MapReduce is a programming model for processing large data sets with a parallel , distributed algorithm on a cluster (source: Wikipedia). Map Reduce when coupled with HDFS can be used to handle big data. The fundamentals of this HDFS-MapReduce system, which is commonly referred to as Hadoop was discussed in our previous article.
The basic unit of information, used in MapReduce is a (Key,value) pair. All types of structured and unstructured data need to be translated to this basic unit, before feeding the data to MapReduce model. As the name suggests, MapReduce model consist of two separate routines, namely Map-function and Reduce-function. This article will help you understand the step by step functionality of Map-Reduce model.The computation on an input (i.e. on a set of pairs) in MapReduce model occurs in three stages:
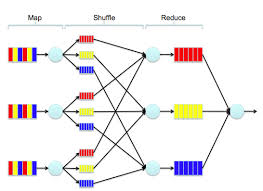
Step 1 : The map stage
Step 2 : The shuffle stage
Step 3 : The reduce stage.
Semantically, the map and shuffle phases distribute the data, and the reduce phase performs the computation. In this article we will discuss about each of these stages in detail.
[stextbox id=”section”] The Map stage [/stextbox]
MapReduce logic, unlike other data frameworks, is not restricted to just structured datasets. It has an extensive capability to handle unstructured data as well. Map stage is the critical step which makes this possible. Mapper brings a structure to unstructured data. For instance, if I want to count the number of photographs on my laptop by the location (city), where the photo was taken, I need to analyze unstructured data. The mapper makes (key, value) pairs from this data set. In this case, key will be the location and value will be the photograph. After mapper is done with its task, we have a structure to the entire data-set.
In the map stage, the mapper takes a single (key, value) pair as input and produces any number of (key, value) pairs as output . It is important to think of the map operation as stateless, that is, its logic operates on a single pair at a time (even if in practice several input pairs are delivered to the same mapper). To summarize, for the map phase, the user simply designs a map function that maps an input (key, value) pair to any number (even none) of output pairs. Most of the time, the map phase is simply used to specify the desired location of the input value by changing its key.
[stextbox id=”section”] The shuffle stage [/stextbox]
The shuffle stage is automatically handled by the MapReduce framework, i.e. the engineer has nothing to do for this stage. The underlying system implementing MapReduce routes all of the values that are associated with an individual key to the same reducer.
[stextbox id=”section”] The Reduce stage [/stextbox]
In the reduce stage, the reducer takes all of the values associated with a single key k and outputs any number of (key, value) pairs. This highlights one of the sequential aspects of MapReduce computation: all of the maps need to finish before the reduce stage can begin. Since the reducer has access to all the values with the same key, it can perform sequential computations on these values. In the reduce step, the parallelism is exploited by observing that reducers operating on different keys can be executed simultaneously. To summarize, for the reduce phase, the user designs a function that takes in input a list of values associated with a single key and outputs any number of pairs. Often the output keys of a reducer equal the input key (in fact, in the original MapReduce paper the output key must equal to the input key, but Hadoop relaxed this constraint).
Overall, a program in the MapReduce paradigm can consist of many rounds (usually called jobs) of different map and reduce functions, performed sequentially one after another.
[stextbox id=”section”] An example [/stextbox]
Let’s consider an example to understand Map-Reduce in depth. We have the following 3 sentences :
1. The quick brown fox
2. The fox ate the mouse
3. How now brown cow
Our objective is to count the frequency of each word in all the sentences. Imagine that each of these sentences acquire huge memory and hence are allotted to different data nodes. Mapper takes over this unstructured data and creates key value pairs. In this case key is the word and value is the count of this word in the text available at this data node. For instance, the 1st Map node generates 4 key-value pairs : (the,1), (brown,1),(fox,1), (quick,1). The first 3 key-value pairs go to the first Reducer and the last key-value go to the second Reducer.
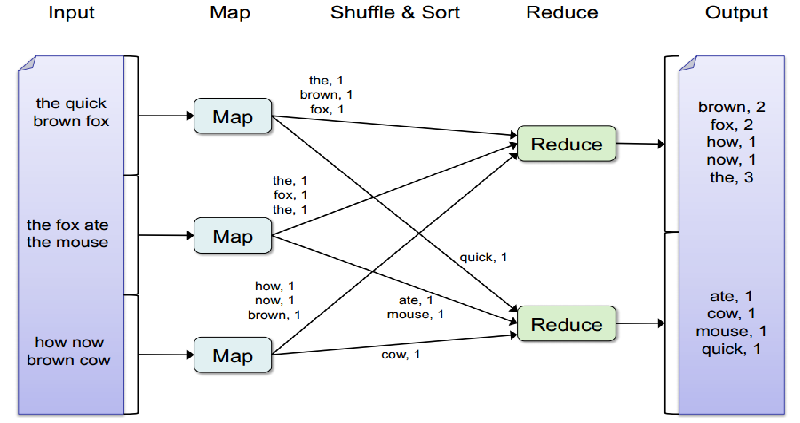
Similarly, the 2nd and 3rd map functions do the mapping for the other two sentences. Through shuffling, all the similar words come to the same end. Once, the key value pairs are sorted, the reducer function operates on this structured data to come up with a summary.
[stextbox id=”section”] End Notes : [/stextbox]
Let’s take some example of Map-Reduce function usage in the industry :
• At Google:
– Index building for Google Search
– Article clustering for Google News
– Statistical machine translation
• At Yahoo!:
– Index building for Yahoo! Search
– Spam detection for Yahoo! Mail
• At Facebook:
– Data mining
– Ad optimization
– Spam detection Example
• At Amazon:
– Product clustering
– Statistical machine translation
The constraint of using Map-reduce function is that user has to follow a logic format. This logic is to generate key-value pairs using Map function and then summarize using Reduce function. But luckily most of the data manipulation operations can be tricked into this format. In the next article we will take some example like how to do data-set merging, matrix multiplication, matrix transpose, etc. using Map-Reduce.
Did you find the article useful? Share with us any other practical examples of Map-Reduce function. Do let us know your thoughts about this article in the box below.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Tavish Srivastava, co-founder and Chief Strategy Officer of Analytics Vidhya, is an IIT Madras graduate and a passionate data-science professional with 8+ years of diverse experience in markets including the US, India and Singapore, domains including Digital Acquisitions, Customer Servicing and Customer Management, and industry including Retail Banking, Credit Cards and Insurance. He is fascinated by the idea of artificial intelligence inspired by human intelligence and enjoys every discussion, theory or even movie related to this idea.




Hello Tavish, My question is re "the Quick brown fox" example near the end of the article. Why isn't the word "Quick" included in the Suffle & Sort stage ? Thanks, Vikram Chinmulgund
Hi Vikram, "Quick" word is included in Shuffle & Sort stage. It is just that it goes to Reducer 2 in this case. Hope this clarifies your doubt. Tavish
Thanks, Tavish. Are you saying that a)since there is only one instance of "Quick" it doesn't need to be shuffled and b)hence "quick" can go to any available reducer depending on load distribution. regards
Vikram, The main objective of shuffling is to make sure all the occurrence of same map id are available on the same reducer. As "Quick:" has only one occurrence, it can go to either of the two reducers. But to your point, shuffler still needs to work "Quick". Notice that shuffler cannot directly swap "the" and "quick" from the first mapper. If that happens, all "the" from other mappers also need to be shifted to Reducer 2. Hope this clarifies your doubt. Tavish
Hi Tavish, I have a question on number of reducers. As I have understood from browsing on internet about map and reduce, is that after mapper has finish its job, output of mapper(combiner optional) will go to reducer such that each key will go to different reducer. so, reducer will have just one key and its related result, for eg. Mapper 1 output : (abc,1 ) (def,1) Mapper 2 output : (abc,1 ) So input to reducer will be Reducer 1: (abc,1) (abc,1) & Reducer 2 :( def, 1) so final ouput : (abc,2) (def,1) Is this correct ? or Am I missing something ? Reference : https://www.google.com/search?q=key+value+word+count+reducer&tbm=isch&ei=5__NU67eC6TziQLLtoDQAQ#facrc=_&imgdii=_&imgrc=RDl_OVp1pIjE_M%253A%3BKAo2vtr32xkeWM%3Bhttp%253A%252F%252Fwww.cs.uml.edu%252F~jlu1%252Fdoc%252Fsource%252Freport%252Fimg%252FMapReduceExample.png%3Bhttp%253A%252F%252Fwww.cs.uml.edu%252F~jlu1%252Fdoc%252Fsource%252Freport%252FMapReduce.html%3B1344%3B624
Sankhe, The number of mappers and reducers can be independently chosen. And you are right, the work of reducer starts after all mappers have done the job.