This article was published as a part of the Data Science Blogathon.
Introduction
Gradient boosting is one of the best-performing and widely-used boosting algorithms in machine learning. Many concepts are associated with gradient boosting algorithms, from which many questions can be asked. This article will cover the most useful and important interview questions related to gradient boosting in data science with the core intuition and the mathematical formulations behind them.

Let us start solving and understanding the questions on gradient boosting one by one.
Gradient Boosting Algorithms Interview Questions
1. What is Gradient Boosting, and How Would You Define it?
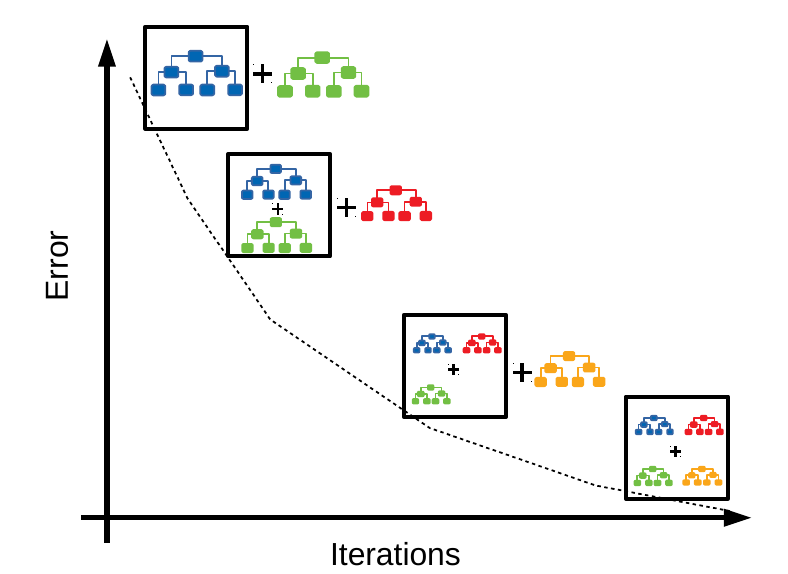
Gradient Boosting is a boosting algorithm, which works on the concept of the stagewise addition method, where many weak learners are trained, and in the end, we get strong learners as a result.
In gradient boosting, a particular weak learner is trained on the dataset, and the errors or mistakes made by the algorithm are noted. Now while training a second weak learner algorithm, the errors and the mistakes that are made by the previous algorithm is passed into the second weak learner algorithm to avoid the same mistake.
2. How Does Gradient Boosting Algorithm Work?
Since the gradient boosting algorithm is a boosting algorithm, the error rate from previous models is calculated and passed to the next models to reduce the overall error rates.
.jpeg)
In gradient Boosting regression problems, the prediction of the first model is always the mean of the target training data.
For Example, if the target variable is an age where various numbers are stored, then the output from the first weak learner will be the mean of all age values from the target column.
Once we have the prediction column from the first weak learner, the residual or error is calculated for the first model, which will be the difference between the actual and predicted value. Now while training the second model or a weak learner, the training data will be the same as model 1 training data, but the target column would be the residual column from weak learner model 1. So here, the residuals will be used as the target variables, and the model will be trained on that.
Once model 2 is trained, the prediction will be calculated for model 2, and the residuals will be again calculated for the same. The same process is done until we reach zero values for the residual column.
3. What is the Reason Behind Not Using Decision Stumps as Algorithms for Gradient Boosting?
Research has proven that using decision stumps as weak learner algorithms for AdaBoost gives good results, but in Gradient Boosting, using decision stumps as weak results does not give reliable results.
However, in Scikit-Learn, by tuning the value of max_lead_nodes we can easily modify the max depth of the decision trees.
from sklearn.tree import DecisionTreeRegressor Tree = DecisionTreeRegressor(max_leaf_nodes=8)
However, research has proven that the value of max_leaf_nodes between 8 to 32 gives the best results for the gradient boosting algorithm.
4. What are the Assumptions of the Gradient Boosting Algorithm?
There are certain assumptions taken while using the Gradient Boosting algorithm, which is as follows
1. The training dataset is present in the form of numerical or categorical data
2. The loss functions which is being used for calculating residuals should be differential at all points
3. There is no restriction for the number of iterations running to achieve zero residual values.
5. How Can You Improve the Performance of the Gradient Boosting Algorithm?
There is not any doubt about the performance of the Gradient Boosting algorithm. However, still, there are some ways and parameters associated with the algorithm, tuning in which the performance of the gradient boosting algorithm should be enhanced.
1. Increasing max-leaf nodes for the algorithm increases the decision tree’s depth as a weak learner, which might also increase the performance of the gradient boosting algorithm in some cases.
2. Increase the number of iterations.
3. Choosing a lower learning rate between 0.1 to 0.4 might increase the accuracy of the gradient boosting algorithm.
4. Random sampling can also help achieve a higher performance of the models.
5. Implementing the regularization techniques can also help get better accuracies from the model.
6. What are the Advantages of Using the Gradient Boosting Algorithm?
Advantages
1. Handling missing data while using a gradient-boosting algorithm is very easy.
2. Gradient Boosting algorithm performs best on both categorical and numerical data. Hence there is no need for much data preprocessing.
3. The performance of any data is outstanding and provides higher accuracy.
7. What are the Disadvantages of the Gradient Boosting Algorithm?
Disadvantages
1. Gradient Boosting algorithm is not robust to the outliers; hence, they are affected by outliers most and cause overfitting.
2. There is a higher power complexity in this algorithm as many decision trees are trained in this algorithm.
3. Since many calculations are present in this algorithm, It is time-consuming, and a higher time complexity is associated with it.
4. They are not user-friendly to understand, and very hard to interpret the results and parameters.
8. How is Gradient Boosting Different From XGBoost?
XGBoost is also a boosting algorithm in machine learning which is an extreme version of gradient boosting.
In gradient boosting, there is no implementation of regularization, whereas XGBoost is a regularized form of gradient boosting algorithm, where L2 or L1 regularization is already implemented.
9. What is the difference between Gradient Boosting and Random Forest?
The basic difference between gradient boosting and the random forest is that gradient boosting is a boosting algorithm that uses the stepwise addition method for weak learners. In contrast, the random forest is a booting algorithm that uses decision trees as a base model.
Gradient boosting is slow compared to the random forest, as much time is needed to train decision trees sequentially. In contrast, random forest is faster compared to the gradient boosting algorithm.
There are weak learners involved in gradient boosting, so it is a high-bias and low-variance algorithm. In random forests, due to fully grown decision trees, there might be a higher chance of overfitting; hence they are low-bias and high-variance models.
10. Why does Gradient Boosting perform so well? State 3 points.
1. Power of Crowd: Gradient Boosting is a stagewise addition method, which means it learns from the crowd of weak learners, and history says that the crowd is always right.
2. No repetition of mistakes: Once a particular weak learner is trained, the next weak learner is trained with preparation for not making the same mistake again.
3. Decision Trees and Tuning: We already know that decision trees are one of the best algorithms with high performance on any dataset; in Gradient Boosting, decision trees are used mainly as weak learners, which is also a reason behind the good performance of the gradient boosting algorithm.
Conclusion
This article covers the most important gradient-boosting algorithm interview questions that might be asked in data science interviews. All of the questions are covered with their core intuition and proper reasoning. Referring to these interview questions will not only help one to understand the concept in depth but will also help one to build a proper structure of the answer and deliver it to the interviewer.
Some Key Takeaways from this article are:
1. Gradient Boosting is a stagewise addition method, which uses the stagewise addition method for weak learners, and returns a strong learner as a result.
2. In Gradient Boosting, the first weak learner is not trained; the prediction from the first weak learner is the simple mean of the values, whereas all the other weak learners are trained on the training data and the residuals as the target variables.
3. The loss function used in the gradient boosting algorithm should be differential at all points.
4. Increasing the training data, increasing max-leaf nodes, tuning learning rates, and regularization techniques can enhance the performance of the gradient-boosting algorithm.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
UG (PE) @PDEU | 50+ Published Articles on Data Science | Technical Writer (AI/ML/DL) | Data Science Freelancer | Amazon ML Summer School '22 | Reach Out @[email protected], @portfolio.parthshukla.live






