Machine learning algorithms are one of the essential parameters while training and building an intelligent model for some of the problem statements. Many machine learning algorithms are used in several cases due to their faster and more accurate results. The Naive Bayes Classifier algorithm is also one of the best machine learning algorithms, resulting in a precise model with less effort.
In this article, we will discuss the naive Bayes algorithms with their core intuition, working mechanism, mathematical formulas, PROs, CONs, and other important aspects related to the same. Also, the key takeaways discussed in the end will help one answer the interview questions related to the Naive Bayes Classifier algorithms efficiently.
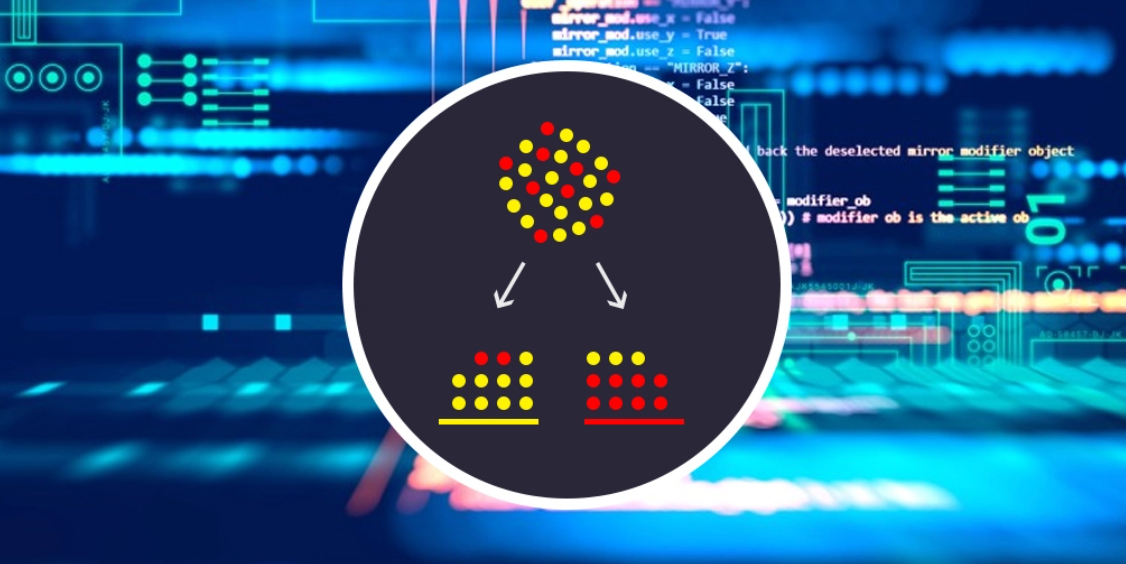
As the algorithm works totally on the concept of probabilities, conditional probabilities, and the bayesian rule, we can start learning the Naive Bayes Classifier algorithm by revising the concepts of probabilities and conditional statements of the same.
This article was published as a part of the Data Science Blogathon.
To understand the Naive Bayes Classifier from scratch, it is required to understand the term probability, as the algorithm itself works on the concept of probabilities of events. Let us try to understand the same.
Probability is the thing or term called in mathematics the “chance of something to take place”. In simple words, “the probability is a chance of some event to occur.”
We know that the sum of all probabilities is always one, and for Example, if we toss the coin in the air, the possibility is the head is 0.5 and the tails are also 0.5, which means that there is an equal, and 50% chance of heads and tails to come for the first trial.
Now we know the meaning of probability, the next term to understand is conditional probability. Conditional probability is defined as the probability of some event happening with respect to another event. In simple words, conditional probability is also a probability of some things occurring when a condition is involved.
The formula for the Conditional Probability is:
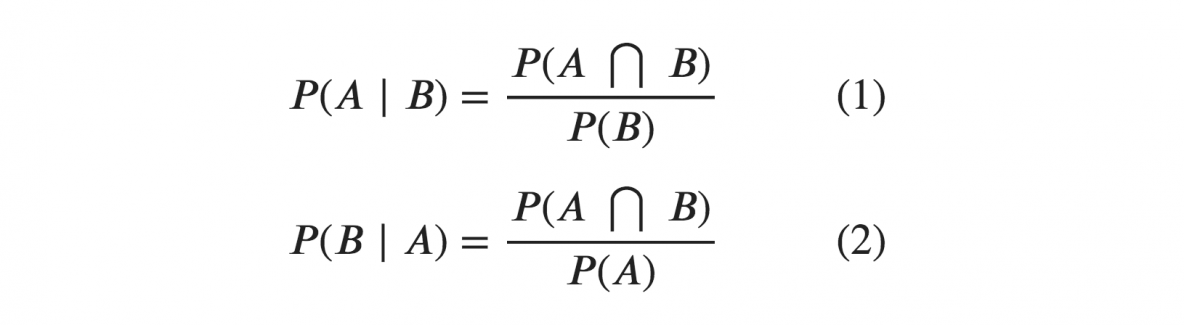
P(A*B) = Probability of events A and B both happening
P(A) = Probability of event A to occur.
P(B) = Probability of event B to occur.
P(A|B) = Probability of event A happening when event B occurs.
P(B|A) = Probability of event B happening when event A occurs.
Now, we are prepared to learn the bayesian rule after knowing the two critical terms. Thomas Bayes, a British mathematician in 1763, gave the bayesian theorem, which helped calculate the probability of some events taking place with conditions.
The formula for Bayes Rule is:
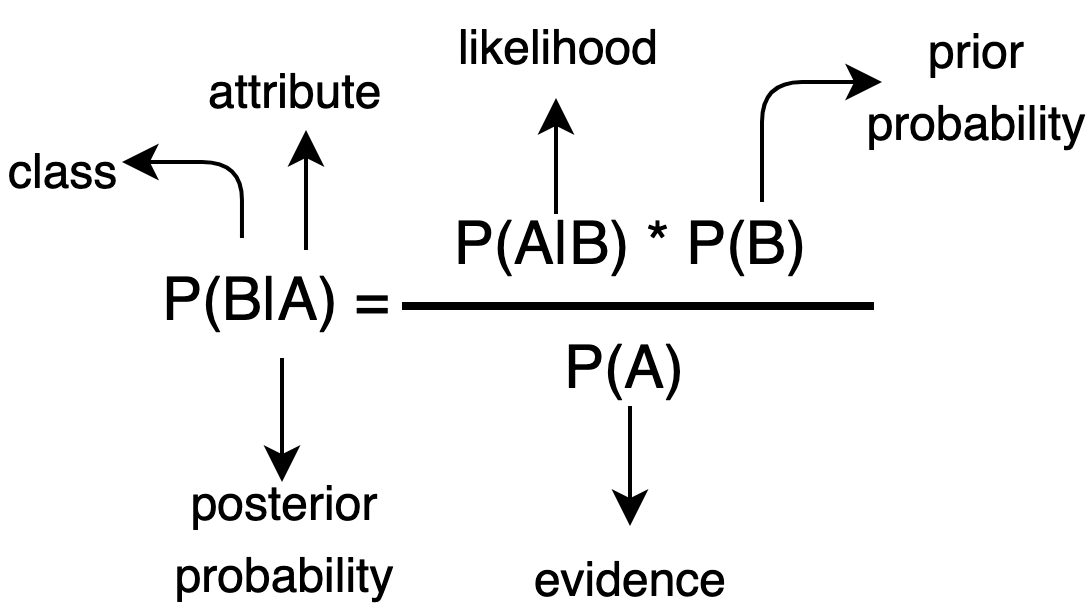
As we can see in the above image, the formula comprises a total of 4 terms. Let us try to understand them one by one.
P(B|A) = Probability of event B to happen when event A occurs.
P(A|B) = Probability of event A to happen when event B occurs.
P(A) = Probability of event A to occur.
P(B) = Probability of event B to occur.
From the above formula, we can easily calculate the probability of some event happening with the condition if we have the average likelihood of vents happening and both events happening.
Now is the best time to understand the naive Bayes algorithm, as the core fundamentals are clear. In real-time, there can be many events and many conditions that can happen simultaneously with events. So, in this case, we expand the bayesian theorem to solve this type of issue. If the features are independent, we can quickly extend the theorem and calculate the probability of the same.
The same bayesian theorem formula can be used here for multiple events and conditions, and one can easily calculate the probability with the help of the same.
The algorithm is one of the most useful algorithms in machine learning which helps in several classification problems, sentiment analysis, face recognition, etc.
After understanding the Naive Bayes algorithm, let us try to understand the working mechanism of the algorithm.
Let us take an example.
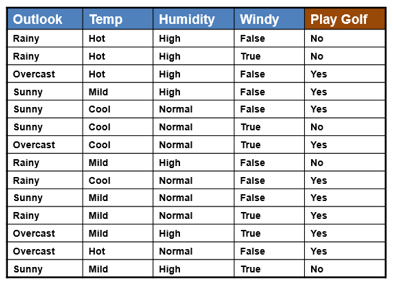
Let’s suppose we have a dataset of golf matches. The problem statement is a classification problem where we have to predict whether a gold match will players or not given some conditions of temperature, rain, weather, etc.
As we can see in the dataset that the outlook, temperature, humidity, and wind are independent features, and the play gold is a categorical target column. When we feed this data to the algorithm, the algorithm will calculate the normal and conditional probabilities of all the events occurring with all the possible conditions. Once the model is trained now, it is ready to predict unknown data.
Suppose we try to predict whether a golf match will play, given some conditional outlook, humidity, and temperature. In that case, the model will take the data as input and calculate the probability of Yes and No concerning all the conditions provided. If the likelihood of Yes is higher than No, then the model will return Yes as the output and vice versa.
Multicollinearity in machine learning is a term that deals with the linearity of the features of data feed. In simple words, the dataset having correlations between its independent features is called multilinear.
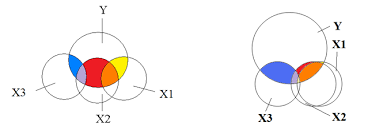
To understand the concept better, let us take an example.
Suppose we have a dataset with three columns, age, marks, and passed. Here the age is the age of the students, marks are the number obtained by students in exams, and the past is a categorical column that indicates whether a student passed or not.
Now here, the age and marks are the training columns means these columns should be fed to the algorithm, and the passed column should be the target column that a machine learning algorithm will predict. Now in some cases, the age and the marks columns are correlated somehow, and they are not independent anymore. It is called that the data has Multicollinearity in its features.
The professor checking the answer sheets can be biased toward students having less age and marks them with good numbers. Both columns are now correlated, and Multicollinearity is present in this dataset.
One of the basic assumptions of the naive Bayes algorithm is related to the Multicollinearit; it is required to check whether the data has Multicollinearity.
To check the some, we can use the following code:
import pandas as pd
df = pd.read_csv("data.csv")
df.corr()The following code results in the Pearson Correlation between the independent and dependent columns; we can check the relation between all the independent columns with another independent column to check for Multicollinearity.
Now a question might appear in your mind: Why is the algorithm called naive?
The main reason behind the name of the Naive Bayes Classifier is its assumption that ut assume while working on particular datasets and the Multicollinearity.
Here Naive Bayes Classifier assumes that the dataset provided to the algorithm is independent and the independent features are separate and not dependent on some other factors, which is why the Naive Bayes algorithm is called Naive.
There are mainly a total of three types of naive byes algorithms. Different types of naive Bayes are used for different use cases. Let us try to understand them one by one.
This Naive Bayes Classifier is used when there is a boolean type of dependent or target variable present in the dataset. For example, a dataset has target column categories as Yes and No.
This type of Naive is mainly used in a binary categorical tagete column where the problem statement is to predict only Yes or No. For Example, sentiment analysis with Positive and Negative Categories, A specific ord id present in the text or not, etc.
Code Example:
from sklearn.datasets import make_classification
from sklearn.naive_bayes import BernoulliNB
from sklearn.model_selection import train_test_split
nb_samples = 100
X, Y = make_classification(n_samples=nb_samples, n_features=2, n_informative=2, n_redundant=0)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25)
bnb = BernoulliNB(binarize=0.0)
bnb.fit(X_train, Y_train)
bnb.score(X_test, Y_test)This type of naive Bayes is used where the data is multinomial distributed. This type of naive Bayes is mainly used when there is a text classification problem.
For Example, if you want to predict whether a text belongs to which tag, education, politics, e-tech, or some other tag, you can use the multinomial Naive Bayes Classifier to classify the same.
This naive base outperforms text classification problems and is used the most out of all the other Naive Bayes Classifier.
Code Example:
from sklearn.feature_extraction import DictVectorizer
from sklearn.naive_bayes import MultinomialNB
data = [
{'parth1': 100, 'parth2': 50, 'parth3': 25, 'parth4': 100, 'parth5': 20},
{'parth1': 5, 'parth2': 5, 'parth3': 0, 'parth4': 10, 'parth5': 500, 'parth6': 1}
]
dv = DictVectorizer(sparse=False)
X = dv.fit_transform(data)
Y = np.array([1, 0])
mnb = MultinomialNB()
mnb.fit(X, Y)
test_data = data = [
{'parth1': 80, 'parth2': 20, 'parth3': 15, 'parth4': 70, 'parth5': 10, 'parth6':
1},
]
{'parth1': 10, 'parth2': 5, 'parth3': 1, 'parth4': 8, 'parth5': 300, 'parth6': 0}
mnb.predict(dv.fit_transform(test_data))This type of naive is used when the predictor variables have continuous values instead of discrete ones. Here it is assumed that the distribution of the data is Gaussian distribution.
Code Example:
from sklearn.datasets import make_classification
from sklearn.naive_bayes import GaussianNB
from sklearn.model_selection import train_test_split
nb_samples = 100
X, Y = make_classification(n_samples=nb_samples, n_features=2, n_informative=2, n_redundant=0)
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.25)
gnb = GaussianNB(binarize=0.0)
gnb.fit(X_train, Y_train)
bngnb.score(X_test, Y_test)The naive Bayes algorithms are known to perform best on text classification problems. The algorithm is mainly used when there is a problem statement related to the text and its classification. Several naive Bayes algorithms are tried and tuned according to the problem statement and used for a better accurate model. For Example: classifying the tags from the text etc.
Algorithms like Bernoulli naive are used most for these sentiment analysis problems. This algorithm is known to outperform on binary classification problems and is hence used most for such cases.

There are a total of two recommendation systems, content-based and collaborative filtering. The naive Bayes with collaborative filtering-based models is known for their best accuracy on recommendation problems. The naive Bayes algorithms help achieve better accuracies for recommending features to the users based on their interests and related to other users’ interests.

Source: https://www.xenonstack.com/hubfs/xenonstack-deep-learning-based-recommendation-system.png
The Naive Bayes algorithms are eager learning algorithms that try to learn from the training data and assume some of the parameters. Now, whenever the test data is provided for prediction to the algorithm, the algorithm calculates the results according to its knowledge gained from the training and offers faster and more accurate results. Hence it could be used for real-time predictions.
1. Faster Algorithms:
The Naive Bayes algorithm is a parametric algorithm that tries to assume certain things while training and using the knowledge for prediction. Hence it takes significantly less time for prophecy and is a faster algorithm.
2. Less Training Data:
The naive Bayes algorithm assumes the independent features to be independent of each other, and if it exists, then the naive Bayes needs less data for training and performs better.
3. Performance:
The Naive Bayes algorithm achieves faster and more accurate performance with less data, and its handling of categorical text data surpasses that of other algorithms, making comparisons inequitable.
1. Independent Features:
In a real-time dataset, obtaining independent features that are entirely independent of each other is almost impossible. There are typically two to three features that correlate with each other, thus not fully satisfying the assumption at all times.
2. Zero Frequency Error:
The zero frequency error in naive Bayes is one of the most critical CONs of the Naive Bayes algorithm. According to this error, if a category is absent in both the training data and the test data, then the Naive Bayes algorithm will assign it zero probability, resulting in what is known as the Zero Frequency error in Naive Bayes.
To address this kind of issue, we can use Laplace smoothing techniques.
Well, the Naive Bayes algorithm is the best-performing and faster algorithm compared to other algorithms. However, still, there are cases where it cannot perform well, and some different algorithms should be used to handle such cases.
The Naive Bayes algorithm can be used if there is no multicollinearity in the independent features and if the features’ probabilities provide some valuable information to the algorithms.
This algorithm should also be preferred for text classification problems. One should avoid using the Naive Bayes algorithm when the data is entirely numeric and multicollinearity is present in the dataset.
If it is necessary to use the Naive Bayes algorithm, then one can use the following steps to improve the performance of Naive Bayes algorithms.
1. Remove Correlated Features:
Naive Bayes algorithms perform well on datasets with no correlations in independent features. removing the correlated features may improve the performance of the algorithm
2. Feature Engineering:
Try to apply feature engineering to the dataset and its features, combine some of the elements, and extract some parts of them out of existing ones. This may help the Naive Bayes algorithm learn the data quickly and results in an accurate model.
3. Use Some Domain Knowledge:
Oe should always try to apply some domain knowledge to the dataset and its features and take steps according to it. It may help the algorithm to make decisions faster and achieve higher accuracies.
4. Probabilistic Features:
The Naive Bayes algorithm works on the concept of probabilities, so try to improve the features that give more weightage to the algorithms and their probabilities, try to implement those, and run the roses in a loop to know which features are best for the algorithm.
5. Laplace Transform:
In some cases, the category may be present in the test dataset and was not present while training and the model will assign it with zero probability. Here we should handle this issue by Laplace transform.
6. Feature Transformation:
It is always better to have normal distributions in the datasets and try to apply box-cox and yeo-johnson feature transformation techniques to achieve the normal distributions in the dataset.
In this article, we discussed the naive Bayes algorithm, the probabilities, conditional probabilities, the bayesian theorem, the core intuition and working mechanism of the algorithm with their types, code examples, applications, PROs, and CONs associated with some of the key takeaways from this article. This article’s complete knowledge will help one understand the Naive Bayes algorithm from scratch to an in-depth level. It will help answer the interviews related to it very efficiently.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
A. The Naive Bayes learning algorithm is a probabilistic machine learning method based on Bayes’ theorem. It is commonly used for classification tasks.
A. The two types of Naive Bayes are:
a) Gaussian Naive Bayes
b) Multinomial Naive Bayes
A. An example of the Naive Bayes approach is spam email detection. By analyzing the presence of certain words or features in emails, the algorithm can classify whether an email is spam or not spam.
A. Naive Bayes is called so because it makes the “naive” assumption that the features are independent of each other, which may not always hold true in real-world data.
UG (PE) @PDEU | 25+ Published Articles on Data Science | Data Science Intern & Freelancer | Amazon ML Summer School '22 | AI/ML/DL Enthusiast | Reach Out @portfolio.parthshukla.live
Lorem ipsum dolor sit amet, consectetur adipiscing elit,







