Today, organizations increasingly harness graph analytics to glean insights from vast, intricate data sets. Neo4j, a leading graph database, empowers developers and data scientists with potent tools for building intelligent applications and workflows. This guide aims to aid beginners in Neo4j, from fundamentals, install neo4j to practical concepts. It defines key terms and provides a code example for Neo4j installation and setup. Prior knowledge of Database Systems and Graph Theory is recommended.
This article was published as a part of the Data Science Blogathon.
Table of contents
- What is a Neo4j / Graph Database?
- Why Graph Database or Neo4j?
- Relational Database vs. Graph Database
- Advantages Of Neo4j
- Features Of Neo4j
- Neo4j Property Graph Data Model
- How To Install Neo4j On Ubuntu?
- Start Neo4j Service
- Testing and Working With Neo4j
- Neo4j CQL: Clauses, Functions, Datatypes, and Operators
- Conclusion
- Frequently Asked Questions

What is a Neo4j / Graph Database?
Neo4j is a highly scalable graph database management system, purpose-built for storing and traversing relationships in computing. It replaces tables or documents with nodes and relationships in a graph structure for semantic queries.
Key Points
- Node-Based Data: Neo4j stores data entities (e.g., users, companies) as nodes.
- Relationship Clarity: Edges represent relationships, making data relationships easily understandable.
- Flexibility: Data is stored without a predefined model, enabling adaptable analysis.
- Relationship Variety: Nodes can have multiple relationships, while edges have start and end nodes, type, and direction.
- Common Use Cases: Organizations use Neo4j to extract precise insights from complex queries involving customer and user data.”
Why Graph Database or Neo4j?
In today’s rapidly evolving tech landscape, companies grapple with vast data volumes. Extracting insights and identifying connections within data are paramount. To address this, companies need a database technology that treats relationship details as a primary entity for maximizing data relationships.
Although existing relational databases can manage these relationships, their performance in handling data relationships remains subpar. The solution to many business needs lies in graph databases. They store relationships alongside nodes (data elements) in a more efficient, flexible format. They excel in swiftly navigating data, making them ideal for adapting to evolving business requirements.
Relational Database vs. Graph Database
If you are still stumbling to find the answer to “How does a relational database differ from a graph-based database, the below difference table will help you understand it in a better way:
| Relational Database | Graph Database | |
| Format | It has tables with rows and columns. | It has nodes and edges showing relationships among each other. |
| Relationships | Relationships are connected across tables where they are established using foreign keys between tables. | Considering data, the relationships are represented between edges and nodes. |
| Complex Queries | Relational databases require complex joins between tables. | Graph databases operate quickly and do not require joins. |
| Top Use-Cases |
Relationational databases are widely adopted for transaction applications such as online transactions and accountings.
|
Graph databases are mainly used for relationship-heavy use cases, including fraud detection and recommendations engines.
|
Advantages Of Neo4j
As we all know Graph database is the solution to make rapid progress on mission-critical enterprises. Still, there is a list of benefits of using Neo4j. We are going to study that now:
- It has a simple, flexible, and robust data model. It can be effortlessly adjusted according to your application needs and business demands.
- It delivers results based on real-time data.
- It offers high availability for big company real-time applications with transactional contracts.
- Neo4j is a schema-free database and provides a straightforward representation of connected and semi-structured data.
- Using Neo4j, you can represent and easily retrieve (traverse/navigate) connected data faster than other databases comparatively.
- Neo4j feeds a declarative query language (Cypher Query Language) to illustrate the graph visually employing ASCII-art syntax. The commands of this language are straightforward to understand and are humanly readable.
- Neo4j is fast because more interconnected data is straightforward to retrieve and navigate.
- Using Neo4j does not need complicated joins to retrieve connected/related data. It is straightforward to retrieve its neighboring node or relationship attributes without joins or indexes.
- Neo4j provides higher vertical scaling, improved operational characteristics, higher concurrency, and simplified tuning.
Features Of Neo4j
To summarize, until now, we have seen what Neo4j is. Why is Neo4j so popular? Difference between Neo4j and relational database management system, and advantages of Neo4j as a widely used graph database across all enterprises and businesses.
In this section, we will examine a list of significant features of Neo4j:
Data Model With Flexible Schema
Neo4j adheres to the property graph model as its data model. The graph comprises nodes representing entities, and these nodes are interconnected through relationships. Both nodes and relationships store data in key-value pairs, referred to as properties. Neo4j imposes no fixed schema, allowing you to add or remove properties based on your requirements. Additionally, Neo4j provides schema constraints for enhanced data management.
ACID Properties
Neo4j supports rich ACID properties:
- A: Atomicity
- C: Consistency
- I: Isolation
- D: Durability
Scalability & Reliability
Neo4j allows you to scale the database by increasing the number of reads/writes operations and the volume without impacting the query processing speed and data integrity. It also furnishes permission for replication for data protection and reliability.
Built-in Web applications
Neo4j also offers a built-in Neo4j browser web application that can be utilized to construct and retrieve your graph data.
Indexing & GraphDB
Neo4j sustains Indexes by employing Apache Lucence & follows Property Graph Data Model.
Some Other General Features
- It provides REST API to work with programming languages such as Java, Spring, Scala, etc.
- It supports UNIQUE constraints and uses native graph storage along native GPE(Graph Processing Engine).
- It provides Java Script to work with UI MVC frameworks such as Node JS.
- Cypher API and Native Java API are the two types of Java API supported by Neo4j. Using these APIs, you can develop robust Java applications.
- In addition to these, Neo4j supports exporting query data to JSON and XLS format to work with other databases such as MongoDB or Cassandra.
Neo4j Property Graph Data Model
As we saw in the features section, Neo4j follows a property graph data model to store and manipulate its data. This section will discuss some of the critical features and central building blocks of the property graph data model, which are:
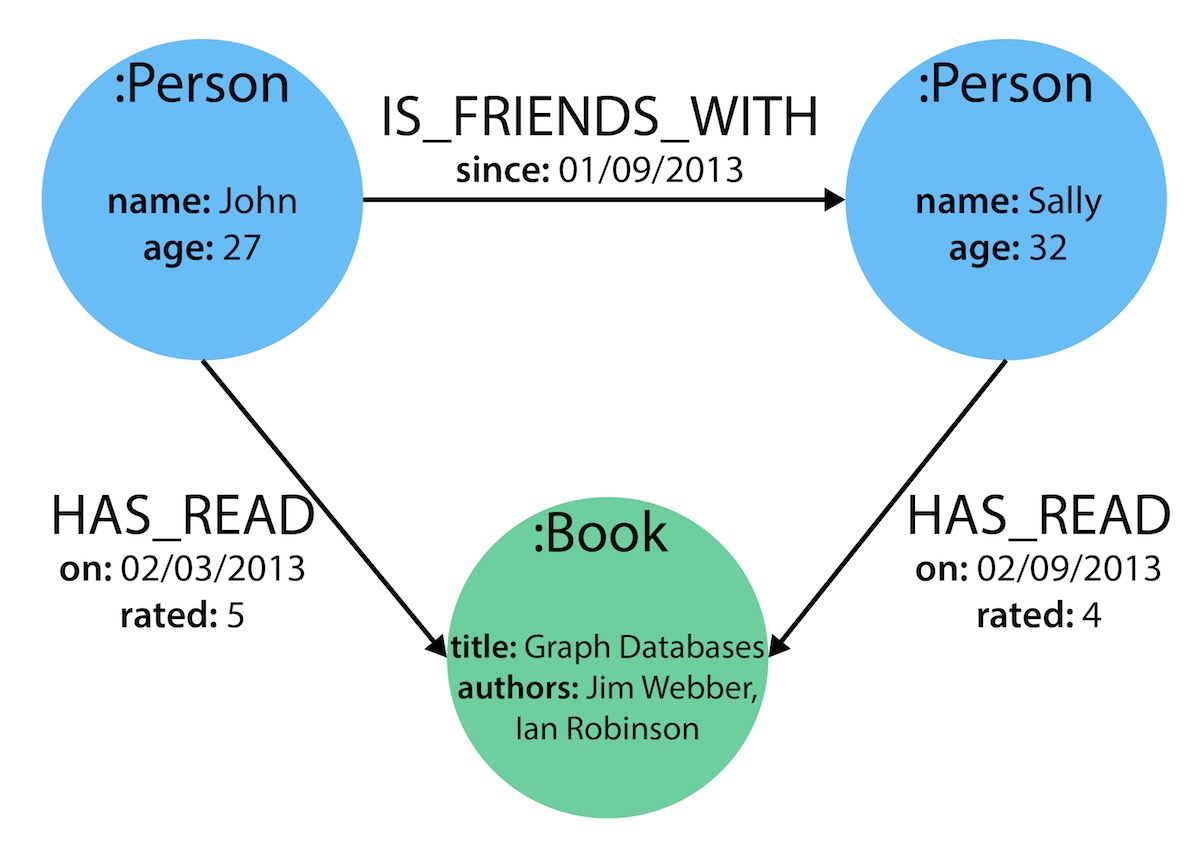
Nodes
- First, it is essential to know that a graph data structure consists of nodes (data entities or discrete objects) represented by relationships.
- Nodes can have one or more labels to classify their nodes and are represented using circles.
Relationships
- Relationships represent a link between a source node and a target node. They can be Unidirectional and Bidirectional only (that means it always has a direction). It is only denoted using arrow keys.
- Relationships must have a type to classify their ties, i.e., “Start Node” or “From Node” and “To Node” or “End Node.”
Properties
- Nodes and relationships can have properties where they are key-value pairs, further describing them.
How To Install Neo4j On Ubuntu?
This section will explain installing and configuring the Neo4j on Ubuntu 20.04 server.
Prerequisites
For setting-up Neo4j, the following setting is recommended:
- 1GB Ram, 15GB of free storage, and a single-core server
- All commands should be run in root mode. If you are not in root mode, controls must be followed by the Sudo command. In this tutorial, we will be using the sudo command for your ease.
- Ubuntu 20.04
Install Neo4j
The official Ubuntu package repositories do not officially include Neo4j in the standard package repository. To install the upstream supported package from Neo4j, we will add the package source pointing to the location of the Neo4j repository. Then we will add the GPG key from Neo4j for confirmation. After that, we will install Neo4j.
Step 1: We start by updating the existing list of packages.
Command

Step 2: Install neo4j packages
This step will install a few prerequisite packages for HTTPS connections to secure the installation. This application may be already installed in your systems by default. Still, it is safe to run the following command anyways.
Command

Step 3: Add security GPG key
We will add the security GPG key for the official Neo4j package repository in this step. This key will confirm that you can trust what you are installing is from the official Neo4j upstream repository.
Command

Output
OK
Step 4: Add the Neo4j repository to your system’s package manager list.
Command

Step 5: Install the Neo4j package
The final phase in this module is to install the Neo4j package and all of its dependencies. It is necessary to mention that this installation will also download and install a compatible Java package to work with Neo4j. So you can enter “Y” to accept this software install. If your system already has Java installed, the installer will skip this stage.
Command

Start Neo4j Service
Step 1: Enable neo4j.service
After the installation, Neo4j should be running. However, we need to enable it as a “neo4j.service” service to set it to start on a reboot of the system.
Command

Step 2: Use systemctl command
Next, examine Neo4j’s status using the “systemctl” command. This step is essential to verify that everything is working as expected.
Command

Testing and Working With Neo4j
Now that you have Neo4j and its dependencies installed on your system and its services started, you are all set to test the DB connection and configure the admin user.
Step 1: Interact with Neo4J
To interact with the Neo4j database on the command line, we will launch the internal utility using the “cypher-shell” command.
Command

Output
Initially, you’ll need to provide a username and password, which are set to ‘neo4j’ by default. After successful authentication, you’ll be prompted to update the administrator password according to your preference.
Once the password is updated, you’ll gain access to the interactive ‘neo4j’ prompt. Here, you can interact with the Neo4j database by inserting and querying nodes
Step 2: Use exit command
Use the exit command after setting an administrator password and testing a connection to Neo4j.
Command

Output
Bye!
Neo4j CQL: Clauses, Functions, Datatypes, and Operators
As discussed in the earlier section, Neo4j has CQL (Cypher Query Language) as query language. Now we will see some of the clauses, functions, data types, and operators supported in CQL.
Neo4j CQL Clauses
| Command | Description |
|---|---|
| MATCH | Searches data with a specified pattern. |
| OPTIONAL MATCH | Functions like MATCH but allows null for missing parts. |
| WHERE | Adds conditions to CQL queries. |
| START | Locates initial points through legacy indexes. |
| LOAD CSV | Imports data from a locally stored CSV file. |
| CREATE | Creates nodes, properties, and relationships in the DB. |
| SET | Updates labels on nodes and properties on nodes/relationships |
| MERGE | Checks if a pattern exists; creates if not. |
| DELETE | Removes nodes, relationships, and paths from the DB. |
| REMOVE | Eliminates elements and properties from nodes/relationships. |
| FOREACH | Updates data within a list. |
| CREATE UNIQUE | Matches and creates a unique pattern. |
| RETURN | Specifies the query result set. |
| ORDER BY | Arranges query output in order (used with RETURN or WITH). |
| LIMIT | Restricts result rows to a specific value. |
| SKIP | Chains query parts together. |
| UNWIND | Expands a list into rows. |
| UNION | Joins outcomes of multiple queries. |
| CALL | Invokes a deployed procedure in the database. |
Neo4j CQL Functions
| Term | Description |
|---|---|
| String | Used when working with string literals. |
| Aggregation | Conducts aggregation operations on CQL query results. |
| Relationship | Used to fetch details of relationships, such as start and end nodes. |
Neo4j CQL Data Types
Most Neo4j data types are similar to the java language data types. They are also used to define the properties of a node or a relationship.
| Data Type | Description |
|---|---|
| Boolean | Defines boolean values (True, False). |
| byte | Describes an 8-bit integer. |
| short | Determines 16-bit integers. |
| int | Defines 32-bit integers. |
| long | Describes 64-bit integer. |
| float | Describes a 32-bit floating-point number. |
| double | Expresses a 64-bit floating-point number. |
| char | Represents a 16-bit character. |
| String | Represents a literal string. |
Neo4j CQL Operators
Here are the operators supported by Neo4j CQL:
| Operator Type | Operators |
|---|---|
| Mathematical Operators | +, -, *, /, %, ^ |
| Comparison Operators | >, <, >=, <=, = |
| Boolean Operators | AND, OR, XOR, NOT |
| String Operators | + |
| List Operators | +, IN, [X], [X?..Y] |
| Regular Expression | =~ |
| Matching String | STARTS WITH, ENDS WITH, CONSTRAINTS |
Conclusion
The prime motive behind the launch of the Neo4j graph database was to help users solve many different kinds of business and technical needs. It is simple to use and fits your use-cases whether you depend on graph transactions, market analysis, operational optimizations, or anything else. It has always delivered a seamless experience for integrating additional tools with the rest of your existing system.
Here are a few resources to support your further journey into this tool:
- Here are resources for drivers supported by popular programming languages. These drivers authorize developers to create applications and integrations utilizing the programming language of their preference.
- Here are resources for extensions and integrations to expand the technological ecosystem and developers’ needs using Neo4j.
- Here are the resources to deploy and run Neo4j in production environments, local or cloud environments, and anything in between.
- Here is the resource for official reference documentation, including tutorials, guides, code examples, and much more.
- Here is the resource to get yourself certified in Neo4j. This link provides training classes online and in the classroom across the globe. You will learn the basics of advanced CQL with any skill set.
- Here is the resource to contribute to Neo4j. You are always ready to contribute no matter what level of experience you have.
Read more articles on our blog.
Frequently Asked Questions
Q1. What is Neo4j used for?
A. Neo4j is used for managing and querying graph data, making it ideal for applications involving complex relationships like social networks, recommendation engines, and knowledge graphs.
Q2. Is Neo4j SQL or NoSQL?
A. Neo4j is a NoSQL database specifically designed for graph data, not SQL.
Q3. What are the downsides of Neo4j?
A. Downsides of Neo4j include a learning curve, resource-intensive operations on large graphs, and limited support for certain types of queries.
Q4. Is Neo4j still relevant?
A. Neo4j remains relevant for applications requiring complex relationship modeling and querying, as graph databases continue to find use in various industries.
The media shown in this article is not owned by Analytics Vidhya and are used at the Author’s discretion.
Data Scientist and a Technical Writer! I will give you the best of Open-Source and AI.
Talks about #chatgpt, #opensource, #contentcreation, #communitybuilding, and #artificialintelligence
Technical Writer | Data Science, ML, AI, Open-Source | Do More with Data - Litmus



