Introduction
Companies can access a large pool of data in the modern business environment, and using this data in real-time may produce insightful results that can spur corporate success. Real-time dashboards such as GCP provide strong data visualization and actionable information for decision-makers. Nevertheless, setting up a streaming data pipeline to power such dashboards may be a tough task. This article explores how to use Google Dataflow to create a streaming data pipeline that supports a real-time dashboard. Have you ever tried streaming data on GCP for data engineering?
Learning Objectives
- Creating a Dataflow job from a template
- Subscribing to a pub/sub topic
- Streaming a Dataflow pipeline into Big Query
- Analyzing results with SQL
This article was published as a part of the Data Science Blogathon.
Table of Contents
Bigdata Challenges
The important task of creating scalable pipelines falls to data engineers. The 4 V’s—variety, volume, velocity, and veracity—are a group of four important difficulties that data engineers and data scientists in today’s enterprises must contend with.
Variety:
The term “variety” describes the numerous sources and varieties of both organized and unstructured data. Photo, video, email, audio, and other types of streaming data are all possible. It is difficult to store and handle this unstructured data.
Volume:
Big data indicates extremely large data sets. For instance, information produced by IOT devices, smartphones, cloud computing, etc. This v won’t cause too much trouble if we have enough storage.
Velocity:
The rate at which data enters from sources like corporate processes, machines, networks, and human engagement with things like social networking sites, mobile devices, etc., is referred to as velocity. There is an enormous and constant influx of data. If you can manage the velocity, this real-time data may assist organizations and researchers in making important decisions that offer strategic competitive advantages and Returns.
Veracity:
It relates to data biases, noise, and abnormalities. This is the most difficult challenge in comparison to the others. We must evaluate the data for accuracy before using it for business insights because it is obtained from numerous sources.
Message-oriented Architecture

- GCP Pub/Sub tool is designed to manage distributed message-oriented architectures at scale.
- Full form or Pub/Sub is Publisher/Subscriber platform for delivering messages to subscribers.
- It can receive messages from various device streams, including IoT devices, gaming events, and application streams.
- As a GCP Pub/Sub subscriber, Dataflow can ingest and transform these messages in an elastic streaming pipeline and output the results into an analytics data warehouse such as BigQuery.
Step 1: Source a Pre-created Pub/Subtopic and Create a Big Query Dataset
Run the below command in the cloud shell:
bq --location=us-west1 mk tridesAbove command creates a fresh dataset named “trides” in Big Query.
bq --location=us-west1 mk \
--time_partitioning_field timestamp \
Output:

Step 2: Create a GCS Bucket
Cloud Storage is a versatile service that enables storing and retrieving data globally, regardless of size. It can be used for various tasks such as data storing or for data recovery, etc.

Step 3: Create a Dataflow Streaming Pipeline
For this project, you will create a streaming data pipeline that reads sensor data from Pub/Sub, calculates the highest temperature within a specific time frame, and saves the results in BigQuery. Dataflow is a serverless solution that allows data analysis to be performed without the requirement for infrastructure management.
A few easy actions are required to resume a connection to the Dataflow API in the Google Cloud Platform (GCP). To begin, launch the Cloud Console and type “Dataflow API” into the top search box. After selecting the Dataflow API in the search results box, click “Manage” and then “Disable API.” Click “Disable” to confirm the action.
When you’ve disabled the API, click “Enable” to reconnect to the Dataflow API. This will keep the API up to date and allow you to continue using it for data processing.

You may now start a new streaming pipeline after reconnecting to the Dataflow API. To do so, go to the Cloud Console’s Dataflow section and select “Create Job from Template.” For your Dataflow task, enter “streaming-taxi-pipeline” as the Job name and “us-central1 (Iowa)” as the regional destination.
Next, as the Dataflow template, pick the Pub/Sub Topic to Big Query template. Choose the subject that already exists in your project from the selection list in the Input Pub/Sub topic box. The subject will be shown as “projects/projectid>/topics/trides-live.”
Enter “projectid>:trides.live” in the Big Query output table field. Please note that “projectid” must be replaced with your Project ID, and there is a colon “:” between the project and dataset names, and a dot “.” between the dataset and table names.
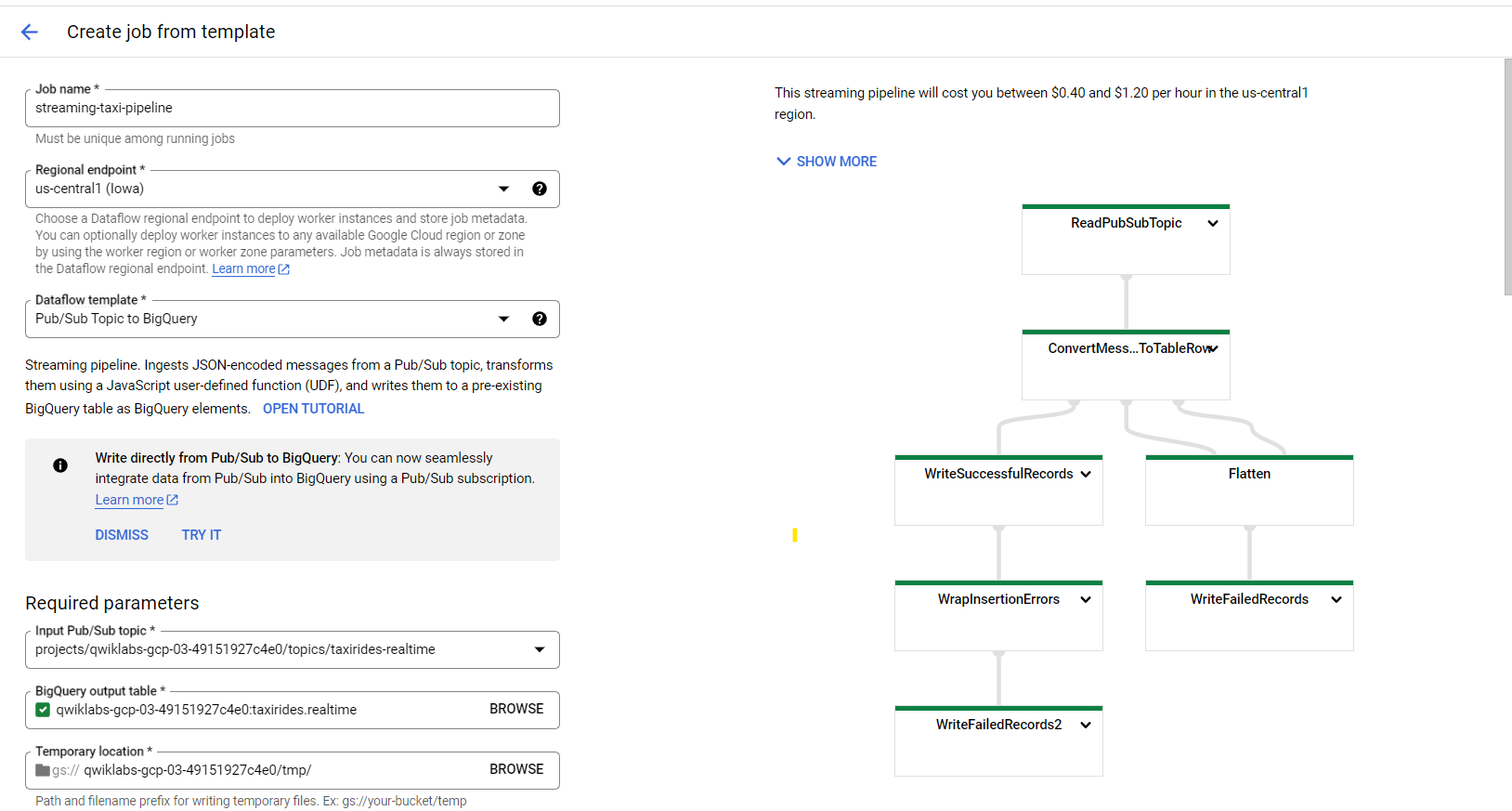
In the Temporary location area, choose “Browse” and then click “see child resources.” Click “Create new folder” and enter “temporary ” as the folder name. Click “New” and then “Select.”
Lastly, select “Show Optional Parameters” and enter 2 for “Max workers” and 1 for “Number of employees.” Once you’ve completed all of these fields, click “Run Job” to construct your new streaming pipeline.

A new streaming job has begun! A visual depiction of the data pipeline is now available. Data will begin to go into BigQuery in 3 to 5 minutes.

Step 4: Using Big Query, Analyze the Taxi Data
Go to the Big Query portion of the Cloud Console to execute the query in a Big Query on the Google Cloud Platform (GCP). To do so, go to the Navigation menu (three horizontal lines in the upper left corner of the screen) and select “Big Query.”
Just click “Done” to dismiss the Welcome window if it occurs. Next, in the upper left corner of the screen, click the “Compose Query” button to access the Query Editor.
Then, in the Query Editor, enter in your preferred SQL query. For example, you could type something like this:
SELECT * FROM trides.live LIMIT 10Output:

Conclusion
Finally, constructing a scalable and reliable pipeline is critical for data engineering and data scientists to tackle the four fundamental difficulties of big data, referred to as the four Vs.: variety, volume, velocity, and veracity. Google Dataflow and Pub/Sub are great tools for managing these difficulties and creating a streaming data pipeline that may deliver useful insights to fuel corporate success. Data may be ingested and processed into an elastic streaming pipeline using Dataflow and exported into an analytical data warehouse like Big Query using Pub/Sub to manage distributed message-oriented systems at scale. Lastly, data visualization tools like Looker and AI and machine learning (ML) technologies like Vertex AI may be linked to explore and reveal business insights or assist with forecasts. Businesses may use these technologies to generate real-time dashboards and make educated decisions in today’s data-driven society.
Key Takeaways:
- GCP provides multiple templates for streaming data pipelines in data engineering.
- The message-oriented architecture of pub/ sub makes streaming pipelines scalable.
- Streaming data can easily be analyzed with GCP Big query.
- Analyzed data can be moved to GCS or big query storage.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.







