Introduction
In this constantly growing technical era, big data is at its peak, with the need for a tool to import and export the data between RDBMS and Hadoop. Apache Sqoop stands for “SQL to Hadoop,” and is one such tool that transfers data between Hadoop(HIVE, HBASE, HDFS, etc.) and relational database servers(MySQL, Oracle, PostgreSQL, SQL Server, DB2, etc.). If you’re preparing for interviews, you may want to familiarize yourself with some commonly asked Sqoop interview questions.
Apache Sqoop is an open-source framework and a command-line interface application that facilitates us with Sqoop export and Sqoop import techniques.
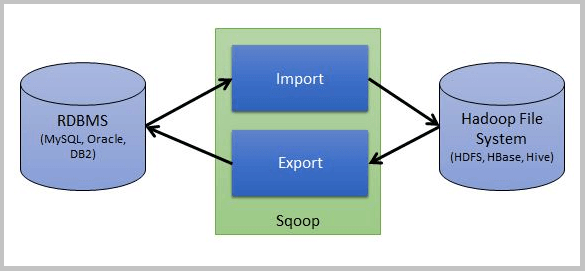
Source: Freecode.com
As shown in the above image, this tool allows us to import/extract data from multiple types of databases like MySQL, HDFS, and Hadoop and export that data from the Hadoop file.
In this blog, I discussed the Top 8 Sqoop Interview Questions and Answers that will help you to set a pace for Apache Sqoop and ace your upcoming interview!
Learning Objectives
Here is what we’ll learn by reading this blog thoroughly:
- A common understanding of what an Apache Sqoop is and what role it plays in the technical era.
- Knowledge of the Sqoop import and different file formats supported by Sqoop.
- An understanding of the data storage process in Sqoop.
- An understanding of Hadoop Sqoop commands along with their uses.
- Insights into concepts like Incremental data load and synchronization of data in Hadoop.
Reading this guide, we will comprehensively understand Sqoop to interact with data. We will be equipped with the knowledge and ability to use this technique effectively.
This article was published as a part of the Data Science Blogathon.
Table of contents
- Introduction
- Sqoop Interview Questions and Answers
- Q1. What is the need for Apache Sqoop?
- Q2. What do you mean by Sqoop Import? Explain different file formats.
- Q3. Explain the basic Hadoop Sqoop commands with their uses.
- Q4. Explain the root cause and fix the below error scenarios.
- Q5. What query do you perform to import a bulk of tables by excluding some specific ones?
- Q6. Suppose the source data gets modified every second; how will you synchronize the data in Hadoop that Sqoop imports?
- Q7. Explain the process of performing an incremental data load in Sqoop.
- Q8. Explain the key benefits of using Apache Sqoop.
- Conclusion
Sqoop Interview Questions and Answers
Q1. What is the need for Apache Sqoop?
To understand the need for Apache Sqoop, think about the possible solutions if we want to process lookup tables or the legacy data available in RDBMS with the help of Hadoop MapReduce. One straightforward resolution can be to read data from the RDBMS into the mapper and process it. Still, this solution may lead to the distributed denial of service (i.e., the bandwidth of the resources would be flooded), which is not practically feasible. Here comes the need for Apache Sqoop, which allows customers to import data on HDFS from an RDBMS, export it in HDFS, and return it to the RDBMS.
To fetch data from RDBMS, Sqoop uses Hadoop MapReduce, and at the time of importing, it controls the count of mappers accessing RDBMS to avoid distributed denial of service attacks. By default, 4 mappers can be used simultaneously, but the value can be configured. Apache Sqoop solves the challenge of moving data out of a data warehouse into the Hadoop environment and becomes a life-saver for the users.
Q2. What do you mean by Sqoop Import? Explain different file formats.
The Sqoop Import tool is used to import tables from RDBMS to HDFS. Usually, we map the rows of each table as a record in a Hadoop file, depending on the data type. For example, if we have text files, all records are there as text data, and if we have Avro/sequence files, all records are binary.
The syntax to import the data from the data table is:
--columns
--where
--SQL queryExample:-
Sqoop import –connect jdbc:mysql://db.one.com/corp --table ANALYTICSVIDHYA_WRITER --where “start_date> ’2019-10-02’ ”
sqoopeval --connect jdbc:mysql://db.test.com/corp --query “SELECT * FROM ANALYTICSVIDHYA_WRITER LIMIT 20”
sqoop import –connect jdbc:mysql://localhost/database --username root --password analytics –columns “name,writer_id,blog_title”We can import the data in Sqoop by using two file formats:
i) Delimited Text File Format
To import data using Apache Sqoop, the Delimited Text File Format is the default file format. Moreover, this file format can be defined explicitly with the help of the –as-textfile argument to the import command in Sqoop. When we transfer this argument to the command, a string-based representation of all the records to the output files is produced with the delimited characters between rows and columns.
ii) Sequence File Format
Sequence File Format contains the data in a binary format(i.e., in the form of 0, 1). Sqoop import these sequence files as records which are stored in custom record-specific data types shown as Java classes. Moreover, Sqoop can create these data types automatically and manifest them as java classes.
Q3. Explain the basic Hadoop Sqoop commands with their uses.
he most commonly used Hadoop Sqoop command includes Eval, Export, Codegen, Create-hive-table, Help, Import, Import-all-tables, List-databases, List-tables, Versions, etc. Let’s understand them!
- Eval- Eval command in Sqoop is used to evaluate an SQL statement/query and display the output.
- Export- The export command in Sqoop is used to export a Hadoop directory into a database table.
- Codegen- Codegen command generates the code to interact with database records.
- Create-hive-table- This Sqoop command facilitates us to Import a table definition into a hive database.
- Help- Whenever we get stuck with any Sqoop command and need its available options, this command will help us by displaying a list of available commands.
- Import- The import command in Sqoop is responsible for importing a table from a relational database to HDFS.
- Import-all-tables- This command is used to import a bulk of tables from a relational database to HDFS
- List databases- This command displays a list of all available databases on a defined server.
- List-tables- This command allows us to see a list of available tables in any database
- Version- If you want to get the version-related information of Sqoop, then this command is very helpful.
Q4. Explain the root cause and fix the below error scenarios.
). Connection failure exception during connecting to Mysql through Sqoop.Cause:- The connection failure exception usually occurs when permission is denied to access the Mysql database over the network.
Fix:- Firstly, we have to run the below command to check whether we have connected to the Mysql database from a Sqoop client machine.$ mysql –host=MySqlnode> –database=Analytics –user= –password= Now after getting confirmed, you can grant the permissions with the below commands. mysql> GRANT ALL PRIVILEGES ON *.* TO ‘%’@’localhost’; mysql> GRANT ALL PRIVILEGES ON *.* TO ‘ ’@’localhost’;
Sqoop import
–connect jdbc:oracle:thin:@analytics.testing.com/ANALYTICS
–username SQOOP
–password sqoop
–table ORGANIZATION.WRITERSii). Java. lang.IllegalArgumentException at the time of importing tables from the oracle database
Cause:- This illegal argument exception usually occurs when we enter the table or user name in a mixed format. Sqoop commands are very case-sensitive to table names and user names. Also, sometimes we call a table in a different namespace instead of where it was created/presented.
Fix:- First, check your table name or user name, and if you find any Upper-case/Lower-case issues, then resolve that.
Next, check whether the source table is created under a different user namespace if the error is still there. If it is so, then change the table name to USERNAME.TABLENAME.
Q5. What query do you perform to import a bulk of tables by excluding some specific ones?
To understand it better, suppose we have around 1000 tables in our database. I want to import all the tables from the database except the tables named Table 568, Table 372, and Table 681. First, our database is so large that we have to display around 1000 tables, so we can’t import each table one-by-one. A proficient way is to use the import-all-tables command of Sqoop. Now, to exclude table numbers 568,372, and 681, we can use the exclude-tables option of Sqoop.
Sqoop import-all-tables
–connect –username –password –exclude-tables Table568, Table 372, Table 681Q6. Suppose the source data gets modified every second; how will you synchronize the data in Hadoop that Sqoop imports?
As the source data is getting modified/updated every second, we have to use the incremental parameter with data import to synchronize the data in Hadoop. However, to use the incremental parameter, we can go with one of the two options-
i) Append
The append option is the most suitable option for incremental import as it works well when the table is constantly updated with new rows, and the row id values are also increasing. A new row will only be updated when the values of columns are checked and discovers any modified value for those columns is.
ii) LastModified
In this type of incremental import, the data column of the source is checked. The values would be updated for any records that have been modified after the last import based on the LastModifed column in the source data.
Q7. Explain the process of performing an incremental data load in Sqoop.
The incremental data load process of Sqoop is used to synchronize the modified data (usually known as the delta data) from RDBMS to HDFS. In addition, the incremental load command facilitates the delta data in Sqoop. We can use the Sqoop import command or load the data into the hive without overwriting it to perform this operation.

The multiple attributes that need to be defined during incremental load are:
1) Mode (incremental)
The mode attribute can have the Append or Last-Modified value, which shows how Sqoop will identify the new rows.
2) Col (Check-column)
Col attribute is used to specify the column that should be examined to identify the rows to be imported.
3) Value (last value)
The value attribute is used to specify the maximum value of the check column from the previous import operation.
Q8. Explain the key benefits of using Apache Sqoop.
Below are the key benefits of using Apache Sqoop:-
a). Support parallel data transfer and fault tolerance
Sqoop is famous for its service of supporting parallel data transfer, which is possible because of its compatibility, using the Hadoop YARN (Yet Another Resource Negotiator) framework for import and export processes, which also facilitates fault tolerance.
b). Import only the required data
Apache Sqoop can import only the required data by eliminating the unnecessary subset of rows from a database table returned from an SQL query. A surprising feature of Sqoop is that it can also import data into HBase even though it is a NoSQL database.
c). Support almost all major RDBMS
To connect to the Hadoop Distributed File System, Sqoop supports almost all RDBMS, like MySQL, Postgres, Oracle RDB, SQLite, DB2, etc. The database needs JDBC (Java Database Connectivity) and a connector that supports JDBC to connect with an RDBMS. Sqoop has the feature of supporting fully loading tables, due to which data can be directly loaded into Hadoop (Hive/HBase/HDFS). The remaining parts of the table can be loaded whenever they are updated with the help of an incremental load feature.
d). Support Compressing
To compress the data in Sqoop, we have two methods deflate (gzip) algorithm and -the compress argument. Sqoop also facilitates compression using the -compression-codec argument and loads the compressed tables onto Hive.
e). Support Kerberos Security Integration
One of the strongest Security authentication, Kerberos, is also supported by Sqoop. Kerberos is a computer network authentication protocol that uses the concept of ‘tickets’ to allow nodes to interact over a non-secure point to securely prove their identity to each other.
Conclusion
This blog covers some of the frequently asked Apache Sqoop interview questions that could be asked in data science and big data developer interviews. Using these interview questions as a reference, you can better understand the concept of Apache Sqoop and start formulating effective answers for upcoming interviews. The key takeaways from this Sqoop blog are:-
- Sqoop is a very powerful tool used to move data from a data warehouse to a Hadoop environment(i.e., Import or export of database).
- The Sqoop Import tool is used to import the table data to Hadoop in the form of records, and two important file formats are the delimited file format and the Sequence file format.
- We have multiple Sqoop commands which allow us to interact with data, including Codegen, eval, import, export, etc.
- We have discussed the common abends that occur while running our Sqoop interview questions queries.
- At last, we end this blog by discussing some of the key benefits of Apache Sqoop.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







