This article was published as a part of the Data Science Blogathon.

Source: Canva
Introduction
Competitive Deep Learning models rely on a wealth of training data, computing resources, and time. However, there are many tasks for which we don’t have enough labeled data at our disposal. Moreover, the need for running deep learning models on edge devices with limited processing power and training time is also increasing. The workaround for these issues is Transfer Learning!
Given the gravity of the issues and the popularity and wide usage of transfer learning in companies, startups, business firms, and academia to build new solutions, it is imperative to have a crystal clear understanding of Transfer Learning to bag a position for yourself in the industry.
In this article, I have compiled a list of twelve important questions on Transfer Learning that you could use as a guide to get more familiar with the topic and also formulate an effective answer to succeed in your next interview.
Interview Questions on Transfer Learning
Following are some interview-winning questions with detailed answers on Transfer Learning.
Question 1: What is Transfer Learning in NLP? Explain with Examples.
Answer: Transfer Learning is an ML approach where a model trained for a source task is repurposed for other related tasks (target task).
Usually, models are developed and trained to perform isolated tasks. However, to leverage our resources well and cut down the training time, the knowledge gained from a model used in one task (source task) can be reused as a starting point for other related tasks (target tasks).
The more related the tasks, the easier it is for us to transfer or cross-utilize our knowledge. Some simple examples would be:
In essence, Transfer Learning is inspired by human beings’ capability to transfer/leverage/generalize knowledge gathered from a related domain (source domain) to improvize the learning performance of the target domain task. Let’s understand this with the help of the following examples:
Example 1: Let’s say you know how to play Xiangqi, and now if you want to learn how to play Chess, given the overlap, it would be easier for you to learn given that you can apply/generalize the knowledge of Xiangqi while learning/playing Chess and learn quickly.
Example 2: Assume you know how to play the violin, so at least some amount of knowledge (i.e., musical notes/nuances, etc.) that you gathered while playing/learning and understanding the violin could be applied in learning how to play piano and learn quickly.
Example 3: Similarly, if you are well-versed in riding a bicycle, it would be beneficial to leverage that “knowledge/experience” while trying to learn how to ride a scooter/bike.
We don’t learn everything from the outset in each of these scenarios. We cross-transfer and apply/generalize knowledge from what we have learned in the past!
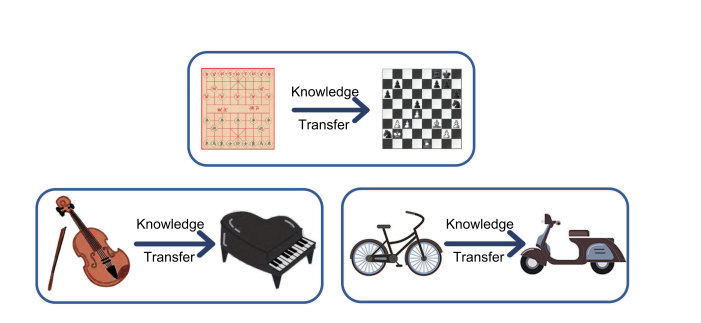
Figure 1: We can infer intuitive examples of transfer learning from our day-to-day lives (Source: Arxiv)
During transfer learning, the application of knowledge refers to leveraging the source task’s attributes and characteristics, which are applied and mapped onto the target task.
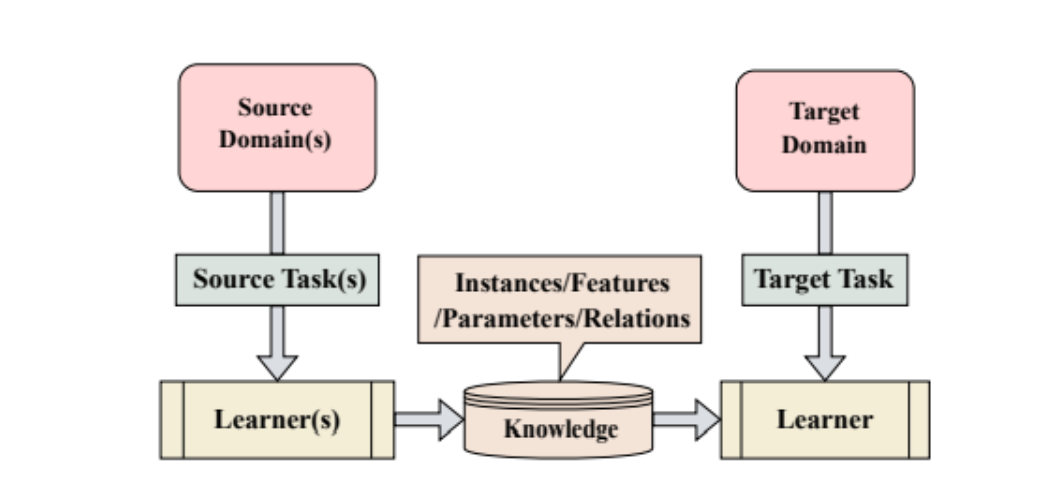
Figure 2: Illustration of Transfer Learning where knowledge could be in the form of instances/features/parameters/relations (Source: Arxiv)
During transfer learning, the base of a pre-trained model (that has already learned to do 1) is reused, and an untrained head having a few dense layers is attached (to learn 2). The body weights learn broad source domain features, which are used to initialize a new model for the new target task.
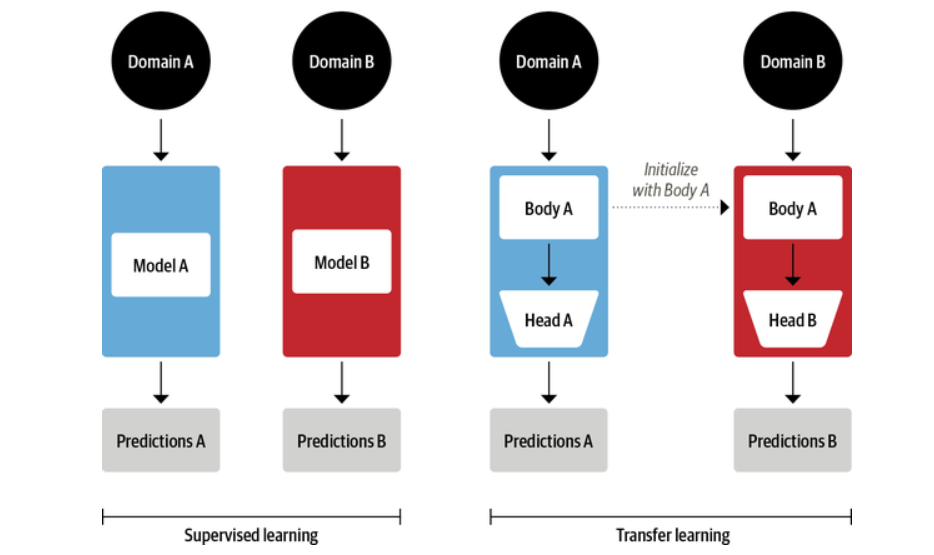
Figure 3: Traditional supervised learning (left) Vs. Transfer Learning (right) (Source: NLP with Transformers book)
Note: The applied knowledge does not necessarily have a beneficial effect on new tasks. We will take a look at this in Question 9.
Question 2: Why Should We Use Transfer Learning?
Answer: When the target task is little related to the source domain + task, it’s recommended to leverage Transfer Learning since it can help us in the following aspects:
1. Saves Time: Training a large model from scratch takes a lot of time, from a few days to weeks. This need can be curtailed by leveraging the pre-trained model (source model) knowledge.
2. Saves Resources + Economical + Environment Friendly: Since it doesn’t involve training the model right from the outset. As a result, it saves resources and is economical and environment-friendly.
3. Helps in building effective models when labeled data is scarce: In scenarios where we have very little data at our disposal, with the help of transfer learning, an effective machine learning model can be built using little training data.
4. Better Performance: During the positive transfer, it often yields better results than a model trained using supervised learning from scratch.
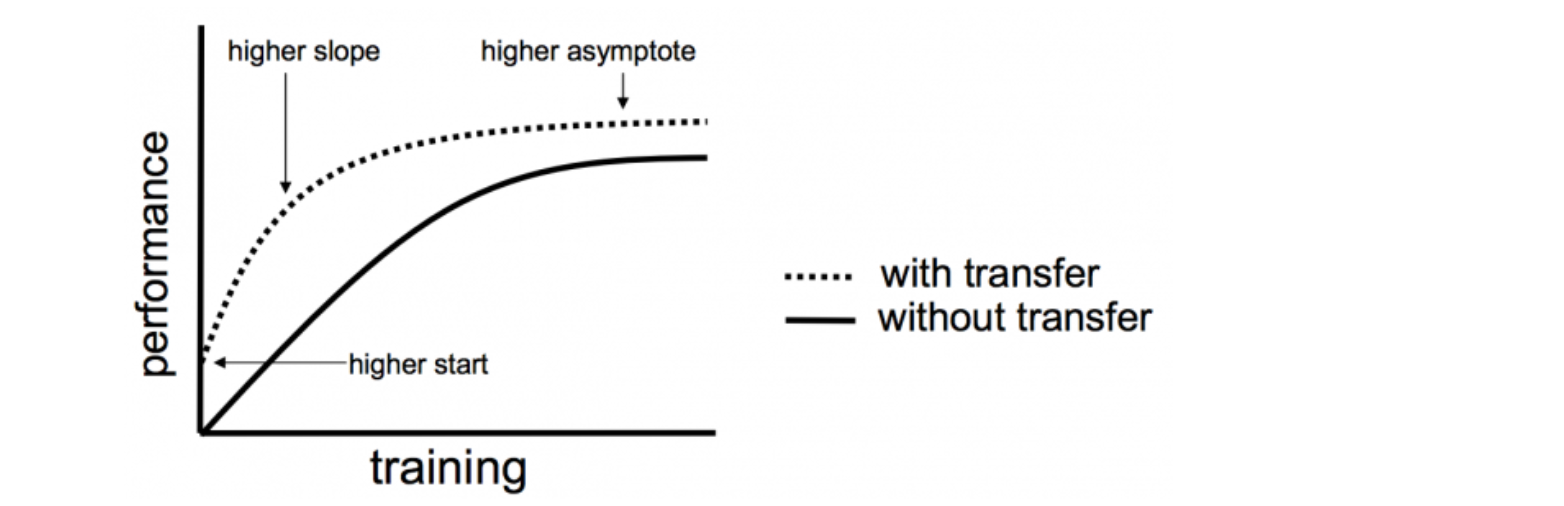
Figure 4: Effect of Transfer Learning on the performance of the model (Source: Machine Learning Mastery)
Question 3: List the Different Types of Transfer Learning.
Answer: Transfer Learning can be classified based on Problem and Solution. The following diagram pretty much sums up everything.
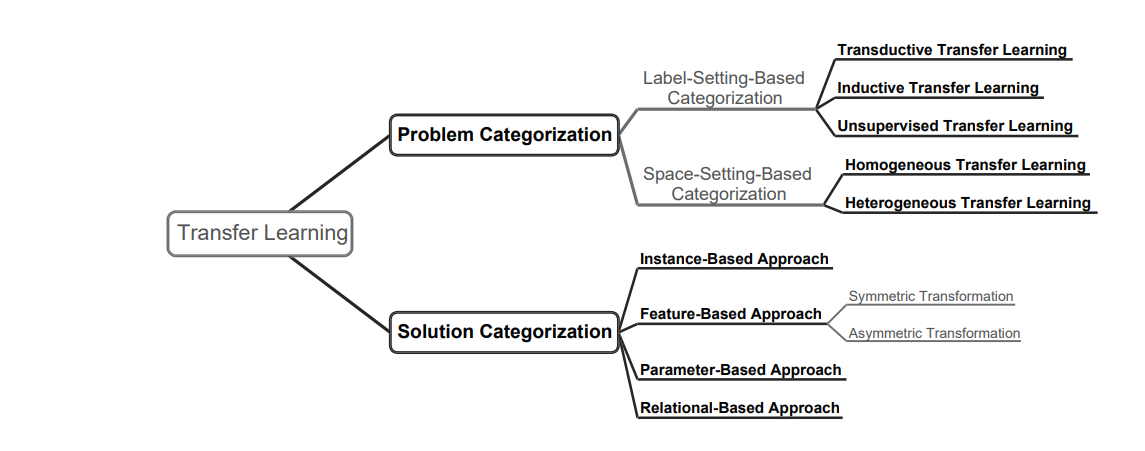
Figure 5: Types of Transfer Learning (Source: Arxiv)
1. Problem Categorization:
Label-Setting-Based Categorization:
- Transductive Transfer Learning
- Inductive Transfer Learning
- Unsupervised Transfer Learning
Space-Setting-Based Categorization:
- Homogeneous Transfer Learning
- Heterogenous Transfer Learning
2. Solution Categorization:
- Instance-based Approach
- Feature-based Approach
- Parameter-Based Approach
- Relational-Based Approach
Question 4: Explain More about Label-Setting-Based Transfer Learning Categorization.
Answer: As we briefly discussed before, based on label-setting, Transfer Learning can be classified as follows:
- Transductive Transfer Learning
- Inductive Transfer Learning
- Unsupervised Transfer Learning
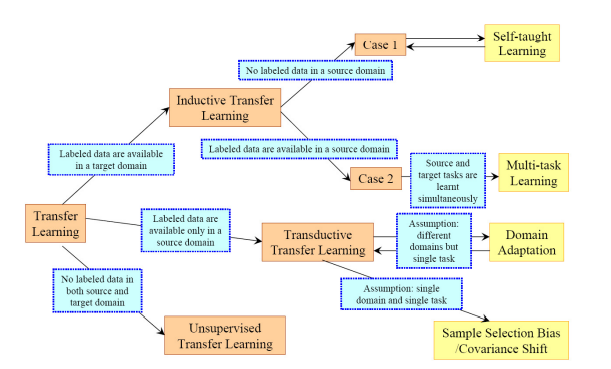
Figure 6: Graphical illustration of Label-setting-based Transfer Learning (Source: Arxiv)
a) Inductive Transfer Learning: In this, the source and target domains are the same. However, the source and target tasks are still different from one another.
The model uses inductive biases from the source task to help improve the performance of the target task.
Depending on whether the source task domain has labeled data or not, inductive transfer learning can be further classified as Multi-task Learning and Self-taught Learning (Sequential Learning).
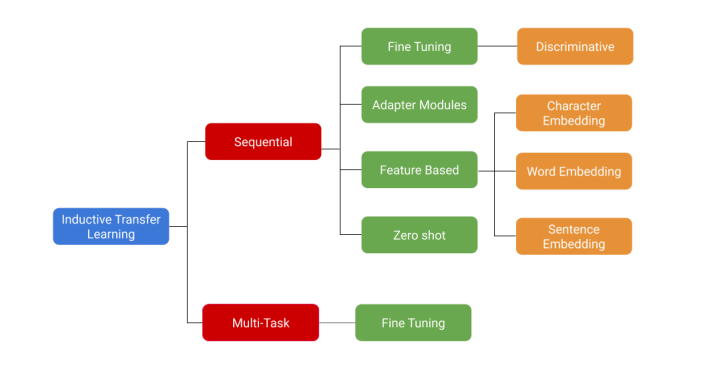
Figure 7: Types of Inductive Transfer Learning (Source: Arxiv)
b) Transductive Transfer Learning: In this, the source and the target tasks share similarities. However, the corresponding domains are different.
In this, the source domain has a lot of labeled data, while the target domain doesn’t have labeled data, or if it has, then the labeled samples are very few.
Transductive Transfer Learning can be further classified into Domain Adaptation and Cross-lingual learning.
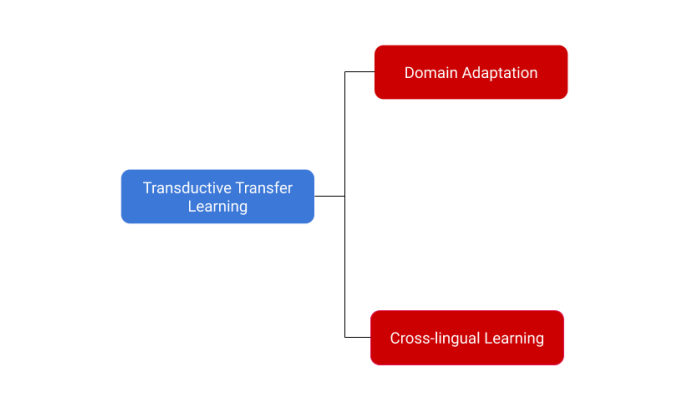
Figure 8: Types of Transductive Transfer Learning (Source: Arxiv)
c) Unsupervised Transfer Learning:
Unsupervised learning refers to using AI algorithms to find patterns in data sets, including data points that are neither classified nor labeled.
Unsupervised Transfer Learning is very similar to Inductive Transfer Learning.
Despite the source and target domain similarity, the source and target tasks differ.
Question 5: What is Sequential Transfer Learning? Explain its Types.
Answer: Sequential Transfer Learning is the process of learning multiple tasks sequentially. Let’s say the knowledge needs to be transferred to multiple tasks (T1, T2, …. Tn). At each time step, a particular task is learned. Contrary to multi-task learning, it is slower but has some advantages, mainly if all the tasks are unavailable during training.
Sequential transfer learning can be further divided into the following four categories:
- Fine-tuning
- Adapter modules
- Feature-based
- Zero-shot
1. Fine-tuning: A given pretrained model (M) with weights W is used to learn a new function f that maps the parameters f(W) = W’. The parameters can be changed on all layers or just a select few. Moreover, the learning rate could be different for the different layers.
Fine-tuning a pre-trained model on a massive semi-related dataset proved to be a simple and effective approach for many problems.
2. Adapter modules: A given pre-trained model with weights W is initialized with a new set of parameters less in magnitude than W.
3. Feature-based: It focuses on learning some representations on different levels, e.g., character, word,
sentence, or paragraph embeddings. The set of embeddings (E) from model M is kept unchanged.
4. Zero-shot: Given a pretrained model M with W, no training procedure is applied to optimize/learn new parameters.
Question 6: What is Multi-task Learning?
Answer: Multi-Task Learning is the process of learning multiple tasks simultaneously. For example, for a given pretrained model M, the learning is transferred to multiple tasks (T1, T2, · · ·, Tn).
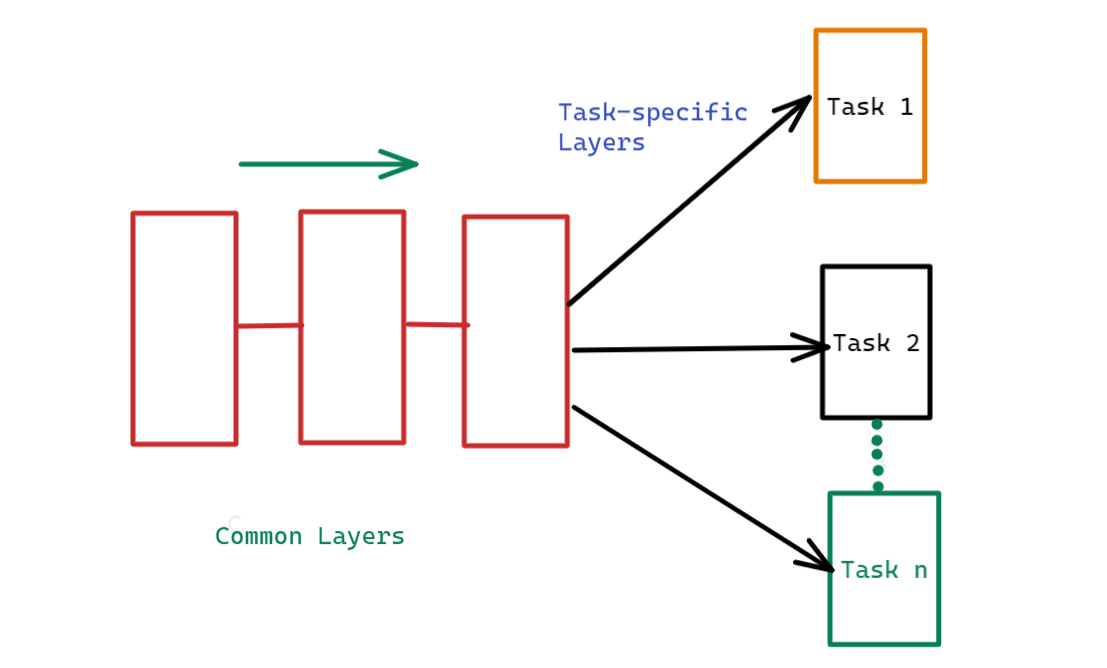
Figure 9: Multi-task Learning (Source: Author)
Question 7: What is Domain Adaptation?
Answer: Domain adaptation is adapting the source task to a new target domain. This is typically used when we want the model to learn a different data distribution in the target domain. For example, a review could be written on hospitals in the first domain (source domain) while on clinics in the second domain (target domain).
Domain adaptation is beneficial when the new training task has a different distribution or when we have very little data.
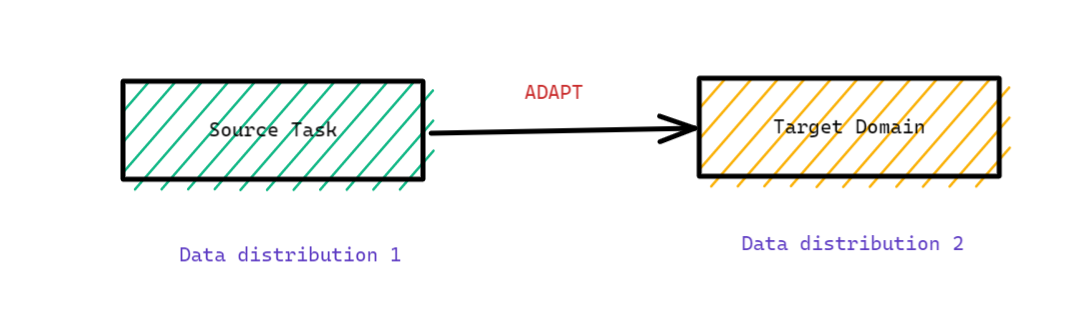
Figure 10: Diagram illustrating the Domain Adaptation wherein the source task having a certain data distribution is adapted to target domain of different data distribution (Source: Author)
Question 8: What does Cross-lingual Learning Mean?
Answer: Cross-lingual learning adapts the source task to a different language in the target domain. This is beneficial when we leverage a high-resource language to learn corresponding tasks in a low-resource language setting. For example, a model trained for the Spanish language could be fine-tuned on the French language dataset, which doesn’t ensure a positive transfer.
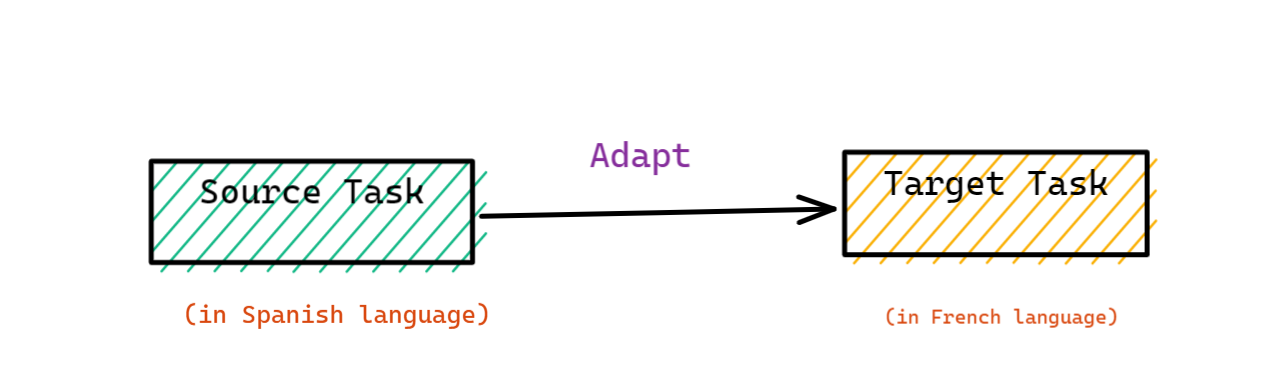
Figure 11: Diagram illustrating cross-lingual learning (Source: Author)
Question 9: Does Transfer Learning Always Improve the Results?
Answer: No. Sometimes the transfer method negatively affects the performance of the new target task, called a “Negative Transfer.” This usually happens when the source and target tasks are not similar enough, which causes the first round of training to be very far off.
Algorithms don’t always concur with what we see as similar, making it challenging to understand the fundamentals and standards of what type of training is sufficient.
Hence, while working with the transfer learning method, one of the key challenges is ensuring a positive transfer between related tasks whilst preventing the negative transfer between less related tasks.
For example, learning to ride a bicycle cannot help us learn to play the violin quickly.
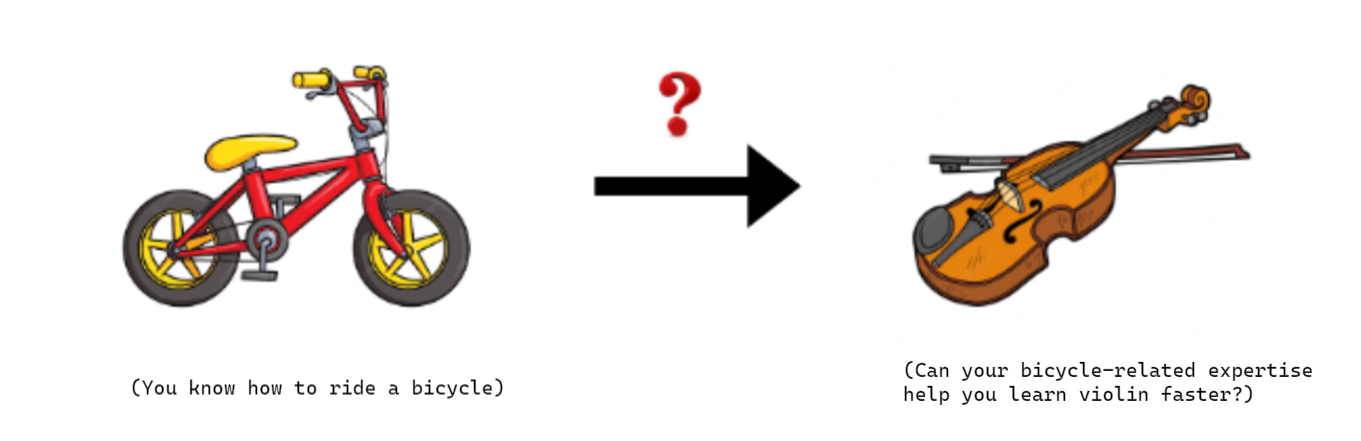
Figure 11: Diagram illustrating knowledge transfer between unrelated domains/tasks
Moreover, the similarity between the domains doesn’t ensure that the knowledge transfer will facilitate learning. Sometimes the similarities between the domains can be deceptive.
For example, despite Spanish and French being Neo-Latin languages with a close relationship, people who learn Spanish may have trouble learning French, like using the wrong vocabulary or conjugation. This happens because learning the word formation, usage, pronunciation, conjugation, etc., in French can be hindered by previous successful familiarity with the language in Spanish.
Question 10: What Should we do When we have the Target Dataset Similar to the Base Network Dataset?
Answer: So, it depends on if the target dataset is small or large.
Case 1:The target dataset is small + similar to the base network dataset: Given that the training dataset is small, the pre-trained network can be fine-tuned with the target dataset. However, this may lead to overfitting. Moreover, the target dataset might also have different classes, which may change the number of classes in the target task. In such cases, one or two fully connected layers are removed from the end, and a new fully connected layer satisfying the number of new classes is added. Now, only these newly added layers are trained, and the rest of the model is frozen.
Case 2:The target dataset is huge + similar to the base network dataset: Given that we have enough data at our disposal, the last full-connected layer is removed, and a new fully-connected layer is added with the appropriate number of classes. Now, the entire model is trained on the target dataset. This ensures the model is tuned while maintaining the same architecture on a new large dataset (target dataset).
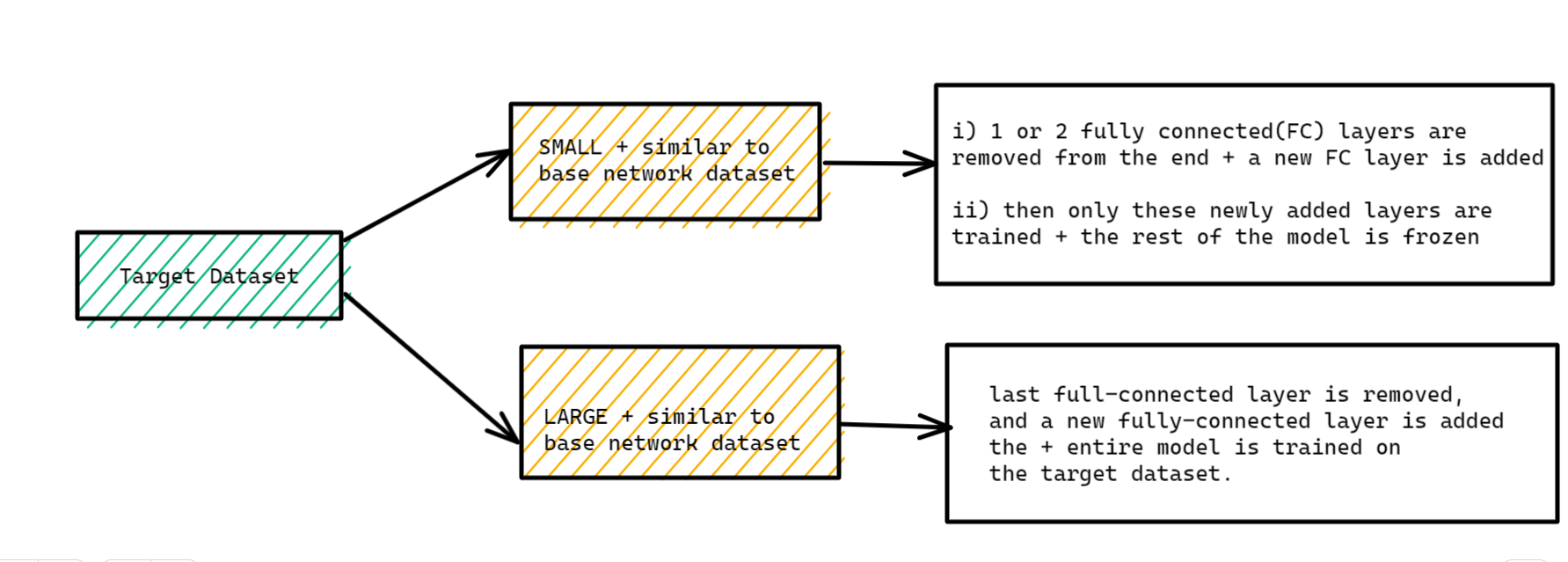
Figure 12: Diagram illustrating different scenarios when the target dataset is similar to the dataset of the base network
Question 11: What Should we do When we have a Target Dataset Different from a Base Network Dataset?
Answer: Again, it depends on if the target dataset is small or large.
Case 1: The target dataset is small + different from the base network dataset: Given that the target dataset is different, leveraging the high-level features of the pre-trained model will not help. Rather, most of the layers from the end in a pre-trained model should be removed, and then new layers satisfying the number of classes in the new (i.e., target) dataset should be added. This way, the low-level features from the pre-trained models can be leveraged, and the rest of the layers could be trained to fit the new dataset. Sometimes training the whole network after adding a new layer at the end is beneficial.
Case 2: The target dataset is huge + different from the base network dataset: Given that the target dataset is large and different from the source domain/task, the optimal approach would be to eliminate the last layers from the pre-trained model, and new layers with the appropriate number of classes should be added, then the whole network should be trained without freezing any layer.
Question 12: What Key Things Must be Considered During Transfer Learning?
Answer: During the process of transfer learning, the following key questions need to be addressed:

Figure 13: Key things that must be considered during the process of transfer learning
What to Transfer: This is the first and most crucial step in the whole process. To improve the effectiveness of the target task, it needs to be determined which part of the knowledge is source-specific and what the source and the target have in common.
When to Transfer: As we discussed, knowledge transfer sometimes reduces target task performance (also called a negative transfer). This usually happens when the source and target domains/tasks are not similar. We should aspire to use transfer learning in such a way that it improves the target task performance and does not degrade them. Hence, when to transfer and when not to transfer should be carefully considered.
How to Transfer: Once the what and how have been determined, we estimate how to transfer the knowledge across domains/tasks. This involves tweaking the existing algorithms and different techniques.
Lastly, the model’s input must be the same size it was primarily trained with. If that is not like that, a preprocessing step must be added to resize the input.
Conclusion
This article covers the twelve most important interview-winning questions. Using these interview questions as a guide, you can better understand the fundamentals of the topic and formulate an effective answer and present it to the interviewer.
To summarize, in this article, we learned the following:
- In transfer learning, the knowledge gained from a model used in the source task can be reused as a starting point for other related target tasks.
- Transfer Learning saves training time and resources and helps build competitive models even when labeled data is scarce.
- Sequential Transfer Learning is the process of learning multiple tasks sequentially. Let’s say the knowledge needs to be transferred to multiple tasks (T1, T2, …. Tn).
- Fine-tuning a pre-trained model on a massive semi-related dataset proved to be a simple and effective approach for many problems.
- Multi-Task Learning is the process of learning multiple tasks at once in parallel. For example, for a given pretrained model M, the learning is transferred to multiple tasks (T1, T2, · · ·, Tn).
- During the negative transfer, we witness degradation in the performance of the model.
- During transfer learning, we must consider what to transfer, when, and how to transfer. Moreover, the model’s input must be the same size it was primarily trained with.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
I'm a Researcher who works primarily on various Acoustic DL, NLP, and RL tasks. Here, my writing predominantly revolves around topics related to Acoustic DL, NLP, and RL, as well as new emerging technologies. In addition to all of this, I also contribute to open-source projects @Hugging Face.
For work-related queries please contact: [email protected]





