Introduction
We all know about Artificial Intelligence, don’t we? It is revolutionizing the technological landscape worldwide and is expected to grow enormously within the next decade. As AI marks its presence in industries worldwide, it goes without saying that we are looking at a world where life without AI will seem impossible. AI is making machines increasingly intelligent every day, driving innovations that revolutionize how people work. However, there might be a question in your mind that goes something like this: What is helping AI do all this and get accurate results? The answer is very simple, and that is data.

Data is the foundational fuel for AI. The quality and quantity of the data, along with the diversity of the data, directly influence how AI systems can function. This data-driven learning enables AI to uncover essential patterns, making decisions with minimal human intervention. However, acquiring large volumes of good-quality real data is often restricted due to costs and privacy concerns, amongst an endless list of others. This is where synthetic data, and its importance, comes into play.
Learning Objectives
- Understand the importance of synthetic data
- Learn about the role of Generative AI in data creation
- Explore practical applications and their implementation in your projects
- Know about the ethical implications related to the usage and importance of synthetic data in AI systems
Table of contents
This article was published as a part of the Data Science Blogathon.
The Significance of High-Quality Synthetic Data
Synthetic data is nothing but artificially generated data. Specifically, it mimics real-world data’s statistical properties without having identifiers distinguishing it from real data.
Pretty cool, right?
Synthetic data isn’t merely a workaround for privacy concerns. Rather, it is a cornerstone for responsible AI. This form of data generation addresses several challenges associated with using real data. It is helpful when the data available is less or biased towards a particular class. Furthermore, it can also be used in applications where privacy is important. This is because real data is generally confidential and might not be available for use. Hence, adding helps solve these issues and improve the model’s accuracy.
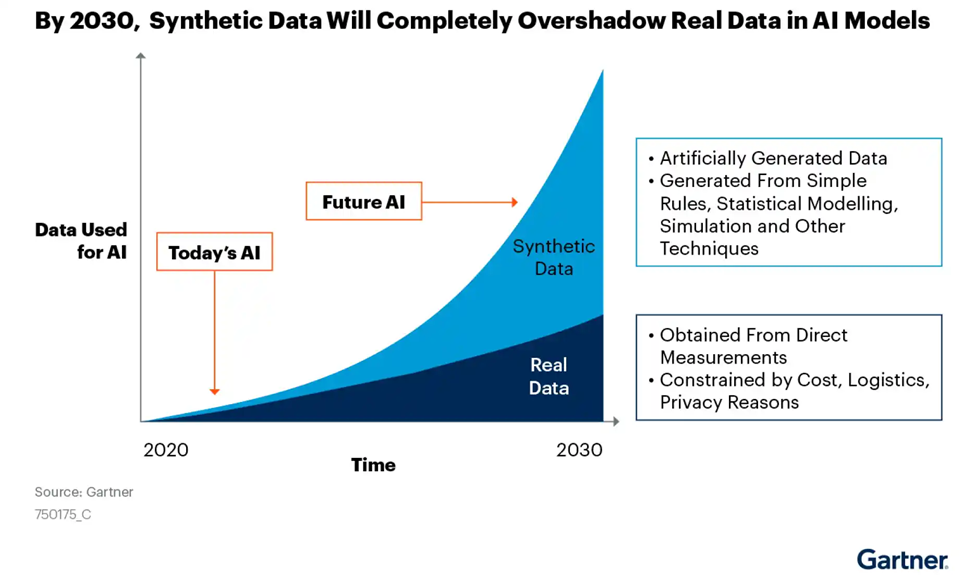
According to an estimation made in a Gartner report, synthetic data is expected to win the race against real data regarding usage in AI models by 2030. This showcases its power and role in improving AI systems.
Role of Generative AI in Synthetic Data Creation
Generative AI models lie at the heart of synthetic data creation. What these essentially do is simple – they learn the underlying patterns within original datasets and then try to replicate them. By employing algorithms like Generative Adversarial Networks (GANs) or Variational Autoencoders, Generative AI can produce highly accurate and diverse datasets required for training many AI systems.
In the landscape of synthetic data generation, several innovative tools stand out, each designed to cater to specific needs in data science. YData’s ydata-synthetic is a comprehensive toolkit that utilizes advanced Generative AI models to create high-quality synthetic datasets, also offering data profiling features to help understand the structure of this data.
Another notable framework is DoppelGANger, which uses generative adversarial networks (GANs) to efficiently generate synthetic time series and attribute data. Additionally, Twinify offers a unique approach to creating privacy-preserving synthetic twins of sensitive datasets, making it a valuable tool for maintaining data privacy. These tools provide versatile options for data scientists looking to enhance dataset privacy, expand data volumes, or improve model accuracy without compromising sensitive information.
Creating High-Quality Synthetic Data
Creating good quality synthetic data involves several key steps that help ensure that the generated data is realistic and also preserves the statistical properties of the original data.
The process begins with defining clear objectives for this data, such as data privacy, augmenting real datasets or testing machine learning models. Next, it’s important to collect and analyze real-world data to understand its underlying patterns, distributions, and correlations.
To illustrate, consider the following example datasets:
- UCI Machine Learning Repository: A diverse collection of datasets suitable for understanding data distributions and generating synthetic counterparts. UCI Machine Learning Repository
- Kaggle Datasets: Offers a wide range of datasets across various domains, useful for analyzing and synthesizing data. Kaggle Datasets
- Synthetic Data Vault (SDV): Provides tools and datasets for generating synthetic data based on real-world data using statistical models. SDV Documentation
These datasets can be analyzed to identify key statistical properties. Which can then be used to generate synthetic data using tools like YData Synthetic, Twinify and DoppelGANger. The generated synthetic data can be validated against the original data through statistical tests and visualizations to ensure it retains the necessary properties and correlations. Therefore, making it suitable for various applications such as machine learning model training and testing, privacy-preserving data analysis, and more.
Potential Application Scenarios
Let us now explore potential application scenarions.
Data Augmentation
This is the top scenario where synthetic data is used—when scarce or imbalanced data is present. Synthetic data augments existing datasets, thus ensuring that AI models are trained on larger data sets. This application is critical in fields like healthcare, where diverse data sets can lead to more robust diagnostic tools.
Below is a code snippet that augments the Iris dataset with synthetic data generated using YData’s synthesizer, ensuring more balanced data for training AI models. This is achieved using a synthesizer which is fitted on the real data (the Iris dataset) and learns the underlying patterns and distributions of the data. Using the fitted synthesizer, synthetic data is generated which is then concatenated with the real data, thus augmenting the dataset.
import pandas as pd
from ydata_synthetic.synthesizers.regular import RegularSynthesizer
url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv"
real_data = pd.read_csv(url)
synthesizer = RegularSynthesizer()
synthesizer.fit(real_data)
synthetic_data = synthesizer.sample(n_samples=100)
augmented_data = pd.concat([real_data, synthetic_data])
print(augmented_data.head())Output:
sepal_length sepal_width petal_length petal_width species
0 5.1 3.5 1.4 0.2 setosa
1 4.9 3.0 1.4 0.2 setosa
2 4.7 3.2 1.3 0.2 setosa
3 4.6 3.1 1.5 0.2 setosa
4 5.0 3.6 1.4 0.2 setosaBias Mitigation
Sometimes, the available data is biased towards a particular class; it has more samples of class A than class B. Hence, the model might predict class A way more than class B. To counter this, we can intentionally alter the existing data distribution, thus promoting equity in the outputs given by AI. This is especially important in sectors like lending and hiring, where biased algorithms can significantly affect people’s lives.
The code below generates synthetic data if you have an underrepresented class in your dataset (in this case, the Versicolor class in the iris dataset) to balance the class distribution. The original dataset has a bias where the Versicolor class is underrepresented compared to the other classes (Setosa and Virginica). Using the RegularSynthesizer from the YData Synthetic library, synthetic data is generated specifically for the Versicolor class which is then added to the original biased dataset. Thus increasing the number of instances in the Versicolor class and creating a more balanced distribution.
import pandas as pd
from ydata_synthetic.synthesizers.regular import RegularSynthesizer
url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv"
biased_data = pd.read_csv(url)
biased_data = biased_data[biased_data['species'] != 'versicolor']
synthesizer = RegularSynthesizer()
synthesizer.fit(biased_data)
# Generating synthetic data for the minority class (versicolor)
synthetic_minority_data = synthesizer.sample(n_samples=50)
synthetic_minority_data['species'] = 'versicolor'
balanced_data = pd.concat([biased_data, synthetic_minority_data])
print("Biased Data Class Distribution:")
print(biased_data['species'].value_counts())
print("\nBalanced Data Class Distribution:")
print(balanced_data['species'].value_counts())Output:
Biased Data Class Distribution:
setosa 50
virginica 50
versicolor 0
Name: species, dtype: int64
Balanced Data Class Distribution:
setosa 50
virginica 50
versicolor 50
Name: species, dtype: int64Privacy-Preserving Data Sharing
It enables the sharing of realistic (not real, but almost!) datasets across organizations without the risk of exposing sensitive information that might create confidentiality issues. This is crucial for industries such as finance and telecommunications, where data sharing is necessary for innovation, but privacy and confidentiality must be maintained.
This code creates synthetic twins of sensitive datasets using Twinify, which allows data sharing without compromising privacy.
import pandas as pd
from twinify import Twinify
url = "https://raw.githubusercontent.com/mwaskom/seaborn-data/master/iris.csv"
sensitive_data = pd.read_csv(url)
twinify_model = Twinify()
twinify_model.fit(sensitive_data)
synthetic_twins = twinify_model.sample(n_samples=len(sensitive_data))
print(synthetic_twins.head())Output:
sepal_length sepal_width petal_length petal_width species
0 5.122549 3.527435 1.464094 0.251932 setosa
1 4.846851 3.091847 1.403198 0.219201 setosa
2 4.675999 3.250960 1.324110 0.194545 setosa
3 4.675083 3.132406 1.535735 0.201018 setosa
4 5.014248 3.591084 1.461466 0.253920 setosaRisk Assessment and Testing
Risk assessment and testing are critical applications of synthetic data, enabling organizations to evaluate and enhance their systems’ robustness under hypothetical scenarios not represented in real data. In cybersecurity, synthetic data allows for the simulation of sophisticated attack scenarios, such as zero-day exploits and advanced persistent threats, helping identify vulnerabilities and strengthen defenses. Similarly, in financial services, synthetic data facilitates stress testing and scenario analysis by modeling extreme market conditions. This enables institutions to assess the resilience of their portfolios and improve risk management strategies.
Beyond these fields, synthetic data is also valuable in healthcare for testing predictive models under rare clinical scenarios, in manufacturing for simulating equipment failures and supply chain disruptions, and in insurance for modeling the impact of natural disasters and major accidents. Organizations can enhance their system’s resilience by preparing for rare but catastrophic events through synthetic data simulation. This ensures that they have the necessary equipment to handle unexpected situations and thus effectively mitigate potential risks.
Conclusion
As AI reshapes our world, data is crucial in addressing privacy, cost, and accessibility issues, ensuring ethical and effective models. Generative AI techniques enable the creation of high-quality datasets that mirror real-world complexities, enhancing model accuracy and reliability. These datasets foster responsible AI development by mitigating biases, facilitating privacy-preserving data sharing, and enabling comprehensive risk assessments. Leveraging tools like ydata-synthetic and DoppelGANger will be essential in realizing AI’s full potential and driving innovation. These tools uphold ethical standards while enabling advancements in AI development. In this article we explored the importance of synthetic data.
Key Takeaways
- Importance of Synthetic Data is that it offers a solution for utilizing realistic yet completely private datasets, adhering to stringent data protection laws. Also ensuring that sensitive information is never at risk.
- By generating synthetic data that reflects the variability and complexity of real data, organizations can improve the accuracy Also reliability of their AI models without the constraints of data scarcity.
- Synthetic data reduces the need for expensive data collection processes and the storage of vast amounts of real data. It makes for a cost-effective alternative for training and testing AI models.
- It offers a proactive approach to creating balanced datasets that prevent the perpetuation of biases, promoting more fair and equitable AI applications.
Each of these points underscores the transformative potential of synthetic data in paving the way for responsible, efficient, and ethical AI development. As we advance, the role of tools like ydata-synthetic or DoppelGANger will be pivotal in shaping this future, ensuring that AI continues to evolve as a tool for good, guided by the principles of responsible AI.
Frequently Asked Questions
Q1. What is the importance of synthetic data?
A. Synthetic data is artificially generated data that mimics the statistical properties of real-world data without containing any identifiable information.
Q2. Why is synthetic data important for AI?
A. Synthetic data addresses issues of data privacy, cost, and accessibility, enabling AI models to train on large and diverse datasets while mitigating privacy concerns.
Q3. How does generative AI create synthetic data?
A. Generative AI models, such as GANs (Generative Adversarial Networks) and Variational Autoencoders, learn patterns from real data and replicate these patterns to generate this kind of data.
Q4. What are the practical applications of synthetic data?
A. Synthetic data can enhance the quality and fairness of AI models by augmenting data, mitigating bias, and preserving privacy in data sharing.
The media shown in this article are not owned by Analytics Vidhya and is used at the Author’s discretion.
Hey! I'm a fourth-year computer science undergrad with a passion for all things tech. Whether it's coding, exploring new technologies, or solving complex problems, I love every aspect of it. I also enjoy writing and sharing insights with others, which helps me connect with the tech community and stay updated. I'm always eager to learn and embrace every new opportunity that comes my way!



