Prediction models are one of the most commonly used machine learning models. Gradient boosting Algorithm in machine learning is a method standing out for its prediction speed and accuracy, particularly with large and complex datasets. This algorithm has produced the best results from Kaggle competitions to machine learning solutions for business. It is a boosting method, and I have talked more about it in this article. It is refer it as Stochastic Gradient Boosting Machine or GBM Algorithm. In this article, I will discuss the math intuition behind the Gradient boosting algorithm.
This article was published as a part of the Data Science Blogathon
Table of Contents
- What is Boosting?
- What is Gradient Boosting?
- What is AdaBoost Algorithm?
- What is a Gradient Boosting Algorithm?
- Understanding Gradient Boosting Algorithm with An Example
- What is a Gradient Boosting Classifier?
- Implementation of GBM Using scikit-learn
- Parameter Tuning in Gradient Boosting (GBM) in Python
- Conclusion
- Frequently Asked Questions
What is Boosting?
While studying machine learning, you must have encountered this term called boosting. It is the most misinterpreted term in the field of Data Science. The principle behind boosting algorithms is that first, we build a model on the training dataset; then, a second model is built to rectify the errors present in the first model. Let me explain to you what exactly this means and how this works.
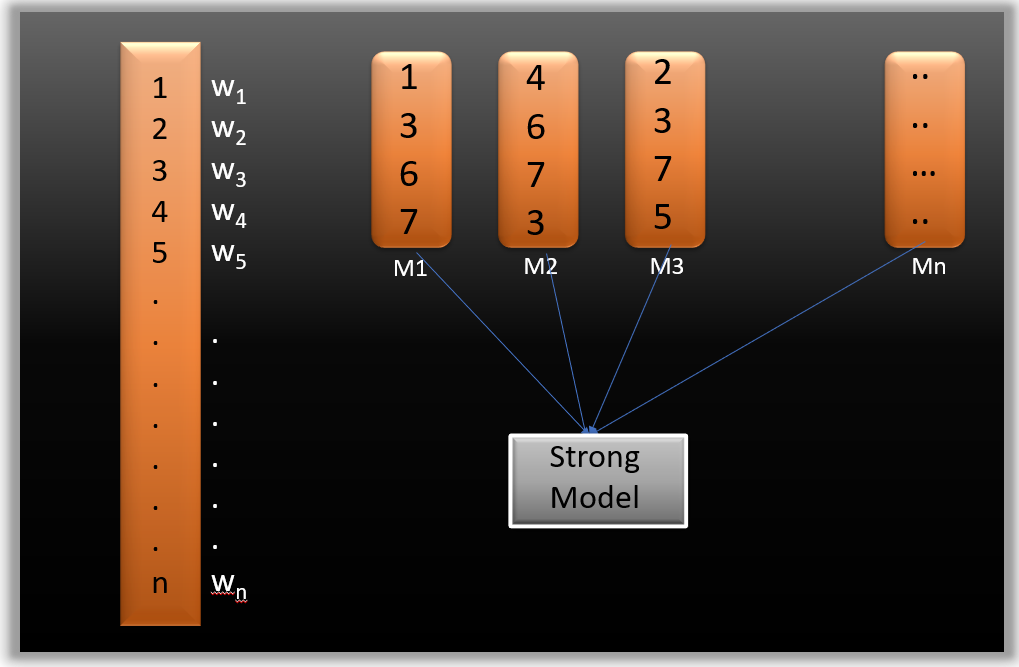
Suppose you have n data points and 2 output classes (0 and 1). You want to create a model to detect the class of the test data. Now we randomly select observations from the training dataset and feed them to model 1 (M1), assuming that initially, all observations carry equal weight, giving them an equal probability of selection.
Remember in ensembling techniques the weak learners combine to make a strong model so here M1, M2, M3….Mn, are all weak learners.
Since M1 is a weak learner, it will surely misclassify some observations. Now, before feeding the observations to M2, we update the weights of the wrongly classified observations. You can think of it as a bag that initially contains 10 different colour balls, but after some time, some kid takes out his favourite colour ball and puts 4 red colour balls instead inside the bag. Of course, the probability of selecting a red ball is higher.
Other Gradient Boosting Techniques
This same phenomenon occurs in gradient boosting techniques: when an observation gets wrongly classified, we update its weight, and for those that we classify correctly, we decrease their weights. The probability of selecting a wrongly classified observation increases. Hence, in the next model, only those observations that were misclassified in the model.
Similarly, it happens with M2. The wrongly classified weights and then feed them to M3. This procedure continues until we minimize the errors and predict the dataset correctly. Now, when the new datapoint comes in (Test data), it passes through all the models (weak learners), and the class that gets the highest vote is the output for our test data.
What is Gradient Boosting?
Gradient boosting is a machine learning ensemble technique that sequentially combines the predictions of multiple weak learners, typically decision trees. It aims to improve overall predictive performance by optimizing the model’s weights based on the errors of previous iterations, gradually reducing prediction errors and enhancing the model’s accuracy. This technique is most commonly used for linear regression.

Also Read: How Gradient Boosting Algorithm Works?
What is AdaBoost Algorithm?
Before getting into the details of the gradient boosting algorithm in machine learning, we must know about the AdaBoost Algorithm, a boosting method. This algorithm starts by building a decision stump and assigning equal weights to all the data points. Then, it increases the weights for all the misclassified points and lowers the weight for those easily or correctly classified. A new decision stump is made for these weighted data points. The idea behind this is to improve the predictions made by the first stump. I have talked more about this algorithm here.
The main difference between these two algorithms is that Stochastic Gradient Boosting has a fixed base estimator and decision trees. In contrast, in AdaBoost, we can change the base estimator to suit our needs.
What is a Gradient Boosting Algorithm?
Errors play a major role in any machine learning algorithm. There are two main types of errors: bias error and variance error. The gradient boost algorithm helps us minimize the model’s bias error. The main idea behind this algorithm is to build models sequentially, and these subsequent models try to reduce the errors of the previous model. But how do we do that? How do we reduce the error? Build a new model on the errors or residuals of the previous model.
When the target column is continuous, we use a Gradient Boosting Regressor; when it is a classification problem, we use a Gradient Boosting Classifier. The only difference between the two is the “Loss function”. The objective is to minimize this loss function by adding weak learners using gradient descent. Since it is based on the++ loss function, for regression problems, we’ll have different loss functions like Mean squared error (MSE), and for classification, we will have different functions, like log-likelihood.
Understanding Gradient Boosting Algorithm with An Example
Let’s understand the intuition behind the Stochastic Gradient Boosting algorithm in Machine Learning with an example. Our target column is continuous, so we will use a gradient boosting regressor.
The following is a sample from a random dataset in which we must predict the car price based on various features. The target column is price, and the other features are independent.

Step 1: Build a Base Model
The first step in gradient boosting is to build a base model to predict the observations in the training dataset. For simplicity, we take an average of the target column and assume that to be the predicted value as shown below:

Why did I say we take the average of the target column? Well, math is involved in this. Mathematically the first step can be written as:

Looking at this may give you a headache, but don’t worry – we will try to understand what it says here.
Here L is our loss function,
Gamma is our predicted value, and
arg min means we have to find a predicted value/gamma for which the loss function is minimum.
Since the target column is continuous our loss function will be:

Here yi is the observed value, and gamma is the predicted value.
Now, we need to find a minimum value of gamma such that this loss function is minimum. We all studied how to find minima and maxima in 12th grade. Did we use them to differentiate this loss function and then put it equal to 0, right? Yes, we will do the same here.

Let’s see how to do this with the help of our example. Remember that y_i is our observed value, and gamma_i is our predicted value. By plugging the values in the above formula,a we get:

We end up over an average of the observed car price, which is why I asked you to take the average of the target column and assume it as your first prediction.
Hence for gamma=14500, the loss function will be minimum so this value will become our prediction for the base model.
Step 2: Compute Pseudo Residuals
The next step is to calculate the pseudo residuals which are (observed value – predicted value).

Again the question comes why only observed – predicted? Everything is mathematically proven. Let’s see where this formula comes from. This step can be written as:

Here F(xi) is the previous model and m is the number of DT made.
We are just taking the derivative of the loss function w.r.t the predicted value and we have already calculated this derivative:

If you look at the formula of residuals above, you will notice that a negative sign multiplies the derivative of the loss function, so now we get:

The predicted value here is the prediction made by the previous model. In our example the prediction made by the previous model (initial base model prediction) is 14500, to calculate the residuals our formula becomes:

Step 3: Build a Model on Calculated Residuals
In the next step, we will build a model on these pseudo residuals and make predictions. Why do we do this? Because we want to minimize these residuals, minimizing them will eventually improve our model accuracy and prediction power. So, using the residual as a target and the original feature, the cylinder number, cylinder height, and engine location, we will generate new predictions. Note that the predictions, in this case, will be the error values, not the predicted car price values, since our target column is an error now.
Let’s say hm(x) is our DT made on these residuals.
Step 4: Compute Decision Tree Output
In this step, we find the output values for each decision tree leaf. That means there might be a case where one leaf gets more than one residual, so we need to find the final output of all the leaves. To find the output, we can simply take the average of all the numbers in a leaf; it doesn’t matter if there is only one number or more than one.
Let’s see why we take the average of all the numbers. Mathematically this step can be represented as:

Here, hm(xi) is the DT made on residuals, and m is the number of DTs. When m=1, we are talking about the first DT, and when it is “M,” we are talking about the last DT.
The leaf’s output value is the gamma value that minimizes the Loss function. The left-hand side “Gamma” is the output value of a particular leaf. On the right-hand side [F m-1 (x i )+ƴh m (x i ))] is similar to step 1 but here the difference is that we are taking previous predictions whereas earlier there was no previous prediction.
Example of Calculating Regression Tree Output
Let’s understand this even better with the help of an example. Suppose this is our regressor tree:

We see 1st residual goes in R1,1 ,2nd and 3rd residuals go in R2,1 and 4th residual goes in R3,1 .
Let’s calculate the output for the first leave that is R1,1

Now we need to find the value for gamma for which this function is minimum. So we find the derivative of this equation w.r.t gamma and put it equal to 0.

Hence the leaf R1,1 has an output value of -2500. Now let’s solve for the R2,1.

Let’s take the derivative to get the minimum value of gamma for which this function is minimum:

We end up with the average of the residuals in the leaf R2,1 . Hence if we get any leaf with more than 1 residual, we can simply find the average of that leaf and that will be our final output.
Now, after calculating the output of all the leaves, we get:

Step 5: Update Previous Model Predictions
This is finally the last step where we have to update the predictions of the previous model. It can be updated as:

where m is the number of decision trees made.
Since we have just started building our model so our m=1. Now to make a new DT our new predictions will be:

- Here, Fm-1(x) is the prediction of the base model (previous prediction) since F1-1=0. Since F0 is our base model, the previous prediction is 14500.
- nu is the learning rate that is usually selected between 0-1. It reduces the effect each tree has on the final prediction, and this improves accuracy in the long run. Let’s take nu=0.1 in this example.
- Hm(x) is the recent DT made on the residuals.
Let’s calculate the new prediction now:

Suppose we want to find a prediction of our first data point which has a car height of 48.8. This data point will pass through this decision tree, and the output will multiply by the learning rate before adding to the previous prediction.
Now, let’s say m=2, which means we have built 2 decision trees and want to make new predictions.
This time, we will add the previous prediction, F1(x), to the new DT made on residuals. We will iterate through these steps again and again until the loss is negligible.
I am taking a hypothetical example here just to
make you understand how this predicts for a new dataset:

If a new data point comes, say, height = 1.40, it’ll go through all the trees and then will give the prediction. Here, we have only 2 trees; hence, the data point will go through these 2 trees, and the final output will be F2(x).
What is a Gradient Boosting Classifier?
A gradient-boosting classifier works when the target column is binary. You apply all the steps explained in the gradient-boosting regressor here, the only difference is changing the loss function. Earlier, we used Mean squared error when the target column was continuous, but we will use log-likelihood as our loss function this time.
Let’s see how this loss function works.
The loss function for the classification problem is given below:

Our first step in the Gradient Boosting Algorithm in Machine Learning was to initialize the model with some constant value, there we used the average of the target column but here we’ll use log(odds) to get that constant value. The question arises: Why log(odds)?
When we differentiate this loss function, we will get a function of log(odds), and then we need to find a value of log(odds) for which the loss function is minimum.
How Does it Work?
Are you confused right? Now let’s see how it works:
Let’s first transform this loss function so that it is a function of loloss functiong(odds). I’ll tell you later why we did this transformation.



Now, this is our loss function, and we need to minimize it. For this, we take the derivative of this w.r.t to log(odds) and then put it equal to 0,

Here, ‘y’ denotes the observed values.
- You must be wondering why we transformed the loss function into a log(odds) function. Sometimes, the log(odds) function is easy to use, and sometimes, the predicted probability “p” function is easy to use.
- It isn’t compulsory to transform the loss function; we did this just to make calculations easy.
- Hence, the minimum value of this loss function will be our first prediction (base model prediction)
In the gradient boosting regressor, our next step was calculating the pseudo residuals, where we multiplied the derivative of the loss function with -1. We will do the same, but now the loss function is different, and we are dealing with the probability of an outcome.

After finding the residuals, we can build a decision tree with all independent variables and target variables as “Residuals”.
When we have our first decision tree, we find the final output of the leaves because there might be a case where a leaf gets more than 1 residuals, so we need to calculate the final output value. The math behind this step is out of the scope of this article, so I will mention the direct formula to calculate the output of a leaf:

Finally, we are ready to get new predictions by adding our base model with the new tree we made on residuals.
Implementation of GBM Using scikit-learn
For implementing the GBM algorithm on a dataset, we will use the Income Evaluation dataset, which has information about an individual’s personal life and an output of 50K or = 50. The dataset can be found here.
The task here is to classify an individual’s income based on the required inputs about his personal life.
First, let’s import all required libraries.
# Import all relevant libraries
from sklearn.ensemble import GradientBoostingClassifier
import numpy as np
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, confusion_matrix
from sklearn import preprocessing
import warnings
warnings.filterwarnings("ignore")
Now let’s read the dataset and look at the columns to understand the information better.df = pd.read_csv('income_evaluation.csv')
df.head()
I have already done the data preprocessing part, and you can see the whole code here. My main aim here is to tell you how to implement this in Python. Now, for training and testing our model, the data has to be divided into train and test sets.
We will also scale the data to lie between 0 and 1.
# Split dataset into test and train dataX_train, X_test, y_train, y_test = train_test_split(df.drop(‘income’, axis=1),df[‘income’], test_size=0.2)Now, let’s define the Gradient Boosting Classifier and its hyperparameters. Next, we will fit this model into the training data.
# Define Gradient Boosting Classifier with hyperparameters
gbc=GradientBoostingClassifier(n_estimators=500,learning_rate=0.05,random_state=100,max_features=5 )
# Fit train data to GBC
gbc.fit(X_train,y_train)- The model has been trained and we can now observe the outputs.
- Below, you can see the confusion matrix of the model, which reports the number of classifications and misclassifications.
# Confusion matrix will give number of correct and incorrect classifications
print(confusion_matrix(y_test, gbc.predict(X_test)))
The Gradient Boosting Classifier has misclassified 1334 times compared to 8302 correct classifications. The model has performed decently.
Let’s check the accuracy:
# Accuracy of model
print("GBC accuracy is %2.2f" % accuracy_score(
y_test, gbc.predict(X_test)))Let’s check the classification report also:
from sklearn.metrics import classification_report
pred=gbc.predict(X_test)
print(classification_report(y_test, pred))- The accuracy is 86%, which is pretty good, but you can improve it by tuning the hyperparameters or processing the data to remove outliers.This, however, gives us the basic idea behind gradient boosting and its underlying working principles.
- The accuracy is 86%, which is pretty good, but you can improve it by tuning the hyperparameters or processing the data to remove outliers.
This, however, gives us the basic idea behind gradient boosting and its underlying working principles.
Parameter Tuning in Gradient Boosting (GBM) in Python
Tuning n_estimators and Learning rate
n_estimators is the number of trees (weak learners) that we want to add in the model. There are no optimum values for the learning rate, as low values always work better, given that we train on a sufficient number of trees. A high number of trees can be computationally expensive. That’s why I have taken a few number of trees here.
from sklearn.model_selection import GridSearchCV
grid = {
'learning_rate':[0.01,0.05,0.1],
'n_estimators':np.arange(100,500,100),
}
gb = GradientBoostingClassifier()
gb_cv = GridSearchCV(gb, grid, cv = 4)
gb_cv.fit(X_train,y_train)
print("Best Parameters:",gb_cv.best_params_)
print("Train Score:",gb_cv.best_score_)
print("Test Score:",gb_cv.score(X_test,y_test))
After tuning n_estimators and learning rate, the accuracy increased from 86 to 89. Also, the “true positive” and “true negative” rates improved.
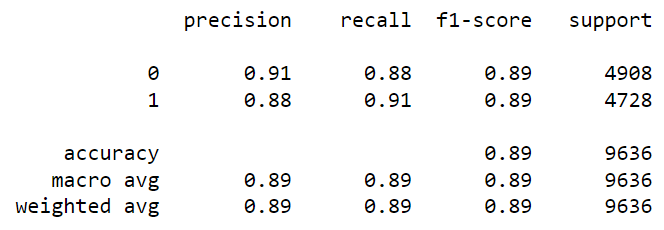
We can also tune the max_depth parameter, which you must have heard in decision trees and random forests.
grid = {'max_depth':[2,3,4,5,6,7] }
gb = GradientBoostingClassifier(learning_rate=0.1,n_estimators=400)
gb_cv = GridSearchCV(gb, grid, cv = 4)
gb_cv.fit(X_train,y_train)
print("Best Parameters:",gb_cv.best_params_)
print("Train Score:",gb_cv.best_score_)
print("Test Score:",gb_cv.score(X_test,y_test))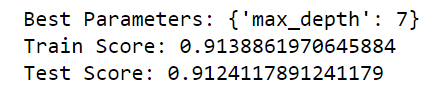
The accuracy increased even more when we tuned the parameter “max_depth”.
Conclusion
I hope you understood how the Gradient Boosting algorithm works under the hood. I have tried to show you the math behind this in the easiest way possible. Apart from this, there are many other techniques for improving model performance, such as XGBoost, LightGBM, and CatBoost. I will explain about these in my upcoming articles.
Hope you like the article! The gradient boosting regressor is a powerful tool in machine learning, and gradient boosting machines (GBM) significantly enhance predictive accuracy, making them essential for data analysis.
Key Takeaways:
- Gradient boosting builds sequential models to reduce errors of previous iterations.
- The algorithm minimizes a loss function by adding weak learners using gradient descent.
- Pseudo-residuals and decision trees on residuals are key components of the process.
- Hyperparameter tuning, especially n_estimators and learning rate, can significantly improve model performance.
Frequently Asked Questions
Q1. How does the gradient boosting algorithm work?
A. The Gradient Boosting algorithm in Machine Learning sequentially adds weak learners to form a strong learner. Initially, it builds a model on the training data. Then, it calculates the residual errors and fits subsequent models to minimize them. Consequently, the models are combined to make accurate predictions.
Q2. What is an example of gradient boosting?
A. An example of gradient boosting is using it in a housing price prediction model. By iterative training on the residual errors of previous models, it improves the accuracy of the predictions. Consequently, the final model provides precise price estimates.
Q3. Is XGBoost a gradient boosting algorithm?
A. Yes, XGBoost is a gradient boosting algorithm. It extends the principles of gradient boosting by incorporating additional features like regularization and parallel processing, enhancing both performance and accuracy.
Q4. What is GBM in machine learning?
A. GBM Algorithm, or Gradient Boosting Machine, in machine learning refers to a class of ensemble techniques that build models sequentially to reduce errors. Consequently, it produces a strong predictive model by combining multiple weak learners, enhancing overall accuracy and robustness.
I have recently graduated with a Bachelor's degree in Statistics and am passionate about pursuing a career in the field of data science, machine learning, and artificial intelligence. Throughout my academic journey, I thoroughly enjoyed exploring data to uncover valuable insights and trends.
I am eager to continue learning and expanding my knowledge in the field of data science. I am particularly interested in exploring deep learning and natural language processing, and I am constantly seeking out new challenges to improve my skills. My ultimate goal is to use my expertise to help businesses and organizations make data-driven decisions and drive growth and success.







This is a great guide for beginners!
log(a)-log(b) is not equal to log(a)/log(b). It's just equal to log(a/b). It would be better to rectify that mistake here, or I would expect some kind of review process from AV before posting stuff online.
I have several questions about article. But it will be better to me ask them personally in some app, where i can attach pictures. Thanks for article. I 've got the idea of gradient boosting through it!