
Synthetic Key
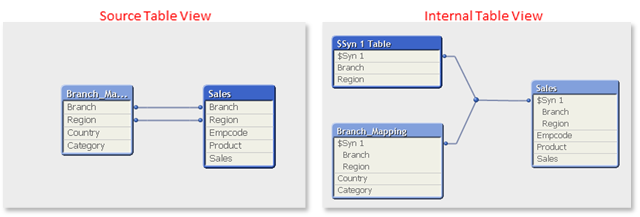
Before I discuss about Synthetic Keys, let’s look at a typical QV data model (in the diagram on right hand). Here, we can see three tables “Sales”, “Branch Mapping” and “$Syn 1″. But, I had loaded only two tables (Sales and Branch Mapping) in QlikView. Another surprise pops up, when I look closely at “Sales” and “Branch Mapping” tables. There is an additional variable “$Syn 1” in both the tables.
When I encountered this effect in the data model for the first time, I was not able to identify why this was happening? To some extent, I was not bothered about this because the output of the dashboard was working fine. But, when my mentor looked at this model, I came to know that “$Syn 1” is a synthetic key and “$Syn 1 Table” is a synthetic table.
What are Synthetic Keys or Tables?
When we load two tables with a common field name in both tables, the tables get associated automatically based on the common fields. This is the associative functionality of QlikView.
However, when we have more than one common field between two or more tables, QlikView creates “SYNTHETIC KEYS” and “SYNTHETIC TABLE”. QlikView adds synthetic table (as $Syn table) and synthetic key (as $Syn symbol) to the data model. The keys are added to the user uploaded tables and are used to join with synthetic table.
Synthetic key is QlikView’s method to deal with composite keys. The Synthetic table contains a synthetic key that is a composite of all the combinations of the multiple key fields connecting the tables. In our data model, we had two fields common “Branch” and “Region” so QlikView created synthetic key and synthetic table on its own. If we look at the source table view of table viewer, it shows that two fields are connected between these two tables.
Are Synthetic keys good or bad?
As per QlikView reference manual:
When the number of composite / Synthetic keys increases, depending on data amounts, table structure and other factors, QlikView may or may not handle them gracefully. QlikView may end up using excessive amount of time and/or memory. Unfortunately the actual limitations are virtually impossible to predict, which leaves only trial and error as a practical method to determine them.
- This is one of the reasons many people remove synthetic keys. But, this statement is applicable when you have multiple synthetic keys in your data model. However, if your data model has multiple synthetic keys, it is likely that there is a serious issue with your data model and not with synthetic keys.
- When you have two or more tables and they have multiple common fields, then synthetic keys create a correct, compact and efficient solution. Synthetic keys are not the reason for performance and memory problems. They usually work slightly better or similar, when compared to manual composite keys, which are usually used to remove synthetic keys.
- One of the instances, I remembered that one of my colleague said that due to synthetic key, the output of the data model is not showing correctly or there is performance issue but when he has removed the synthetic keys, it is working fine. Here actual problem was not synthetic keys, it was a poor data model and while removing synthetic keys it has improved. Currently I don’t have performance and memory comparison detail for with or without synthetic keys (if you have please share).
Why should we remove Synthetic keys?
As discussed above, Synthetic keys may get created due to poor data modeling. Whenever an unexpected synthetic key is created, we should look at data model again, make necessary changes and as a result we end up with a good data model. Please note that the important keyword in last statement is UNEXPECTED. Otherwise, synthetic keys don’t do any harm.
Second reason, which I realized over time is whenever I create my own composite keys instead of synthetic keys, I have far higher clarity about the data model.
Othewise, I can say that synthetic keys are good and provide ease to handle composite keys if you are working on a good data model.
How to remove Synthetic keys?
To remove synthetic keys, we first look at our data model and make necessary changes, if required. We have multiple methods to remove synthetic keys but it depends upon the requirement
- Removing fields: When common fields causing synthetic keys are not required in data model and doing so will not affect the relationship between two tables. Removing fields can be done by commenting or removing field from load script.

- Renaming fields (Using QUALIFY): When common fields causing synthetic keys are not same field (not containing similar values), These are actually different fields with same name. Renaming can be done by using “AS” clause. We can also achieve this by using QUALIFY statement. With qualified statement, fields names are converted in the “TableName.FieldName” format
 Using QUALIFY
Using QUALIFY
- Autonumber/ Composite Keys: When we know common fields causing synthetic keys are important for data model then we can create our own key to handle composite keys. We can also use Autonumber / Autonumberhash128 / Autonumberhash256 functions to create composite keys. These will create a unique bit value for each distinct combination of the concatenated columns. Autonumberhash128 and Autonumberhash256 creates 128bit and 256bit values respectively. Please note Autonumber may be problematic in applications generating the QVD files for use in other QlikView applications.

- We also have other methods to remove synthetic keys like “Creating a link table“, “Creating Explicit Joins ” and “Concatenating similar tables“. These topics must be discussed in detail and will explore it in future.
End Note:
In general, developers want to remove synthetic keys because it is believed that they lead to negative impact on performance and memory utilization. However, this is not true. They handle composite keys in a more efficient way compared to manual keys, if we have a good data model. If you have experienced the difference in performance and memory utilization with or without synthetics, please share your thoughts through the comments below as it will benefit the community.
If you like what you just read & want to continue your analytics learning, subscribe to our emails, follow us on twitter or like our facebook page.
Sunil Ray is Chief Content Officer at Analytics Vidhya, India's largest Analytics community. I am deeply passionate about understanding and explaining concepts from first principles. In my current role, I am responsible for creating top notch content for Analytics Vidhya including its courses, conferences, blogs and Competitions.
I thrive in fast paced environment and love building and scaling products which unleash huge value for customers using data and technology. Over the last 6 years, I have built the content team and created multiple data products at Analytics Vidhya.
Prior to Analytics Vidhya, I have 7+ years of experience working with several insurance companies like Max Life, Max Bupa, Birla Sun Life & Aviva Life Insurance in different data roles.
Industry exposure: Insurance, and EdTech
Major capabilities: Content Development, Product Management, Analytics, Growth Strategy.







Dear Sunil, I am qlikview enthusiast & looking forward to know the basic concept of qlikview visualization before going ahead in learning this in detail- Can the qlikview dashboard recipient be able to view and leverage the functionality of qlikview if the same(qlikview) is not installed in his machine? Can we host the dashboard over web such that the functionality can be leverage by the end user? Do let me know your comments on this.. thanks,
Its help ful, Thanks for sharing
Thank you dude. Greetings from Bolivia