Lots of analysts misinterpret the term ‘boosting’ used in data science. Let me provide an interesting explanation of this term. Boosting grants power to machine learning models to improve their prediction accuracy. Boosting algorithms are one of the most widely used algorithms in data science competitions. The winners of our last hackathons agree that they try boosting algorithms to improve the accuracy of their models.
In this article, I will explain how boosting algorithms in machine learning work very simply. I’ve also shared the Python codes below. I’ve skipped the intimidating mathematical derivations used in Boosting because that wouldn’t have allowed me to explain this concept in simple terms. Also, we have talked about how it works and why boosting algorithms in machine learning are important.
Let’s get started.

The term ‘Boosting’ refers to a family of algorithms which converts weak learner to strong learners.
Let’s understand this definition in detail by solving a problem of spam email identification:
How would you classify an email as SPAM or not? Like everyone else, our initial approach would be to identify ‘spam’ and ‘not spam’ emails using following criteria. If:
Above, we’ve defined multiple rules to classify an email into ‘spam’ or ‘not spam’. But, do you think these rules individually are strong enough to classify an email successfully? No.
Individually, these rules are not powerful enough to classify an email into ‘spam’ or ‘not spam’. Therefore, these rules are called as weak learner.
To convert weak learner to strong learner, we’ll combine the prediction of each weak learner using methods like:
• Using average/ weighted average
• Considering prediction has higher vote
For example: Above, we have defined 5 weak learners. Out of these 5, 3 are voted as ‘SPAM’ and 2 are voted as ‘Not a SPAM’. In this case, by default, we’ll consider an email as SPAM because we have higher(3) vote for ‘SPAM’.
Now we know that, boosting combines weak learner a.k.a. base learner to form a strong rule. An immediate question which should pop in your mind is, ‘How boosting identify weak rules?‘
To find weak rule, we apply base learning or ML algorithms with a different distribution. Each time base learning algorithm is applied, it generates a new weak prediction rule. This is an iterative process. After many iterations, the boosting algorithm in machine learning combines these weak rules into a single strong prediction rule.
Here’s another question which might haunt you, ‘How do we choose different distribution for each round?’
For choosing the right distribution, here are the following steps:
Step 1: The base learner takes all the distributions and assign equal weight or attention to each observation.
Step 2: If there is any prediction error caused by first base learning algorithm, then we pay higher attention to observations having prediction error. Then, we apply the next base learning algorithm.
Step 3: Iterate Step 2 till the limit of base learning algorithm is reached or higher accuracy is achieved.
Finally, it combines the outputs from weak learner and creates a strong learner which eventually improves the prediction power of the model. Boosting pays higher focus on examples which are mis-classified or have higher errors by preceding weak rules.
Underlying engine used for boosting algorithms can be anything. It can be a decision stamp, margin-maximizing classification algorithm, etc. Many boosting algorithms in machine learning use other types of engines such as:
In this article, we will focus on AdaBoost and Gradient Boosting followed by their respective python codes and will focus on XGboost in upcoming article.
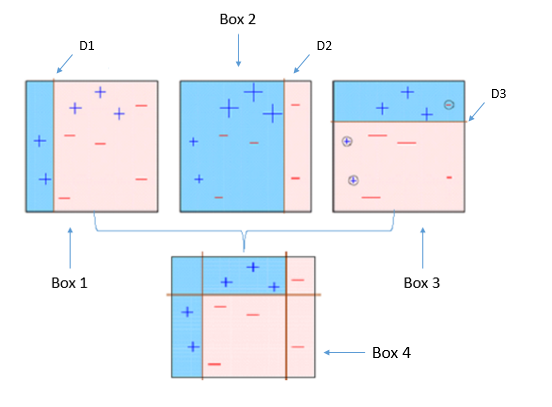
This diagram aptly explains Ada-boost. Let’s understand it closely:
Box 1: You can see that we have assigned equal weights to each data point and applied a decision stump to classify them as + (plus) or – (minus). The decision stump (D1) has generated vertical line at left side to classify the data points. We see that, this vertical line has incorrectly predicted three + (plus) as – (minus). In such case, we’ll assign higher weights to these three + (plus) and apply another decision stump.
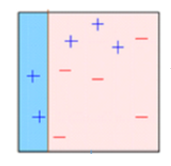
Box 2: Here, you can see that the size of three incorrectly predicted + (plus) is bigger as compared to rest of the data points. In this case, the second decision stump (D2) will try to predict them correctly. Now, a vertical line (D2) at right side of this box has classified three mis-classified + (plus) correctly. But again, it has caused mis-classification errors. This time with three -(minus). Again, we will assign higher weight to three – (minus) and apply another decision stump.
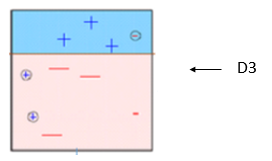
Box 3: Here, three – (minus) are given higher weights. A decision stump (D3) is applied to predict these mis-classified observation correctly. This time a horizontal line is generated to classify + (plus) and – (minus) based on higher weight of mis-classified observation.
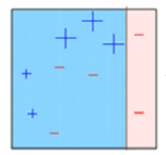
Box 4: Here, we have combined D1, D2 and D3 to form a strong prediction having complex rule as compared to individual weak learner. You can see that this algorithm has classified these observation quite well as compared to any of individual weak learner.
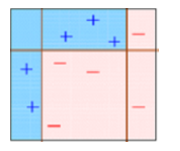
AdaBoost works using a method similar to the one discussed above. It fits a sequence of weak learners on different weighted training data. It starts by predicting the original data set and assigning equal weight to each observation. If the prediction using the first learner is incorrect, then it assigns higher weight to the observation that was predicted incorrectly. Being an iterative process, it continues to add learner(s) until a limit is reached in the number of models or accuracy.
Mostly, we use decision stamps with AdaBoost. But, we can use any machine learning algorithms as base learner if it accepts weight on training data set. We can use AdaBoost algorithms for both classification and regression problem.
Here is a live coding window to get you started. You can run the codes and get the output in this window itself:
Furthermore, you can tune the parameters to optimize the performance of algorithms, I’ve mentioned below the key parameters for tuning:
You can also tune the parameters of base learners to optimize its performance.
In gradient boosting, it trains many model sequentially. Each new model gradually minimizes the loss function (y = ax + b + e, e needs special attention as it is an error term) of the whole system using Gradient Descent method. The learning procedure consecutively fit new models to provide a more accurate estimate of the response variable.
The principle idea behind this algorithm is to construct new base learners that can be maximally correlated with the negative gradient of the loss function and associated with the whole ensemble.
In Python Sklearn library, we use Gradient Tree Boosting or GBRT. It is a generalization of boosting to arbitrary differentiable loss functions. It can be used for both regression and classification problems.
from sklearn.ensemble import GradientBoostingClassifier #For Classification from sklearn.ensemble import GradientBoostingRegressor #For Regression
clf = GradientBoostingClassifier(n_estimators=100, learning_rate=1.0, max_depth=1)
clf.fit(X_train, y_train)You can tune loss function for better performance.
Several advantages that make boosting algorithm a powerful tool in machine learning:
Boosting is a technique in machine learning that improves the performance of models by combining multiple weak learners into a single strong learner. Here’s a breakdown of how it works:
The Idea Behind Boosting: Imagine many average students (weak learners) working on the same problem. Each student might only get a few answers right. But if you combine all their answers smartly, you can end up with a much better understanding of the problem (strong learner). This is the core idea behind boosting algorithms in machine learning.
In this article, we looked at boosting, one of the methods of ensemble modeling, to enhance prediction power. We discussed the science behind the boosting algorithm in machine learning and its two types: AdaBoost and Gradient Boost. We also studied their respective Python codes.
Boost your machine learning expertise with our ‘Boosting Algorithms‘ course! Discover how boosting enhances prediction accuracy, explore AdaBoost and Gradient Boost, and implement them in Python—enroll now to elevate your skills and tackle complex challenges with confidence!
A. A boosting algorithm is an ensemble technique that combines multiple weak learners to create a strong learner. It focuses on correcting errors made by the previous models, enhancing overall prediction accuracy by iteratively improving upon mistakes.
A. AdaBoost, or Adaptive Boosting, is a boosting algorithm that adjusts the weights of incorrectly classified instances to focus more on them in subsequent iterations. It combines weak classifiers to form a strong classifier, improving accuracy by focusing on difficult cases.
A. Yes, XGBoost (Extreme Gradient Boosting) is a boosting algorithm. It is an advanced implementation of gradient boosting that is efficient, flexible, and capable of handling large datasets. XGBoost is known for its performance and scalability.
A. XGBoost is often considered the most popular boosting algorithm due to its efficiency, speed, and accuracy. It has become widely adopted in machine learning competitions and practical applications for its superior performance over other boosting methods.
Sunil Ray is Chief Content Officer at Analytics Vidhya, India's largest Analytics community. I am deeply passionate about understanding and explaining concepts from first principles. In my current role, I am responsible for creating top notch content for Analytics Vidhya including its courses, conferences, blogs and Competitions. I thrive in fast paced environment and love building and scaling products which unleash huge value for customers using data and technology. Over the last 6 years, I have built the content team and created multiple data products at Analytics Vidhya. Prior to Analytics Vidhya, I have 7+ years of experience working with several insurance companies like Max Life, Max Bupa, Birla Sun Life & Aviva Life Insurance in different data roles. Industry exposure: Insurance, and EdTech Major capabilities: Content Development, Product Management, Analytics, Growth Strategy.
Lorem ipsum dolor sit amet, consectetur adipiscing elit,








Thanks for clear and concise introduction to boosting. I've tested xgboost in R on small dataset (approx. 400 samples and 20 inputs) and was amazed at the prediction accuracy as well as speed.
One thing which confused me a lot is that as you mentioned what happens in adaptive boosting, isn't it similar to Random Forest Classifier because there also we take n_estimators (that are number of decision trees) and finally take out the average from that..
Please sir again describe the working of boosting algrothim and how it will work..? Please reply me on [email protected]. thank you sir
Thanks for simplified explanation can u please provide mathematical version of above
Thank you for your post. The ADABoost diagram was especially very helpful.