Introduction
Artificial intelligence has seen a revolution Moreover, with the emergence of foundation models (FM), opening the door to ground-breaking developments in a number of fields. Specifically, researchers use large volumes of unlabeled data to train these powerful AI models, which gives them the versatility to serve as the basis for a variety of task solutions. Additionally, with their incredible scalability, versatility, and efficiency, Generative AI Foundation Models have evolved into vital tools that have advanced fields like computer vision and natural language processing.
Learning Objectives:
- Understand the concept and significance of foundation models in AI
- Explore different types of foundation models for NLP and computer vision
- Learn how researchers train foundation models and apply them to downstream tasks.
- Grasp the importance and challenges of 3D foundation modeling in AI development
Table of Contents
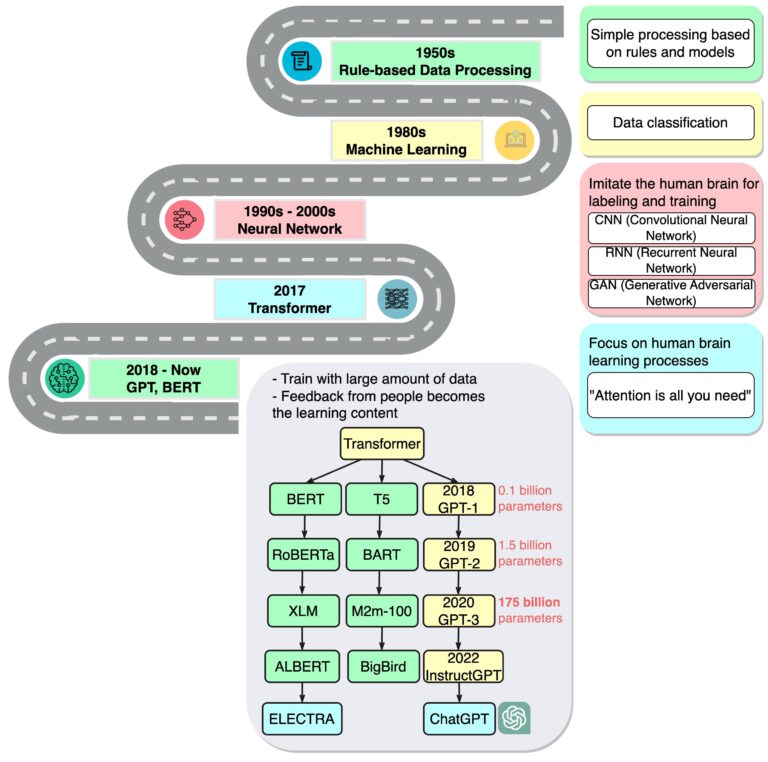
History of Foundation Models
We all might have worked with pretrained models for solving variety of tasks related to text and images. But do you know why we use pretrained models in the first place? The reason behind it is its ability to generalize well on the other tasks. These pretrained models are trained on a huge amounts of labeled datasets. This limits the model to use the large volumes of available unlabeled data. This led to the research in building the models that can make use of the unlabeled datasets.
The term generative ai foundation models was first coined by the Stanford AI team. These models were indirectly known to us as Large Language Models a.k.a LLMs.
How it gets Transformers ?
Transformers was the first breakthrough in the domain of Natural Language Processing back in 2017. It’s a large language model relying on the attention mechanisms. It trains on massive datasets and observers noted that it generalizes well to other tasks by successfully applying it with limited data.
This opened up the research around LLMs to explore its capabilities. In 2018, the another 2 popular LLMs were introduced by Google and OpenAI: BERT and GPT.
Next, an intriguing research topic emerged regarding the scaling up of transformer models . It involved examining whether increasing the model’s size and complexity enhances the model performance or increasing the amount of data would enhance its performance.
In 2019, Open AI released a GPT-2, a LLM with 1.5 billion parameters and later on in 2020, GPT-3 by scaling GPT 2 by 116x (with 175 billion parameters). Thats huge!
But the concern with these LLMs is that these LLMs can produce harmful outputs as well. There must be a way to control the outputs generated by LLM. This led to the work in aligning the language models with the instructions. Finally, instruction aligned models like InstructGPT, ChatGPT, AutoGPT have been a sensation world wide.
What are Foundation Models?
In AI, researchers train models on huge amounts of unlabeled datasets, and these models can solve multiple downstream tasks.

For example, researchers can use 3D Foundation models trained on text data to solve problems related to text, such as Question Answering, Named Entity Recognition, Information Extraction, and so on. Similarly, Foundation models trained on images can solve problems related to images like image captioning, object recognition, image search, etc.
They are not just limited to text and images but can also be trained on different types of data like audios, videos, and 3D signals.
The lay the strong base for solving other tasks. Hence, the Stanford team introduced the term “Foundation Models”. The best thing about them is that they can be easily trained without the dependency of a labeled dataset.
But why do we need Foundation Models in the first place? Let’s figure it out.
Also Read: AI and Beyond: Exploring the Future of Generative AI
Why Foundation Models?
There are 3 primary reasons for the need are:
All in One
Generative AI foundation models are extremely powerful. They have removed the need to train different models for different tasks otherwise would have been the case. Now, it’s just one single model for all the problems.
Easy to Train
These models are easy to train as there is no dependency on labeled data. And little effort is required to adapt it to our specific task.
Foundation models are task agnostic
If not models, we would need hundreds of thousands of labeled data points to achieve the high performance model for our task. But using Foundation models, it’s just a couple of examples required to adapt it to our task. We will discuss in detail on how to use Foundation models for our tasks in a while.
High Performance
Foundation models help us build very high performance models for our tasks. Researchers build the State Of The Art (SOTA) architectures for various tasks in Natural Language Processing and Computer Vision on top of the Foundation models.
What are the Different Foundation Models?
Models are classified into different types based on the domain that they are trained on. Broadly, it can be classified into 2 types.
- Foundation Models for Natural Language Processing
- Foundation Models for Computer Vision
Foundation Models for Natural Language Processing
Large Language Models (LLMs) are the Foundation models for Natural Language Processing. Researchers train large language models on massive amounts of datasets to learn the patterns and relationships present in the textual data. The ultimate goal of LLMs is to learn how to represent the text data accurately.
The powerful AI technologies in today’s world rely on LLMs. For example, ChatGPT uses the GPT-3.5 as the Generative AI foundation models and AutoGPT, the latest AI experiment is based on GPT-4.
Here is the list of FM for NLP: Transformers, BERT, RoBERTa, variants of GPT like GPT, GPT-2, GPT-3, GPT-3.5, GPT-4 and so on.
In the next section, we will discuss how we train these Large Language Models.
Foundation Models for Computer Vision
Diffusion models are popular examples of 3D Foundation models for computer vision. Diffusion models have emerged as a powerful new family of deep generative models with state of the art performance in multiple use cases like image synthesis, image search, video generation, etc. They have outperformed auto encoders, variational autoencoders, GANs with its imagination and generative capabilities.
The most powerful text to image models like Dalle 2 and Midjourney use the diffusion models behind the hood. Diffusion models can also act as Foundation models for NLP and different multimodal generation tasks like text to video, text to image, as well.
Now, we will discuss how to use Foundation models for downstream tasks.
How Can We Use the Foundation Models?
Till now, we have seen Foundation models and different types of them. Now, we will see how to make use of these models on the downstream tasks after training them.
There are 2 ways to do it. Finetuning and Prompting
The fundamental difference between finetuning and prompting is that
Finetuning change the model itself whereas prompting changes the way to use it.
Finetuning
To begin with, Firstly, finetuning the Foundation models involves customizing them on the specific dataset for the task at hand. Next, we will tailor the model to suit our dataset’s requirements precisely. This process requires a dataset comprising hundreds or thousands of examples, complete with target labels necessary for refining the model.
The foundation model is trained on a generic domain dataset. By fine tuning, we are adapting the model parameters specific to our dataset. This technique solves the pain of having the labeled dataset to some extent but not fully.
Here comes the prompting!
Prompting
Prompting allows us to use the foundation model to solve a particular task just through a set of examples. It doesn’t involve any model training. All you need to do is to prompt the model to solve the task. This process is known as in-context learning because the model learns from the context, specifically given a set of examples.
Cool right?
Prompting involves providing design cues or conditions to a network through a few examples in order to solve specific tasks. Furthermore, as illustrated below, when researchers deal with LLMs, they provide a set of task-related examples, and they expect the model to predict the target by filling in the blank space or the next token in the sentence.
Observing language models learn from examples is a fascinating experience because they are not explicitly trained to do so. Rather, their training revolves around predicting the next token in a given sentence. This seems to be almost magical.

How are Foundation Models Trained?
As discussed, researchers train Foundation models on the unlabeled datasets in a self-supervised manner. In self-supervised learning, there is no explicitly labeled dataset. The model automatically creates the labels from the dataset itself and then researchers train the model in a supervised manner. That’s the fundamental difference between supervised learning and self supervised learning.
There are different 3D Foundation Models in NLP and computer vision but the underlying principle of training these models is similar. Let’s understand the training process now.
Large Language Models
As discussed, Large Language Models a.k.a LLMs are the FM for NLP. All these Large Language Models are trained in a similar way but differ in the model architecture. The common learning objective is to predict the missing tokens in the sentence. The missing token can be a next token or anywhere in the text.
Hence, LLMs can be classified into 2 types based on learning objective: Causal LLM and Masked LLM. For example, researchers train GPT, a causal LLM, to predict the next token in the text, whereas they train BERT, a Masked LLM, to predict the missing tokens present anywhere in the text.

Diffusion Models
Consider we have an image of a dog, we apply gaussian noise to it, then we end up with an unclear image. Now, we repeat this process, apply gaussian noise several times to the image, then we end up with a complete noise. And the image is unrecognizable.

Is there a way to undo the unidentified image to the actual image? That’s exactly what diffusion models do.
Diffusion models learn to undo this process of converting the noisy image into its actual and original image.
In simple terms, diffusion models learn to denoise the image. Diffusion models are trained in a 2 step process:
- Forward Diffusion
- Reverse Diffusion
Forward Diffusion
In the forward diffusion step, the process converts the training image to a completely unrecognizable image. This process is fixed and does not require any network for learning, unlike the Variational Auto Encoders (VAEs). In VAE, the encoder and decoder are two different networks that researchers jointly train to convert the image into latent space and back into the original image.

Imagine the process to be similar to ink diffusion in the water. Once the ink diffuses in the water, it’s completely gone. We will not be able to track it.
Reverse Diffusion
Here is the interesting step known as Reverse Diffusion. This is where the actual learning is happening.
In reverse diffusion, the network converts the unrecognizable image back into the original image. The single network trains to convert the noise back into the image. Isn’t it interesting?

Importance of Foundation Modeling
In the realm of artificial intelligence, Moreover, foundation modeling revolutionizes methods. Specifically, foundation modeling involves creating large-scale models that serve as the “foundation” or basis for many AI applications and tasks. Additionally, recent advances in machine learning and the accessibility of enormous amounts of data have significantly contributed to the concept’s notable upsurge in popularity. Furthermore, foundation modeling holds crucial importance in several key areas:
Flexibility and Adaptability
Researchers can easily adjust or customize foundation models to carry out a wide range of activities in other areas.Contrary to conventional AI models, which often serve specific purposes, foundation models exhibit high adaptability. Their flexibility allows for rapid implementation of AI solutions without the need to create brand-new models for each use case.
Efficiency and Cost-Effectiveness
Developing a foundation model is resource-intensive, requiring significant computational power and data. However, once we develop these models, we can reuse and repurpose them, which can lead to reducing costs and increasing efficiency in AI development. By sharing and building upon foundation models, researchers and developers can avoid duplicating efforts, accelerating the pace of innovation.
Scalability
Foundation models are designed to be scalable, handling tasks of varying complexities and sizes. This scalability ensures that the AI can grow with the problem, providing consistent performance even as the demands of the task increase. As a result, foundation models are suitable for both small-scale applications and large, complex systems.
Advancements in Language Understanding
One of the most notable successes in foundation modeling is within the realm of natural language processing (NLP). Moreover, models like GPT-3 have demonstrated remarkable language understanding and generation capabilities. They enable AI to write coherent text, answer questions, translate languages, and even generate code. Furthermore, these advancements are paving the way for more intuitive and human-like interactions with technology.
Enabling Transfer Learning
Foundation models embody the principle of transfer learning, where knowledge learned from one task can assist in learning another. This approach leverages the general knowledge encoded in the model to quickly adapt to new tasks with minimal additional training. Transfer learning is particularly valuable in scenarios where data is scarce or when rapid development is necessary.
Challenges and Ethical Considerations
While the benefits of foundation modeling are clear, it also raises important challenges and ethical considerations. The development of these models often requires vast datasets, however, which may contain biases or sensitive information. Addressing the responsible use of foundation models and mitigating potential harms is a critical area of ongoing research.
What Next?
At present, our understanding of Foundation Models is well-defined. The subsequent stage involves developing a comprehensive understanding and proficiency in either Foundation Models for NLP or Foundation Models for Computer Vision, depending on your area of interest.
In case of Foundation models for NLP, you need to build indepth knowledge around LLMs. It includes building LLMs from scratch, training and finetuning LLMs on your dataset and grasping the most effective methods for deploying them in production.
Similarly, for Foundation Models for Compuer Vision, you need to have a thorough understanding of diffusion models, including their creation from the ground up, training and fine-tuning on your datasets, and effective deployment strategies.
Conclusion
The rise of foundation models has ushered in a new era of innovation in artificial intelligence. As our understanding of these models continues to deepen, we stand at the precipice of groundbreaking advancements. Whether it’s natural language processing or computer vision, foundation models hold the key to unlocking remarkable capabilities. However, it is crucial to navigate this exciting journey with a keen eye on responsible development and ethical considerations. By addressing these challenges head-on, we can harness the full potential of foundation models, propelling technological progress while ensuring a future that harmonizes AI and human values.
Key Takeaways:
- Firstly, foundation models train on large unlabeled datasets and can solve multiple tasks
- Secondly, Large Language Models (LLMs) and diffusion models are key examples of foundation models
- Moreover, Finetuning and prompting represent two main ways to use foundation models for specific tasks
- Finally, foundation models offer flexibility, scalability, and cost-effectiveness in AI applications
Frequently Asked Questions
Q1. What are foundation models in AI?
A. Foundation models in AI serve as fundamental architectures trained on vast datasets to perform various tasks. They form the basis for developing more specialized AI models and applications.
Q2. What is the difference between LLM and foundation model?
A. A foundation model encompasses a broader scope and capabilities, whereas a Large Language Model (LLM) typically refers to specific models like GPT that excel in natural language processing tasks.
Q3. Is GPT-4 a foundation model?
A. Yes, you can consider GPT-4 a foundation model because it serves as a base architecture trained on diverse data to handle various natural language understanding and generation tasks.
Q4. Is ChatGPT a foundation model?
A. Yes, ChatGPT is indeed a foundation model as it is built on the GPT architecture and trained to facilitate interactive conversations and perform a wide range of language-based tasks.







