This article was published as a part of the Data Science Blogathon.
Introduction
Big Query is a serverless enterprise data warehouse service fully managed by Google. Big Query provides nearly real-time analytics of massive data. A big Query data warehouse provides global availability of data, can be easily connected to the other Google Services and has a flexible data ingestion mechanism. Data warehouse solutions developed using Big Query are highly secured and scalable.

Source: https://cloud.google.com/architecture/bigquery-data-warehouse
We will discuss some important concepts and questions related to Google Big Query in this article.
Interview Questions for Big Query
Below are some important Big Query interview questions:
1. What is a Big Query?
Big Query is a serverless enterprise data warehouse service fully managed by Google. Big Query has a built-in query engine which makes it easy to run SQL queries. Big Query helps organizations to analyze large volumes of data to find meaningful insights.
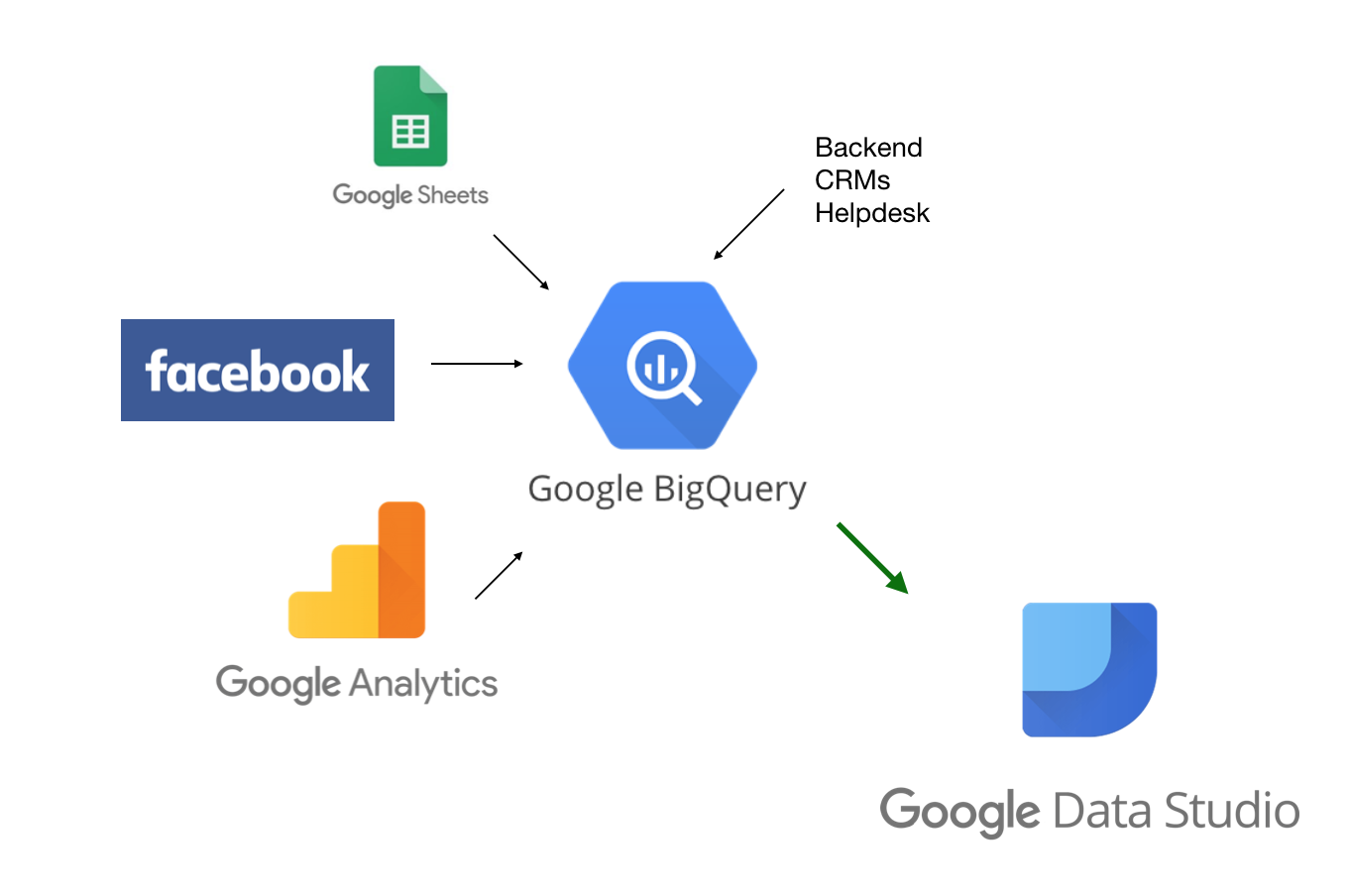
Source: https://www.business2community.com/marketing/google-bigquery-a-tutorial-for-marketers-02252216
2. What are the advantages of using Google Big Query?
Some advantages of Google Big Query are:
a. Big Query data warehouse is highly scalable and provides a pay-as-you-go costing model.
b. It is compatible with ETL tools like Informatica.
c. It provides high data security.
3. What is Query Cache in Big Query?
Query Cache speeds up data retrieval in Big Query. When any query gets executed for the first time in Big Query, the query results get stored in a temporary cached results table. This is known as Query Cache.
4. What is a time decorator in Big Query?
Time decorators allow us to access past data in Big Query. For example, if you have accidentally deleted a table one hour ago, then you can use a time decorator to get the deleted data.
5. How to convert one data type to another explicitly in Big Query?
We can convert one data type to another explicitly using conversion functions in Big Query. For example, to cast an expression to a string use the below syntax:
CAST (expr AS STRING)
6. What are the various ways in which the Big Query cloud data warehouse can be accessed?
We can access the Big Query cloud data warehouse using the one of the below ways:
a. JDBC drivers
b. ODBC drivers
c. Web UI
d. BQ command-line tool
e. Python libraries
7. What are some ways for optimizing query computation in Big Query?
Below are some ways for optimizing query computation in Big Query:
a. Prefer to use native UDFs, instead of JavaScript user-defined functions
b. For retrieving the latest record, use the aggregate analytic function
c. Perform optimization on table joining pattern.
8. What are some scenarios in which window functions can be used in Big Query?
Below are some scenarios in which window functions can be used in Big Query:
a. For calculating a moving average
b. For calculating the cumulative total
c. To rank rows based on specified criteria
9. Your data team is building a new real-time data warehouse for a client. The client wants to use Google Big Query for performing streaming inserts. You get a unique ID and an event timestamp whenever data gets inserted in the row but it is not guaranteed that data will only be sent in once. Which clauses and functions you will use to write a query which ensures that duplicates are not included while interactively querying data?
To ensure that duplicates are not included, use the ROW_NUMBER window function with PARTITION BY based on unique ID WHERE row equals to1.
10. An analytics company handles data processing for different clients. Clients use their own suite of analytics tools. Some clients have allowed direct query access via Google Big Query. You want to ensure that clients cannot see each other’s data. What steps can you perform inside Big Query to ensure the data security of clients?
To ensure that clients could not see each other’s data, the following steps could be taken:
a. For each client, load data into a different dataset.
b. Restrict a client’s dataset such that only approved users can access their dataset
c. For further security, use the relevant identity and access management (IAM) roles for each client’s users.
11. A client provides your company with a daily dump of data that flows into Google Cloud Storage as CSV files. How would you build a pipeline that will analyze the data stored in Google Cloud Storage in the Google Big Query when the data may contain rows which are formatted incorrectly or corrupted?
To build a pipeline for the above scenario follow the below steps:
a. Import the data from Google Cloud Storage to the Big Query by running Google Cloud Dataflow.
b. Push the corrupted rows to another dead-letter table for analysis.
12. You work as an analyst in an e-commerce company. You use Google Big Query to correlate the customer data with the average prices of the 50 most common products sold, including laptops, mobile phones, television, etc. After every 35 minutes, the average prices of these goods are updated. What steps you should follow to ensure that this average price data stays up to date so that you can easily combine it with other data in Big Query as cheaply as possible?
Follow the below steps to ensure that this average price data stays up to date so that you can easily combine it with other data in Big Query as cheaply as possible:
a. Create a regional Google Cloud Storage Bucket to store and update the average price data
b. Then, use the above-created Cloud Storage Bucket as a federated data source in Big Query.
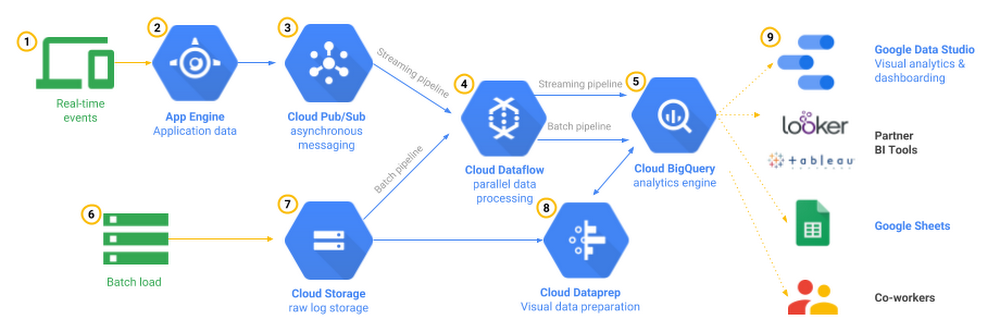
Source: https://cloud.google.com/blog/topics/developers-practitioners/bigquery-explained-data-ingestion
13. You are the team lead at a large analytics company. Currently, your organization is using an on-demand pricing model for Big Query which has a quota of 1999 concurrent on-demand slots per project. With the current pricing model, developers within your company sometimes don’t get enough slots to execute their queries. What change you should do in the pricing model to resolve the above issue?
To resolve the above issue, switch the current pricing model to a flat-rate pricing model. Apart from this, also set up a hierarchical priority model for your projects.
Conclusion
In this article, we have seen important Big Query questions. We got a good understanding of different Big Query terminologies. Below are some major takeaways from the above article:
1. We have seen query caching and what are the benefits of using Big Query.
2. We learned about various ways for performing query optimization in Big Query.
3. We got an understanding of how we can retrieve accidentally deleted data using a time decorator in Big Query.
4. Apart from this, we also saw some scenario-based questions on Google Big Query.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Full Stack developer with 2.6 years of experience in developing applications using
Azure, SQL Server & Power BI. I love to read and write blogs. I am always willing to learn new technologies, easily adaptable to changes, and have a good time
management, problem-solving, logical and communication skills






