This article was published as a part of the Data Science Blogathon.
Introduction
In today’s data-driven age, an enormous amount of data is getting generated every day from various sources such as social media, e-commerce websites, stock exchanges, transaction processing systems, emails, medical records, etc. This data is a combination of structured, unstructured, and semi-structured data and can come in-stream or batch form. This data keeps growing exponentially with time.

Source: https://kochasoft.com/fr/uncategorized-fr/google-bigquery-datawarehouse-for-s4-hana-system-3/
Organizations across the globe are focusing on how to get useful insights from the generated data. This is when the data warehouse came into the picture. A data warehouse is a system that aggregates the data produced from different data sources for data analysis and effective decision-making. Big Query is a serverless data warehouse Platform as a Service (PaaS) service provided by Google Cloud Platform. Big Query also provides the built-in capability for machine learning and a query engine for SQL.
In this article, we will discuss an overview of Big Query, the underlying architecture of Big Query, the benefits and use cases of Big Query, and how to import and query data in Big Query.
Google Big Query- Overview
Big Query is a serverless, scalable, and distributed data warehouse Platform as a Service (PaaS) service provided by Google Cloud Platform. We can store and analyze our data in Big Query or access the data directly from external sources using federated queries.
Big Query stores data in a Capacitor columnar storage format which is optimized for analytical queries. Machine learning and predictive analytics capability are also provided using Big Query ML. Big Query provides business intelligence support using Data Studio, Looker, etc.
Big Query provides high security using identity and access management (IAM). Big Query provides high flexibility as compared to other data warehouses by separating compute engine from the storage choices of the user.

Source: https://cloud.google.com/bigquery
We have seen a brief overview of Google Big Query till now. Let’s now understand the architecture of Big Query in detail.
Big Query Architecture
Big Query has a serverless and flexible architecture that allows storage and computing to scale independently. Such type of architecture offers cost control for customers and a built-in engine for SQL helps them to effectively analyze their data without worrying about system engineering and database operations.
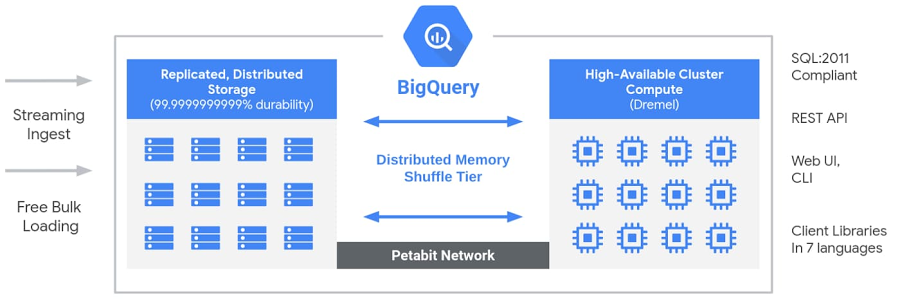
Source: https://cloud.google.com/blog/products/data-analytics/new-blog-series-bigquery-explained-overview
Beneath the surface, Big Query architecture uses a large number of multi-tenant services driven by low-level Google infrastructure technologies such as Colossus, Jupiter, Dremel, and Borg.
Colossus: For storing data, Big Query uses Colossus. Colossus ensures data security by performing data replication, data recovery, and distributed management.
Dremel: Dremel is a multi-tenant cluster used for computing purposes internally. SQL queries are turned into execution trees by Dremel for executing the queries.
Jupiter: Jupiter network is used by storage and computing to talk to each other.
Borg: Borg performs orchestration in Big Query.
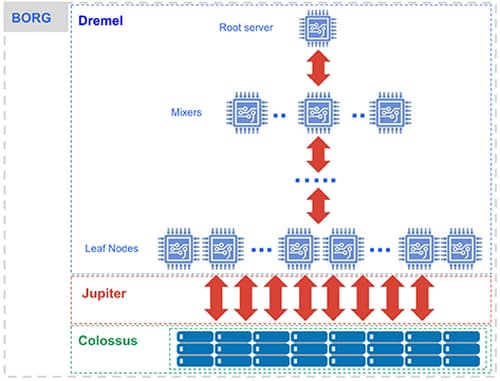
Source: https://cloud.google.com/blog/products/data-analytics/new-blog-series-bigquery-explained-overview
Benefits of using Google Big Query
Below are the benefits of using Google Big Query:
a. Improved business intelligence: Using Big Query, we can integrate data from multiple sources. Whether it is some external data source or data services in GCP, it is very easy to manage all the data in Big Query, which further contributes to a better decision-making process as now the scale of data is large and may contain complex data relationships.
b. Enhanced data quality and consistency: Big Query stores all the data in columnar storage format after compressing data using a compression algorithm. All the data is stored in the same format which ensures data uniformity. Thus, Big Query provides enhanced data quality and consistency.
c. Scalability and real-time performance: We can easily increase or decrease the amount of data and number of data sources in Big Query. Also, we can directly query external data sources from Big Query using the federated queries.
d. Security: It provides various security options using Identity and access management and roles.
e. High availability & fault tolerance: Data stored in Big Query is replicated across different regions to ensure high availability and better fault tolerance.
Big Query Use Cases
Below are some use cases for Google Big Query:
- Ecommerce recommendation system: Google Big Query can be used for developing an e-commerce recommendation system. Big Query ML could be used to generate product recommendations from customer review data. Apart from this, we can also predict customer Lifetime value by using Vertex AI.
- Migrating data warehouses: For accelerating real-time insights, organizations may prefer to migrate their existing data warehouses to the Google Big Query. We can easily migrate data warehouses from Snowflake, Redshift, Teradata, etc. to Big Query.
- Supply chain analytics: For better risk management, predicting equipment availability, and labour shortage it is best to use advanced predictive capabilities. Big Query ML could be used to predict equipment availability based on previous data. Thus, Big Query can be used in supply chain analytics applications to provide a better way of labour management and equipment availability.
Importing and Querying data in Big Query
To get started with working in Big Query, you can either create an account on GCP or use the Big Query sandbox.
To use the sandbox, visit the below link and log in with your Google account:
https://console.cloud.google.com/bigquery
Now, follow the below steps:
Step 1. After logging in to the sandbox, click on Create New Project.
.png)
Step 2: Enter the project name and parent organization or folder name. Then, click CREATE. After the project gets created, select and view the project in the sandbox.
.png)
.png)
Step 3: Now, visit https://www.kaggle.com/datasets/surajjha101/stores-area-and-sales-data and download the Supermarket store branches’ sales analysis dataset.
.png)
Step 4: Click Resource-> Big Query-> ProjectName -> Create dataset
.png)
Step 5: Provide stores as Dataset ID, Data location and click CREATE DATASET.
.png)
Step 6: Click stores-> Create table
.png)
Step 7: Select create table from upload, then choose the file downloaded from Kaggle, provide table name, table type, schema, and partitioning settings.
.png)
Step 8: Now, go to the created table by clicking the GO TO TABLE button. You can see schema details, row access policies, and edit schema if you want.
.png)
Step 9: To query the table, click the QUERY button. This will open the query editor.
Step 10: To find the details of stores, where the count of daily customers is greater than 1000, run the below query in the query editor:
SELECT * FROM `bigqueryex-353511.stores.store` WHERE Daily_Customer_Count>1000;
The below results are generated after the query execution:
.png)
Conclusion
In this article, we have seen how we can store a huge amount of data using Google Big Query to gain useful insights from the collected data. Below are some major takeaways about Big Query:
1. We have seen how Big Query provides machine learning and predictive analytics capability using Big Query ML.
2. We got a deep understanding of the architecture of Big Query and functions performed by various low-level Google infrastructure technologies.
3. We have seen what are the benefits of using Big Query.
4. We learnt how we can import and query data in Big Query with the help of a sandbox.
5. Apart from this, we also saw some use cases in which Google Big Query can be used.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Full Stack developer with 2.6 years of experience in developing applications using
Azure, SQL Server & Power BI. I love to read and write blogs. I am always willing to learn new technologies, easily adaptable to changes, and have a good time
management, problem-solving, logical and communication skills






