Introduction
How does your phone predict your next word, or how does an online tool fine-tune your emails effortlessly? The powerhouse behind these conveniences are Large Language Models. But what exactly are these LLMs, and why are they becoming a hot topic of conversation?
The global market for these advanced systems hit a whopping $4.35 billion in 2023 and is expected to keep growing at a rapid 35.9% every year from 2024 to 2030. One big reason for this surge? LLMs can learn and adapt themselves without any human supervision. It’s pretty impressive stuff! But with all the hype, it’s natural to have questions. Whether you’re a student, a professional, or someone who loves exploring digital innovations, this article answers all your common questions around LLMs.
Take your AI innovations to the next level with GenAI Pinnacle. Fine-tune models like Gemini and unlock endless possibilities in NLP, image generation, and more. Dive in today! Explore Now
Table of contents
- Introduction
- Why should I know about LLMs?
- What is a Large Language Model (LLM)?
- How can I build applications using LLM?
- What is Prompt Engineering?
- What is RAG and how is it different from Prompt Engineering?
- What is fine-tuning of LLMs and what are the advantages of fine-tuning a LLM over a RAG based system?
- Should we consider training a LLM from scratch?
- Conclusion
Why should I know about LLMs?
Most of us are interacting with the below screens almost daily, aren’t we?

And, I generally use it for taking help for various tasks like:
- Re-writing my emails
- Take a start on my initial thoughts on any potential ideas
- Have also experimented with an idea that these tools can be my mentor or coach as well?
- Taking summary for research paper and bigger documents as well. And there is a long list.
But, do you know how these tools are able to solve all different types of problems? I think most of us know the answer. Yes, it is using “Large Language Models (LLMs)”.
There are broadly 4 types of users of LLMs or Generative AI.
- User: Interact with above screens and get their responses.
- Super User: Generate more out of these tools by applying the right techniques. They can generate responses based on their requirement by giving the right context or information known as prompt.
- Developer: Build or modify these LLMs for their specific need using techniques like RAG or Fine-tuning.
- Researcher: Innovate and build evolved versions of LLMs.
I think all user types should have a broad understanding about “What is LLM?” however for user category two, three and four, in my view it is a must to know. And, as you move towards the Super User, Developer and Researcher category, it will start becoming more essential to have a deeper understanding about LLMs.
You can also follow Generative ai learning path for all user categories.
Commonly known LLMs are GPT 3, GPT 3.5, GPT 4, Palm, Palm 2, Gemini, Llama, Llama 2 and many others. Let’s understand what LLM is.
What is a Large Language Model (LLM)?
Let’s break down what Large Language Models into “Large” and “Language Models”. Language models assign probabilities to groups of words in sentences based on how likely these word combinations occur in the language.
Consider these sentences
- Sentence 1: “You are reading this article”,
- Sentence 2: “Are we reading article this?” and,
- Sentence 3: “Main article padh raha hoon” (in Hindi).
The language model assigns the highest probability to the first sentence (around 85%) as it is more likely to occur in English. The second sentence, deviating from grammatical sequence, gets a lower probability (35%), and the third, being in a different language, receives the lowest probability (2%). And this is what exactly these language models do.

The language models assign the higher probability to the group of words, which is more likely to occur in the language based on the data they have seen in the past. These models work by predicting the next most likely word to occur following the previous words. Now that the language model is clear, you would be asking what is “Large” here?
In the past, models were trained on small datasets with fewer parameters (weights and biases of the neural network). Modern LLMs are 2000 times larger, with billions of parameters. Researchers found that increasing model size and training data makes these models smarter and approaching human-level intelligence.

So, a large language model is one with an enormous number of parameters, trained on internet scale datasets. Unlike regular language models, LLMs not only learn language probabilities but also gain intelligent properties. They become systems that can think, innovate, and communicate like humans.
For instance, GPT-3, with 175 billion parameters, can perform tasks beyond predicting the next word. It gains emergent properties during training, allowing it to solve various tasks, even ones it wasn’t explicitly trained for, like machine translation, summarization, translation, classification and many more.
How can I build applications using LLM?
We have hundreds of LLM-driven applications. Some of the most common examples include GitHub Copilot, a widely used tool among developers. GitHub Copilot streamlines coding processes, with more than 37,000 businesses and one in every three Fortune 500 companies adopting it. This powerful tool enhances developer productivity by over 50%.

Another one is Jasper.AI. It transforms content creation. With this LLM-powered assistant, users can generate high-quality content for blogs and email campaigns instantly and effectively.

Chat PDF introduces a unique way to interact with PDF documents, allowing users to have conversations about research papers, blogs, books, and more. Imagine uploading your favorite book and engaging while interacting in chat format.

There are four different methods to build LLM applications:
- Prompt Engineering: Prompt engineering is like giving clear instructions to LLM or generative AI based tools to get accurate responses.
- Retrieval-Augmented Generation (RAG): In this method, we combine knowledge from external sources with LLM to get a more accurate and relevant outcome.
- Fine-Tuning Models: In this method, we customized a pre-trained LLM for a domain specific task. For example: We have fine tuned “Llama 2” on code related data to build “Code Llama” and “Code Llama” outperforms “Llama 2” on coding related tasks as well.
- Training LLMs from Scratch: In this method, we want LLMs like GPT-3.5, Llama, Falcon and so on. In simple terms, here we train a language model on a large volume of data.
What is Prompt Engineering?
We get responses from ChatGPT-like tools by giving textual input. This input is known as “Prompt”.
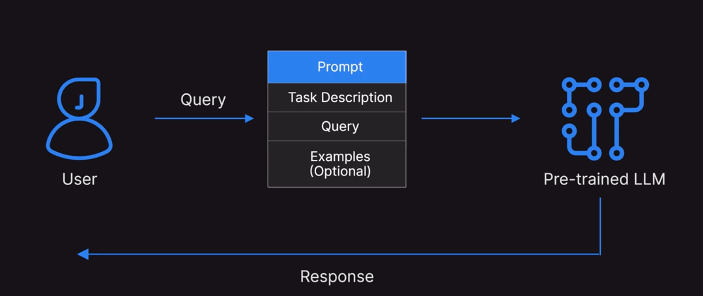
We often observe that response changes if you change our input. And, based on the quality of input or prompt we get better and relevant responses. Writing this quality prompt to get desired response is known as Prompt Engineering. And, Prompt Engineering is an iterative process. We first write a prompt and then look at the response and post that we modify or add more context to input and be more specific to get the desired response.
Types of Prompt Engineering
Zero Shot Prompting
In my view, we all have already used this method of prompting. Here we are just trying to get a response from LLM based on its existing knowledge.

Few shots Prompting
In this technique, we provide a few examples to LLM before looking for a response.

You can compare the outcome with zero shot and few shots prompting.
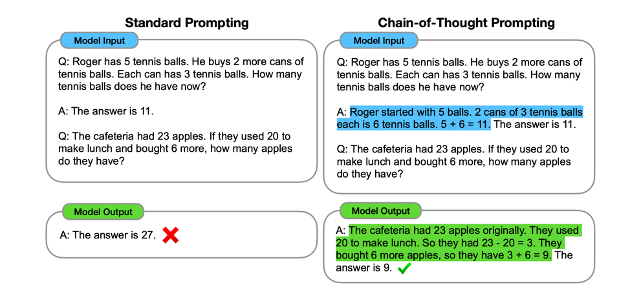
Chain of thoughts Prompting
In simple terms, Chain-of-Thought (CoT) prompting is a method used to help language models to solve difficult problems. In this method, we are not only providing examples but also break down the thought process step by step. Look at the below example:
What is RAG and how is it different from Prompt Engineering?
What do you think? Will you get the right answer to all your questions from ChatGPT or similar tools? No, because of only one reason. LLM behind ChatGPT is not trained on the dataset that has the right answer to your question or query.
Currently ChatGPT knowledge base is limited till January 2022, and if you ask any question beyond this timeline you may get an invalid or non-relevant result.
Similarly, if you ask questions related to private information specific to enterprise data, you will again get an invalid or non-relevant response.
Here, RAG comes to rescue you!
It helps us to combine knowledge from external sources with LLM to get a more accurate and relevant outcome.
Look at the below image where it follows the following steps to provide a relevant and valid response.
- User Query first goes to a RAG based system where it fetches relevant information from external data sources.
- It combines User query with relevant information from external source and send it to LLM
- Step 3: LLM generates responses based on both knowledge of LLM and knowledge from external data sources.

At a high level, you can say that RAG is a technique that combines prompt engineering with content retrieval from external data sources to improve the performance and relevance of LLMs.
What is fine-tuning of LLMs and what are the advantages of fine-tuning a LLM over a RAG based system?
Let’s understand a business case. We want to interact with LLM for queries related to the pharma domain. LLMs like GPT 3.5, GPT 4, Llama 2 and others can respond to general queries and may respond to Pharma related queries as well but do these LLMs have sufficient information to provide the right response? My view is, if they are not trained on Pharma related data, then they can’t give you the right response.
In this case, we can have a RAG based system where we can have Pharma data as an external source and we can start querying with it. Great. This will definitely give you a better response. What if we want to bring large volume information related to pharma domain in the RAG system here we will struggle.
In a RAG based system, we can bring missing knowledge through external data sources. Now the question is how much information you can have as an external source. It is limited and as you increase the size of external data sources, performance generally decreases.
Second challenge is retrieving the right documents from an external source is also a task and we have to be accurate to get the right response and we are improving on this part day-on-day.
We can solve this challenge using the Fine-tuning LLM method. Fine-tuning helps us customize a pre-trained LLM for a domain specific task. For example: We have fine tuned “Llama 2” on code related data to build “Code Llama” and “Code Llama” outperforms “Llama 2” on coding related tasks as well.

For Fine-tuning, we follow below steps:
- Take a pre-trained LLM (Like Llama 2) and parameters
- Retrain the parameters of a pre-trained model on domain specific dataset. This will give us Finetuned LLM retrained on domain specific knowledge
- Now, user can interact with Finetuned LLM.

Broadly, there are two methods of fine tuning LLMs.
- Full Fine-tuning: Retrain all parameter of pre-trained LLM leads to more time and more computation
- Parameter Efficient Fine-Tuning (PEFT): Fraction of parameters trained on our domain specific dataset.There are different techniques for PEFT.
- LoRA
- AdaLoRA
- QLoRA
Should we consider training a LLM from scratch?
Let’s first understand what do we mean by “Training LLM from scratch” post that we will look at why we should consider it as an option?
Training LLM from scratch refers to building the pre-trained LLMs like the GPT-3, GPT-3.5, GPT-4, Llama-2, Falcon and others. The process of training LLM from scratch is also referred to as pre-training. Here we train LLM on the massive scale of internet data with training objective is to predict the next word in their text.

Training your own LLMs gives you higher performance to your specific domain. It is a challenging task. Let’s explore these challenges individually.
- Firstly, a substantial amount of training data is required. Few examples like GPT-2, utilized 4.5 GBs of data, while GPT-3 employed a staggering 517 GBs.
- Second is compute power. It demands significant hardware resources, particularly a GPU infrastructure. Here is some examples:
- Llama-2 was trained on 2048 A100 80 GB GPUs with a training time of approximately 21 days for 1.4 trillion tokens or something like that.

Researchers have calculated that GPT-3 was trained using 1024 A100 80 GB GPUs for as low as 34 days

Imagine, if we have to train GPT-3 on a single V100 Nvidia GPU. Can you guess the time
it would take to train it? Training GPT-3 with 175 billion parameters would require about 355 years to train.
This clearly shows that we would need a parallel and distributed architecture for training these models. And, in this method the cost incurred is very high compared to Fine tunning, RAG and other methods.
Above all, you also need a Gen AI scientist who can train LLM from scratch effectively.
So, before going ahead with thinking about building your own LLM, I would recommend you to think multiple times before going ahead with this option because it will require following:
- Millions of dollars
- Gen AI Scientist
- Massive dataset with high quality (very important)
Now coming to the key advantages of training your own LLMs:
- Having the domain specific element improves the performance of the domain related tasks
- It also allows you an independence.
- You are not sending your data through API out of your server.
Conclusion
Through this article, we’ve uncovered the layers of LLMs, revealing how they work, their applications, and the art of leveraging them for creative and practical purposes. Yet, as comprehensive as our exploration has been, it feels we’re only scratching the surface.
So, as we conclude, let’s view this not as the end but as an invitation to continue exploring, learning, and innovating with LLMs. The questions answered in this article provide a foundation, but the true adventure lies in the questions that are yet to ask. What new applications will emerge? How will LLMs continue to evolve? And how will they further change our interaction with technology?
The future of LLMs is like a giant, unexplored map, and it’s calling us to be the explorers. There are no limits to where we can go from here.
If you’ve got questions bubbling up, ideas you’re itching to share, or just a thought that’s been nagging at you, drop it in the comments.
Let’s keep the conversation going!
Dive into the future of AI with GenAI Pinnacle. From training bespoke models to tackling real-world challenges like PII masking, empower your projects with cutting-edge capabilities. Start Exploring
Sunil Ray is Chief Content Officer at Analytics Vidhya, India's largest Analytics community. I am deeply passionate about understanding and explaining concepts from first principles. In my current role, I am responsible for creating top notch content for Analytics Vidhya including its courses, conferences, blogs and Competitions.
I thrive in fast paced environment and love building and scaling products which unleash huge value for customers using data and technology. Over the last 6 years, I have built the content team and created multiple data products at Analytics Vidhya.
Prior to Analytics Vidhya, I have 7+ years of experience working with several insurance companies like Max Life, Max Bupa, Birla Sun Life & Aviva Life Insurance in different data roles.
Industry exposure: Insurance, and EdTech
Major capabilities: Content Development, Product Management, Analytics, Growth Strategy.






