This article was published as a part of the Data Science Blogathon.
Introduction
MapReduce is part of the Apache Hadoop ecosystem, a framework that develops large-scale data processing. Other components of Apache Hadoop include Hadoop Distributed File System (HDFS), Yarn, and Apache Pig. This component develops large-scale data processing using scattered and compatible algorithms in the Hadoop ecosystem. This editing model is used in social media and e-commerce to analyze extensive data collected from online users. This article provides insight into MapReduce on Hadoop. It will allow readers to discover details about how much data is simplified and how it is applied to real-life programs.
.jpg)
MapReduce is a Hadoop framework used to write applications that can process large amounts of data in large volumes. It can also be called an editing model where we can process large databases in all computer collections. This application allows data to be stored in distributed form, simplifying a large amount of data and a large computer. There are two main functions in MapReduce: map and trim. We did the previous work before saving. In the map function, we split the input data into pieces, and the map function processes these pieces accordingly.
A map that uses output as input for reduction functions. The scanners process medium data from maps to smaller tuples, which reduces tasks, leading to the final output of the frame. This framework improves planning and monitoring activities, and failed jobs are restructured by frame. Programmers can easily use this framework with little experience in distributed processing. MapReduce can use various programming languages such as Java, Live, Pig, Scala, and Python.
How does MapReduce work in Hadoop?
An overview of the categories of MapReduce Architecture and MapReduce will help us understand how it works in Hadoop.
MapReduce architecture
The following diagram shows the MapReduce structure.
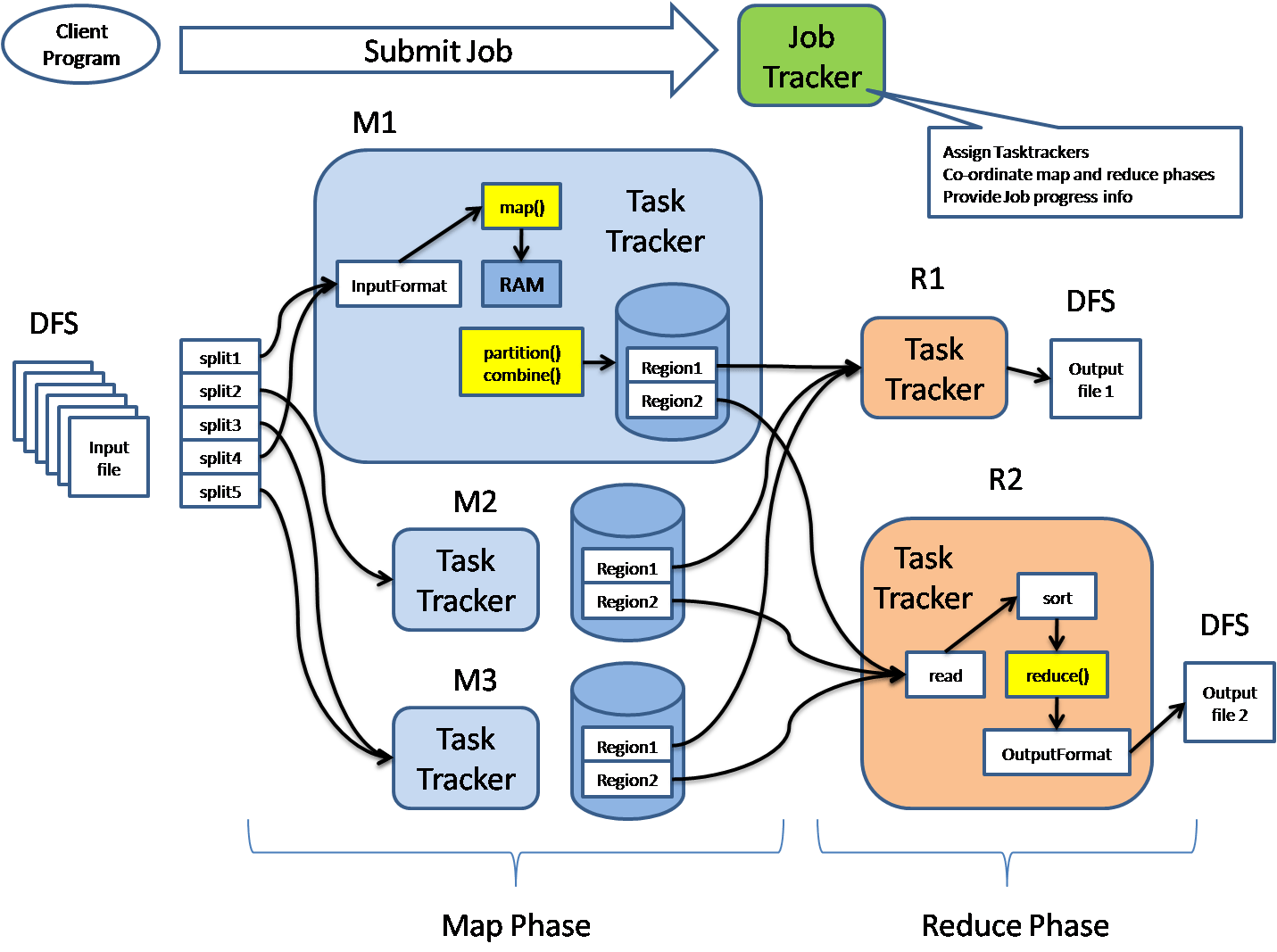
Image source – section.io
MapReduce architecture consists of various components. A brief description of these sections can enhance our understanding of how it works.
- Job: This is real work that needs to be done or processed
- Task: This is a piece of real work that needs to be done or processed. The MapReduce task covers many small tasks that need to be done.
- Job Tracker: This tracker plays a role in organizing tasks and tracking all tasks assigned to a task tracker.
- Task Tracker: This tracker plays the role of tracking activity and reporting activity status to the task tracker.
- Input data: This is used for processing in the mapping phase.
- Exit data: This is the result of mapping and mitigation.
- Client: This is a program or Application Programming Interface (API) that sends tasks to MapReduce. It can accept services from multiple clients.
- Hadoop MapReduce Master: This plays the role of dividing tasks into sections.
- Job Parts: These are small tasks that result in the division of the primary function.
In MapReduce architecture, clients submit tasks to MapReduce Master. This manager will then divide the work into smaller equal parts. The components of the function will be used for two main tasks in Map Reduce: mapping and subtraction.
The developer will write a concept that satisfies the organization’s or company’s needs. Input data will be categorized and mapped.
The central data will then be filtered and merged. The slider that will produce the last one stored on HDFS will process the output.
The following diagram shows a simplified flow diagram of the MapReduce program.

Image Source – section.io
How do Job Trackers work?
Every task consists of two essential parts: mapping and reduction functions. Map work plays the role of splitting duties into task segments and central mapping data, and the reduction function plays the role of shuffling and reducing the central data into smaller units.
The activity tracker works like a master. It ensures that we do all the work. The activity tracker lists tasks posted by clients, and it will provide job trackers for jobs. Each task tracker has a map function and minimizes tasks. Activity trackers report the status of each task assigned to the task tracker. The following diagram summarizes how task trackers and task trackers work.
Image source – section.io
Phases of MapReduce
The MapReduce program comprises three main stages: mapping, navigation, and mitigation. There is also an optional category known as the merging phase.
Mapping Phase
This is the first phase of the program. There are two steps in this phase: classification and mapping. The database is divided into equal units called units (input divisions) in the division step. Hadoop contains a RecordReader that uses TextInputFormat to convert input variables into keyword pairs.
Key-value pairs are then used as input on the map step. This is the only data format a map editor can read or understand. The map step contains the logic of the code used in these data blocks. In this step, the map analyzes key pairs and generates an output of the same form (key-value pairs).
Shuffling phase
This is the second phase that occurs after the completion of the Mapping phase. It consists of two main steps: filtering and merging. In the filter step, keywords are filtered using keys and combining ensures that key-value pairs are included.
The shoplifting phase facilitates the removal of duplicate values and the collection of values. Different values with the same keys are combined. The output of this category will be keys and values, as in the Map section.
Reducer phase
In the reduction phase, the output of the push phase is user input. The subtractor continuously processes these inputs to reduce the median values into smaller ones. Provides a summary of the entire database. Output in this category is stored in HDFS.
The following diagram illustrates MapReduce with three main categories. Separation is usually included in the mapping phase.
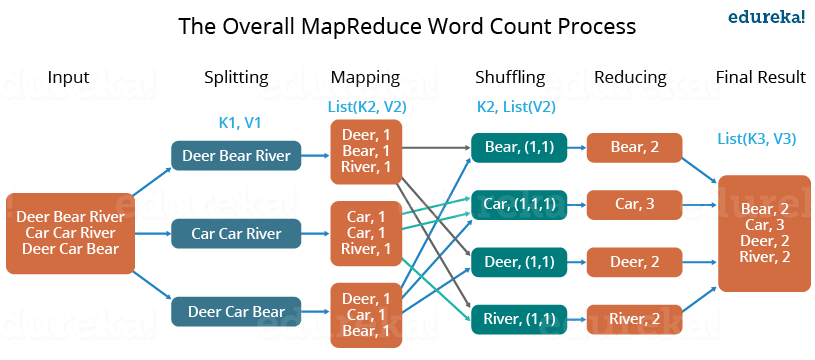
Image source – section.io
Combiner phase
This is the optional phase used to improve the MapReduce process. It is used to reduce pap output at the node level. At this stage, duplicate output from the map output can be merged into a single output. The integration phase accelerates the integration phase by improving the performance of tasks.
The following diagram shows how all four categories of MapReduce are used.
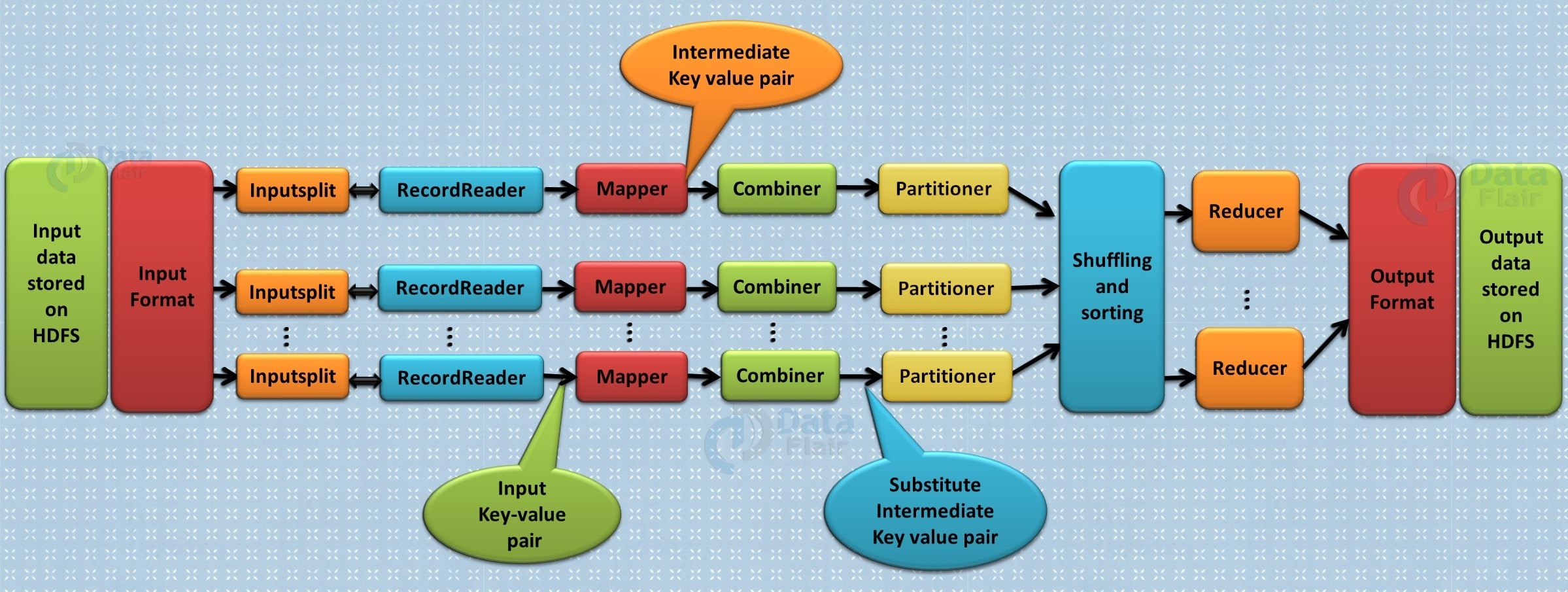
Image source – section.io
Benefits of Hadoop MapReduce
There are numerous benefits of MapReduce; some of them are listed below.
- Speed: It can process large amounts of random data in a short period.
- Fault tolerance: The MapReduce framework can manage failures.
- Most expensive: Hadoop has a rating feature that allows users to process or store data cost-effectively.
- Scalability: Hadoop provides an excellent framework. MapReduce allows users to run applications on multiple nodes.
- Data availability: Data matches are sent to various locations within the network. This ensures that copies of the data are available in case of failure.
- Parallel Processing: On MapReduce, many parts of the same database functions can be processed similarly. This reduces the time taken to complete the task.
Applications of Hadoop MapReduce
The following are some of the most valuable features of the MapReduce program.
E-commerce
E-commerce companies like Walmart, eBay, and Amazon use MapReduce to analyze consumer behavior. MapReduce provides sound information that is used as a basis for developing product recommendations. Other information includes site records, e-commerce catalog, purchase history, and contact logs.
Social media
The MapReduce editing tool can check certain information on social media platforms such as Facebook, Twitter, and LinkedIn. It can check necessary information, such as who liked your status and viewed your profile.
Entertainment
Netflix uses MapReduce to analyze clicks and logs for online clients. This information helps the company promote movies based on customer interests and behavior.
Conclusion
MapReduce is an integral part of the Hadoop framework. It is a fast, scalable, and inexpensive system that can help data analysts and developers process big data. Now, you have a detailed knowledge of MapReduce, its components, and its benefits. This article covers all the aspects needed to get started with Apache MapReduce. This editing model is ideal for analyzing usage patterns on e-commerce websites and forums. Companies that provide online services can use this framework to improve their marketing strategies.
Now you have detailed information about MapReduce Architecture & Its works in Hadoop for faster Parallel processing. We have seen Different components of MapReduce: Job, Task, Job Tracker, Client, Exit Node, and Input Node. We have discussed the Benefits of MapReduce some most Useful are Fault Tolerance, Speed & Scalability. After that, the Application part involves E-Commerce, Social Media & Entertainment. This is all you need to get started with MapReduce.
The media shown in this article is not owned by Analytics Vidhya and is used at the Author’s discretion.
Data Analyst who love to drive insights by visualizing the data and extracting the knowledge from it. Automating various tasks using python & builds Real time Dashboard's using tech like React and node.js. Capable of Creaking complex SQL queries to fetch the accurate data.






