Bagging is a famous ensemble technique in the field of machine learning which is widely used for its performance and better results. It is one of the most important and high-performing ensemble techniques, which is easy to use and accurate. Due to the rich performance on even weak machine learning algorithms, It has become a popular ensemble technique and is being compared with other strong machine learning algorithms.
Most machine learning interviews frequently asked interview questions related to bagging algorithms. This article will discuss the top interview questions on bagging, which are mostly asked in machine-learning interviews. Practicing these questions will help one understand the concept of bagging very deeply and help answer the interview questions related to it very efficiently.
This article was published as a part of the Data Science Blogathon.

Bagging stands for Bootstarp Aggregation. Bootstrapping generally means randomly selecting a sample from a dataset, and aggregations stand for the further procedure and preprocessing of the selected samples. So in the bagging, we generally take multiple machine learning models of the same algorithm, meaning that we only take the same machine learning algorithm multiple times.
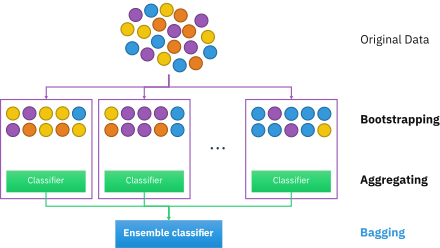
For example, if we are using SVM as a base algorithm and the count of the models is 5 then all the models will be of SVM only. Once the base model is decided, there will be a bootstrapping process where the random samples from the dataset will be selected and fed to the machine learning model.
The data will be fed to the models by bootstrapping, and there will be separate training for every model. Once all the models are trained, then there will be a prediction phase where all the different models will predict individually, and as a step of aggregation, we can apply any method to the multiple prediction data as there will be 5 different predictions from every model. The common approach is to calculate the mean of the predictions in case of regression or consider the majority count of it in case of classification.
The very basic difference between bagging and the random forest is related to the base models. In bagging, the base model can be any machine learning algorithm, and there is an option of selecting any machine learning algorithm as the base model in bagging by using the base_estimator parameter.
In the random forest, the base estimator or the base models are always decision trees, and other is not any option of selecting any other machine learning algorithms as base estimators in random forest.
Another difference between bagging and the random forest is that in bagging, all the features are selected for the training of the base models, whereas in the random forest, only a subset of the features are selected for the base model training, and out of that only the best performing are chosen as final features.
The main difference between bootstrapping and pasting is in the data sampling. As we know, in bagging, there is a sampling of the main dataset, It could be row or column sampling, out of which samples of the dataset are provided to the base models for training.
In bagging or bootstrapping, the samples are taken from the main dataset and fed to the first model, now the same samples can be again used for the training of any other method;, here, the sampling will be with replacement.
In pasting, there is a sample taken from the main dataset, but once the samples are used for training any model, the sawm samples will not be used again for the training of any other model. So here, the sampling is done without replacement.
In general, low bias high variance datasets are the data that have a very good performance on the training data and poor performance on the testing data, the case of overfitting. The data prone to overfit on any model is preferred for bagging algorithms as bagging reduces the variance of the dataset. Now let’s suppose we have a dataset which is having a very high variance. Suppose we have 10000 rows in our data from which 100 samples have a high variance; now, if this data is fed to any other algorithm, the algorithm will perform poorly as these 100 samples will affect the training, but in the case of bagging, there will be multiple models of the same algorithm, so there will not be a case where all the 100 rows will be fed to the same model due to bootstrapping or sampling of the data.So here now every model will experience the same weightage of the variance in the dataset, and in the end, the high variance of the dataset will not affect the final predictions of the model.
In the bagging algorithms, the main dataset is sampled in the parts, and the same multiple base models are used for training with different samples. In the final stage of aggregation, the output from every single base model will be considered, and the final output can be a mean or most frequent term from all models trained. It is also known as parallel learning, as all weak learners learn at the same time. Boosting is generally a stagewise addition method, where multiple weak learners are trained, and all the models are of the same machine learning algorithm. The errors and the mistake from the previously trained weak learner are considered to avoid the same errors in the further training of the next weak learner. It is also known as sequential learning, as the weak learner learns in sequence with each other.
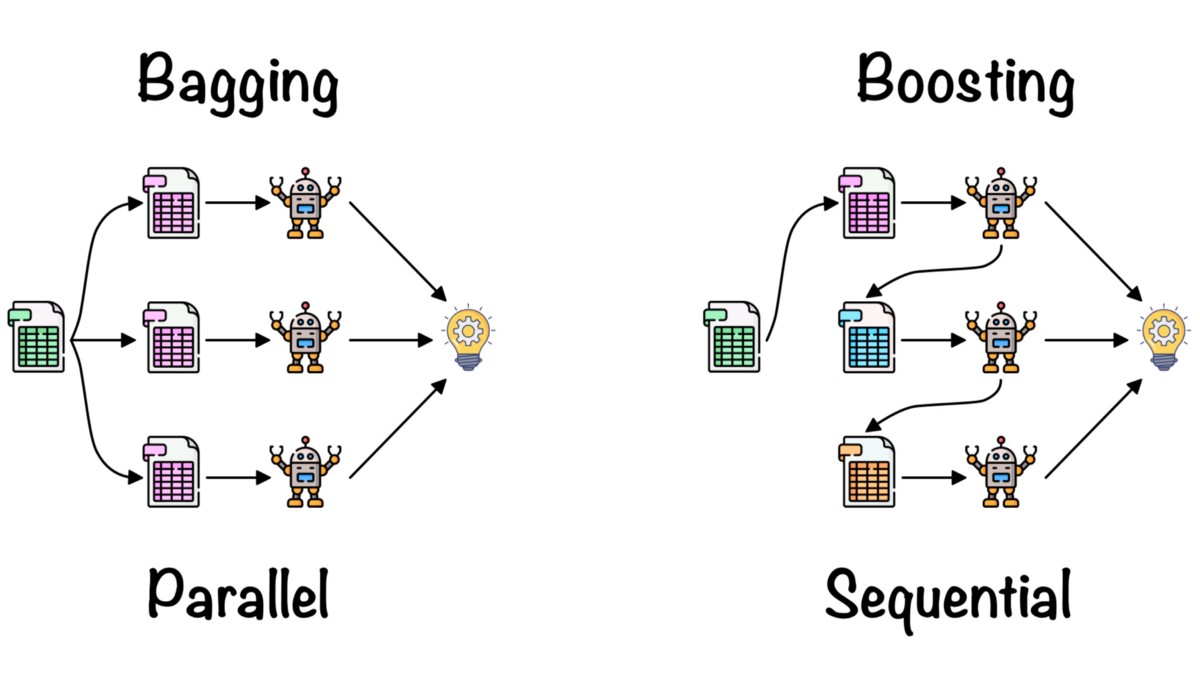
We can not say which algorithm will perform better all the way, but generally, bagging is preferred when there is a low bias and high variance in the dataset (overfitting), whereas boosting is preferred in the case of a high bias and low variance dataset (underfitting).
This article discusses the top 5 interview questions with the core idea and intuition behind them. Reading and preparing these questions will help one understand the bagging algorithm’s core intuition and how it differs from other algorithms.
Some Key Takeaways from this article are:
1. Random forest is a bagging algorithm with decision trees as base models.
2. Bagging uses sampling of the data with replacement, whereas pasting uses sampling of the data without replacement.
3. Bagging performs well on the high variance dataset and boosting performs well on high-bias datasets.
Test your knowledge and enhance your skills with our ‘Mastering Random Forest and Bagging Techniques‘ course! Dive into challenging questions on the Random Forest algorithm and gain the confidence you need to excel in your data science career—Enroll now and take your expertise to the next level!
Want to Contact the Author?
Follow Parth Shukla @AnalyticsVidhya, LinkedIn, Twitter, and Medium for more content.
Contact Parth Shukla @Parth Shukla | Portfolio or Parth Shukla | Email to contact me.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
UG (PE) @PDEU | 25+ Published Articles on Data Science | Data Science Intern & Freelancer | Amazon ML Summer School '22 | AI/ML/DL Enthusiast | Reach Out @portfolio.parthshukla.live
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








An interesting and very informative read.