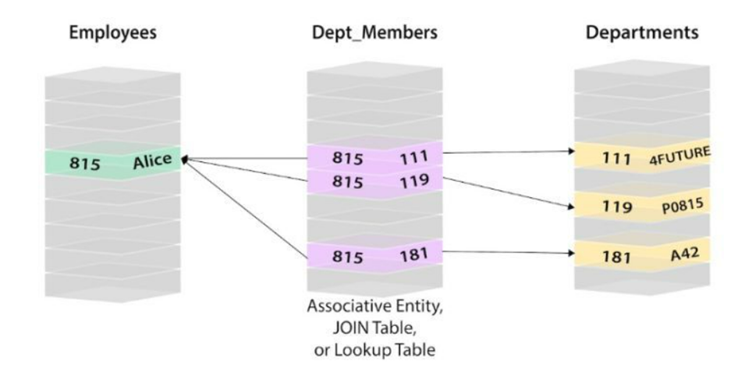
Source – codingnote.cc
In a relational database, it is generally necessary to establish an employee information table, an employee and department correspondence table (assuming that an employee can belong to multiple departments), and a department information table. There are 3 steps to find:
A, first find the corresponding work number of Alice through the employee information form;
B, and then use the work number to find its corresponding department ID in the relationship table;
C. Finally, use the department ID to find the department name and other information in the department information table.
A needs an index lookup process, B also needs an index lookup, and C may need 3 index lookups. Suppose it is a large company with tens of thousands or even hundreds of thousands of employees. In that case, the records of the corresponding tables of employees and departments will be extensive, and the search efficiency of B will be much lower than that of A and C.
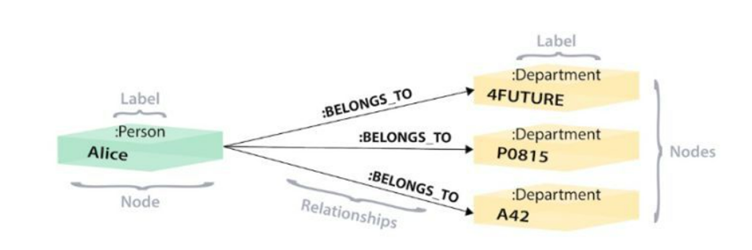
Source – codingnote.cc
However, there is no need for such a complex query in the graph database. This is precise because graph databases are modeled differently than relational databases or how data is stored. In the diagram database, employees and departments are in the same diagram, directly through edges to establish relationships. There are also 3 steps when looking up:
- First, find the node Na corresponding to Alice by establishing a global index (which can be sparse) on the employee tag Person;
- Find the corresponding department through the side of the Na node saved by the label BELONGS_TO;
- Read the department information.
Although it can also be divided into 3 steps, the efficiency is very different. The efficiency of a is equivalent to A; b No need to do index lookup; directly through the Na node to get, although the Na node may have a lot of different labels of the edge, with the number of records in the employee and department relationship table is certainly not an order of magnitude, and through the Na to find the edge can also go to the Na node of the local index to speed up the lookup; For graph databases such as Neo4J that support index-free adjacencies, Na points directly to the physical addresses of 3 department nodes, and for other non-native graph storage databases, such as JanusGraph, you need to look for the global index established on the department label Department.
Conclusion
The graph is the way to go if you have highly connected data and your business problem takes advantage of this connectivity. Even though graph has been around for centuries, Graph Databases have only recently begun to gain traction. The graph has several advantages over traditional data stores (RDBMS and NoSQLs) and is highly optimized to leverage relationships. Owing to its index-free adjacency, it is lightning fast for traversal problems, super flexible to support evolving business needs, and comes with a set of predefined ml algorithms.
Some takeaways:
1. It is all about Relationships
There are numerous approaches to querying data, but one of the most intriguing is to see how various pieces of data are connected and what relationships exist among the data. One of the strengths of graph databases is in this area.
2. Speedy Performance
Performance is one of the primary reasons developers prefer graph databases. A graph database will outperform nearly every existing out-of-the-box database for certain big data problems, particularly those that involve analyzing the relationships between millions or billions of entities.
3. Semantics Matter
Semantics are central to the work of graph databases, particularly those that follow the World Wide Web Consortium’s (W3C’s) Resource Description Framework (RDF) specification.
Thank you for reading! I’ll be posting monthly content on Data Engineering.
Please comment on the post with your feedback, it will help me improve! 🙂
Until next time, Keep asking questions & Keep learning!
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I have 4+ years of working experience working with Big Data Analytics and the Cloud. Worked with different domains like Capital Markets, Insurance, FinTech, MedTech/Healthcare. Have designed scalable & optimized data pipelines for mostly Batch Processing Utilizing Cloud.
✔️ Building data warehouses /Data lakes using modern cloud platforms and technologies.
✔️ Implementing and automating data pipelines, ETL processes.
✔️ Data Cleaning, Processing, and Standardization (Machine Learning and NLP).
✔️ Data Migration (Heterogenous and Homogenous)
Some of the technologies I most frequently work with are:
👨💻 Programming: Python, PySpark, SQL, Pandas
☁️ Cloud: AWS
🔰 Databases: Redshift, RDS, PostgreSQL, MySQL, S3, Cloud Data Store
⚙️ Data Integration/ETL: AWS Glue & EMR, Airflow
📊 BI/Visualization: Tableau, Excel
🤖 Big Data - Hadoop, Hive, Spark, NLP, Jupyter Notebook, Data Structures
I love to adapt to new technologies to solve different business problems. I want to work with Petabytes of real-time/Streaming/Batch data and build good platforms. Looking forward to exploring.






