Overview
- Check out our pick of the top 24 Python libraries for data science
- We’ve divided these libraries into various data science functions, such as data collection, data cleaning, data exploration, modeling, among others
- Any Python libraries you feel we should include? Let us know!
Introduction
I’m a massive fan of the Python language. It was the first programming language I learned for data science and it has been a constant companion ever since. Three things stand out about Python for me:
- Its ease and flexibility
- Industry-wide acceptance: It is far and away the most popular language for data science in the industry
- The sheer number of Python libraries for data science
In fact, there are so many Python libraries out there that it can become overwhelming to keep abreast of what’s out there. That’s why I decided to take away that pain and compile this list of 24 awesome Python libraries covering the end-to-end data science lifecycle.

That’s right – I’ve categorized these libraries by their respective roles in data science. So I’ve mentioned libraries for data cleaning, data manipulation, visualization, building models and even model deployment (among others). This is quite a comprehensive list to get you started on your data science journey using Python.
Python libraries for different data science tasks:
- Python Libraries for Data Collection
- Beautiful Soup
- Scrapy
- Selenium
- Python Libraries for Data Cleaning and Manipulation
- Pandas
- PyOD
- NumPy
- Spacy
- Python Libraries for Data Visualization
- Matplotlib
- Seaborn
- Bokeh
- Python Libraries for Modeling
- Scikit-learn
- TensorFlow
- PyTorch
- Python Libraries for Model Interpretability
- Lime
- H2O
- Python Libraries for Audio Processing
- Librosa
- Madmom
- pyAudioAnalysis
- Python Libraries for Image Processing
- OpenCV-Python
- Scikit-image
- Pillow
- Python Libraries for Database
- Psycopg
- SQLAlchemy
- Python Libraries for Deployment
- Flask
Python Libraries for Data Collection
Have you ever faced a situation where you just didn’t have enough data for a problem you wanted to solve? It’s an eternal issue in data science. That’s why learning how to extract and collect data is a very crucial skill for a data scientist. It opens up avenues that were not previously possible.
So here are three useful Python libraries for extracting and collection data.
Beautiful Soup
One of the best ways of collecting data is by scraping websites (ethically and legally of course!). Doing it manually takes way too much manual effort and time. Beautiful Soup is your savior here.
Beautiful Soup is an HTML and XML parser which creates parse trees for parsed pages which is used to extract data from webpages. This process of extracting data from web pages is called web scraping.
Use the following code to install BeautifulSoup:
pip install beautifulsoup4
Here’s a simple code to implement Beautiful Soup for extracting all the anchor tags from HTML:
#!/usr/bin/python3
# Anchor extraction from html document
from bs4 import BeautifulSoup
from urllib.request import urlopen
with urlopen('https://en.wikipedia.org/wiki/Lists_of_countries_and_territories') as response:
soup = BeautifulSoup(response, 'html.parser')
for anchor in soup.find_all('a'):
print(anchor.get('href', '/'))I recommend going through the below article to learn how to use Beautiful Soup in Python:
Scrapy
Scrapy is another super useful Python library for web scraping. It is an open source and collaborative framework for extracting the data you require from websites. It is fast and simple to use.
Here’s the code to install Scrapy:
pip install scrapy
It is a framework for large scale web scraping. It gives you all the tools you need to efficiently extract data from websites, process them as you want, and store them in your preferred structure and format.
Here’s a simple code to implement Scrapy:
Here’s the perfect tutorial to learn Scrapy and implement it in Python:
Selenium
Selenium is a popular tool for automating browsers. It’s primarily used for testing in the industry but is also very handy for web scraping. Selenium is actually becoming quite popular in the IT field so I’m sure a lot of you would have at least heard about it.

We can easily program a Python script to automate a web browser using Selenium. It gives us the freedom we need to efficiently extract the data and store it in our preferred format for future use.
I wrote an article recently about scraping YouTube video data using Python and Selenium:
Python Libraries for Data Cleaning and Manipulation
Alright – so you’ve collected your data and are ready to dive in. Now it’s time to clean any messy data we might be faced with and learn how to manipulate it so our data is ready for modeling.
Here are four Python libraries that will help you do just that. Remember, we’ll be dealing with both structured (numerical) as well as text data (unstructured) in the real-world – and this list of libraries covers it all.
Pandas
When it comes to data manipulation and analysis, nothing beats Pandas. It is the most popular Python library, period. Pandas is written in the Python language especially for manipulation and analysis tasks.
The name is derived from the term “panel data”, an econometrics term for datasets that include observations over multiple time periods for the same individuals. – Wikipedia
Pandas come pre-installed with Python or Anaconda but here’s the code in case required:
pip install pandas
Pandas provides features like:
- Dataset joining and merging
- Data Structure column deletion and insertion
- Data filtration
- Reshaping datasets
- DataFrame objects to manipulate data, and much more!
Here is an article and an awesome cheatsheet to get your Pandas skills right up to scratch:
- 12 Useful Pandas Techniques in Python for Data Manipulation
- CheatSheet: Data Exploration using Pandas in Python
PyOD
Struggling with detecting outliers? You’re not alone. It’s a common problem among aspiring (and even established) data scientists. How do you define outliers in the first place?
Don’t worry, the PyOD library is here to your rescue.
PyOD is a comprehensive and scalable Python toolkit for detecting outlying objects. Outlier detection is basically identifying rare items or observations which are different significantly from the majority of data.
You can download pyOD by using the below code:
pip install pyod
How does PyOD work and how can you implement it on your own? Well, the below guide will answer all your PyOD questions:
NumPy
NumPy, like Pandas, is an incredibly popular Python library. NumPy brings in functions to support large multi-dimensional arrays and matrices. It also brings in high-level mathematical functions to work with these arrays and matrices.
NumPy is an open-source library and has multiple contributors. It comes pre-installed with Anaconda and Python but here’s the code to install it in case you need it at some point:
$ pip install numpy
Below are some of the basic functions you can perform using NumPy:
Array creation
output - [1 2 3]
[0 1 2 3 4 5 6 7 8 9]
Basic operations
output - [1. 1.33333333 1.66666667 4. ]
[ 1 4 9 36]
And a whole lot more!
SpaCy
We’ve discussed how to clean and manipulate numerical data so far. But what if you’re working on text data? The libraries we’ve seen so far might not cut it.
Step up, spaCy. It is a super useful and flexible Natural Language Processing (NLP) library and framework to clean text documents for model creation. SpaCy is fast as compared to other libraries which are used for similar tasks.
To install Spacy in Linux:
pip install -U spacy python -m spacy download en
To install it on other operating systems, go through this link.

Of course we have you covered for learning spaCy:
Python Libraries for Data Visualization
So what’s next? My favorite aspect of the entire data science pipeline – data visualization! This is where our hypotheses are checked, hidden insights are unearthed and patterns are found.
Here are three awesome Python libraries for data visualization.
Matplotlib
Matplotlib is the most popular data visualization library in Python. It allows us to generate and build plots of all kinds. This is my go-to library for exploring data visually along with Seaborn (more of that later).
You can install matplotlib through the following code:
$ pip install matplotlib
Below are a few examples of different kind of plots we can build using matplotlib:
Histogram

3D Graph

Since we’ve covered Pandas, NumPy and now matplotlib, check out the below tutorial meshing all these three Python libraries:
Seaborn
Seaborn is another plotting library based on matplotlib. It is a python library that provides high level interface for drawing attractive graphs. What matplotlib can do, Seaborn just does it in a more visually appealing manner.
Some of the features of Seaborn are:
- A dataset-oriented API for examining relationships between multiple variables
- Convenient views onto the overall structure of complex datasets
- Tools for choosing color palettes that reveal patterns in your data
You can install Seaborn using just one line of code:
pip install seaborn
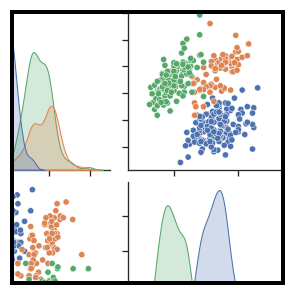
Let’s go through some cool graphs to see what seaborn can do:

Here’s another example:

Got to love Seaborn!
Bokeh
Bokeh is an interactive visualization library that targets modern web browsers for presentation. It provides elegant construction of versatile graphics for a large number of datasets.
Bokeh can be used to create interactive plots, dashboards and data applications. You’ll be pretty familiar with the installation process by now:
pip install bokeh
Feel free to go through the following article to learn more about Bokeh and see it in action:
Python Libraries for Modeling
And we’ve arrived at the most anticipated section of this article – building models! That’s the reason most of us got into data science in the first place, isn’t it?
Let’s explore model building through these three Python libraries.
Scikit-learn
Like Pandas for data manipulation and matplotlib for visualization, scikit-learn is the Python leader for building models. There is just nothing else that compares to it.
In fact, scikit-learn is built on NumPy, SciPy and matplotlib. It is open source and accessible to everyone and reusable in various contexts.
Here’s how you can install it:
pip install scikit-learn
Scikit-learn supports different operations that are performed in machine learning like classification, regression, clustering, model selection, etc. You name it – and scikit-learn has a module for that.
I’d also recommend going through the following link to learn more about scikit-learn:
TensorFlow
Developed by Google, TensorFlow is a popular deep learning library that helps you build and train different models. It is an open source end-to-end platform. TensorFlow provides easy model building, robust machine learning production, and powerful experimentation tools and libraries.
An entire ecosystem to help you solve challenging, real-world problems with Machine Learning – Google

TensorFlow provides multiple levels of abstraction for you to choose from according to your need. It is used for building and training models by using the high-level Keras API, which makes getting started with TensorFlow and machine learning easy.
Go through this link to see the installation processes. And get started with TensorFlow using these articles:
- TensorFlow 101: Understanding Tensors and Graphs to get you started in Deep Learning
- Getting Started with Deep Learning using Keras and TensorFlow in R
PyTorch
What is PyTorch? Well, it’s a Python-based scientific computing package that can be used as:
- A replacement for NumPy to use the power of GPUs
- A deep learning research platform that provides maximum flexibility and speed
Go here to check out the installation process for different operating systems.
PyTorch offers the below features:
- Hybrid Front-End
- Tools and libraries: An active community of researchers and developers have built a rich ecosystem of tools and libraries for extending PyTorch and supporting development in areas from computer vision to reinforcement learning
- Cloud support: PyTorch is well supported on major cloud platforms, providing frictionless development and easy scaling through prebuilt images, large scale training on GPUs, ability to run models in a production scale environment, and more
Here are two incredibly detailed and simple-to-understand articles on PyTorch:
- An Introduction to PyTorch – A Simple yet Powerful Deep Learning Library
- Get Started with PyTorch – Learn How to Build Quick & Accurate Neural Networks (with 4 Case Studies!)
Python Libraries for Data Interpretability
Do you truly understand how your model is working? Can you explain why your model came up with the results that it did? These are questions every data scientist should be able to answer. Building a black box model is of no use in the industry.
So, I’ve mentioned two Python libraries that will help you interpret your model’s performance.
LIME
LIME is an algorithm (and library) that can explain the predictions of any classifier or regressor. How does LIME do this? By approximating it locally with an interpretable model. Inspired from the paper “Why Should I Trust You?”: Explaining the Predictions of Any Classifier”, this model interpreter can be used to generate explanations of any classification algorithm.
Installing LIME is this easy:
pip install lime
This article will help build an intuition behind LIME and model interpretability in general:
H2O
I’m sure a lot of you will have heard of H2O.ai. They are market leaders in automated machine learning. But did you know they also have a model interpretability library in Python?
H2O’s driverless AI offers simple data visualization techniques for representing high-degree feature interactions and nonlinear model behavior. It provides Machine Learning Interpretability (MLI) through visualizations that clarify modeling results and the effect of features in a model.

Go through the following link to read more about H2O’s Driverless AI perform MLI.
Python Libraries for Audio Processing
Audio processing or audio analysis refers to the extraction of information and meaning from audio signals for analysis or classification or any other task. It’s becoming a popular function in deep learning so keep an ear out for that.
LibROSA
LibROSA is a Python library for music and audio analysis. It provides the building blocks necessary to create music information retrieval systems.
Click this link to check out the installation details.

Here’s an in-depth article on audio processing and how it works:
Madmom
The name might sound funny, but Madmom is a pretty nifty audio data analysis Python library. It is an audio signal processing library written in Python with a strong focus on music information retrieval (MIR) tasks.
You need the following prerequisites to install Madmom:
- NumPy
- SciPy
- Cython
- Mido
And you need the below packages to test the installation:
- PyTest
- PyAudio
- PyFftw
The code to install Madmom:
pip install madmom

We even have an article to learn how Madmom works for music information retrieval:
pyAudioAnalysis
pyAudioAnalysis is a Python library for audio feature extraction, classification, and segmentation. It covers a wide range of audio analysis tasks, such as:
- Classify unknown sounds
- Detect audio events and exclude silence periods from long recordings
- Perform supervised and unsupervised segmentation
- Extract audio thumbnails and much more
You can install it by using the following code:
pip install pyAudioAnalysis

Python Libraries for Image Processing
You must learn how to work with image data if you’re looking for a role in the data science industry. Image processing is becoming ubiquitous as organizations are able to collect more and more data (thanks largely to advancements in computational resources).
So make sure you’re comfortable with at least one of the below three Python libraries.
OpenCV-Python
When it comes to image processing, OpenCV is the first name that comes to my mind. OpenCV-Python is the Python API for image processing, combining the best qualities of the OpenCV C++ API and the Python language.
It is mainly designed to solve computer vision problems.
OpenCV-Python makes use of NumPy, which we’ve seen above. All the OpenCV array structures are converted to and from NumPy arrays. This also makes it easier to integrate with other libraries that use NumPy such as SciPy and Matplotlib.

Install OpenCV-Python in your system:
pip3 install opencv-python
Here are two popular tutorials on how to use OpenCV in Python:
- Building a Face Detection Model from Video using Deep Learning (Python Implementation)
- 16 OpenCV Functions to Start your Computer Vision journey (with Python code)
Scikit-image
Another python dependency for image processing is Scikit-image. It is a collection of algorithms for performing multiple and diverse image processing tasks.
You can use it to perform image segmentation, geometric transformations, color space manipulation, analysis, filtering, morphology, feature detection, and much more.
We need to have the below packages before installing scikit-image:
- Python (>= 3.5)
- NumPy (>= 1.11.0)
- SciPy (>= 0.17.0)
- joblib (>= 0.11)
And this is how you can install scikit-image on your machine:
pip install -U scikit-learn
Pillow
Pillow is the newer version of PIL (Python Imaging Library). It is forked from PIL and has been adopted as a replacement for the original PIL in some Linux distributions like Ubuntu.
Pillow offers several standard procedures for performing image manipulation:
- Per-pixel manipulations
- Masking and transparency handling
- Image filtering, such as blurring, contouring, smoothing, or edge finding
- Image enhancing, such as sharpening, adjusting brightness, contrast or color
- Adding text to images, and much more!
How to install Pillow? It’s this simple:
pip install Pillow

Check out the following AI comic illustrating the use of Pillow in computer vision:
Python Libraries for Database
Learning how to store, access and retrieve data from a database is a must-have skill for any data scientist. You simply cannot escape from this aspect of the role. Building models is great but how would you do that without first retrieving the data?
I’ve picked out two Python libraries related to SQL that you might find useful.
psycopg
Psycopg is the most popular PostgreSQL (an advanced open source relational database ) adapter for the Python programming language. At its core, Psycopg fully implements the Python DB API 2.0 specifications.

SQLAlchemy
Ah, SQL. The most popular database language. SQLAlchemy, a Python SQL toolkit and Object Relational Mapper, gives application developers the full power and flexibility of SQL.

It is designed for efficient and high-performing database access. SQLAlchemy considers the database to be a relational algebra engine, not just a collection of tables.
To install SQLAlchemy, you can use the following line of code:
pip install SQLAlchemy
Python Libraries for Deployment
Do you know what model deployment is? If not, you should learn this ASAP. Deploying a model means putting your final model into the final application (or the production environment as it’s technically called).
Flask
Flask is a web framework written in Python that is popularly used for deploying data science models. Flask has two components:
- Werkzeug: It is a utility library for the Python programming language
- Jinja: It is a template engine for Python
Check out the example below to print “Hello world”:
The below article is a good starting point to learn Flask:
End Notes
In this article, we saw a huge bundle of python libraries that are commonly used while doing a data science project. There are a LOT more libraries that are out there but these are the core ones every data scientist should know.
Any Python libraries I missed? Or any library from our list which you particularly found useful? Let me know in the comments section below!
A Data Science Enthusiast who loves reading & writing about Data Science and its applications. He has done many projects in this field and his recent work include concepts like Web Scraping, NLP etc. He is a Data Science Content Strategist Intern at Analytics Vidhya. And currently pursuing BTech in Computer Science from DIT University, Dehradun.




Did you miss Altair as the grammar based visualization library?
Hi RDK, Thanks for mentioning Altair. I missed it somehow and I really appreciate you for bringing this up.
I'm not sure how yellowbrick is excluded when it comes to data visualization for machine learning.
Hi Nathan I came across many libraries, but had to choose limited. Thank you for mentioning Yellowbrick.
Ver helpful Article.. Thanks a lot!
You're most welcome Sunil, Thank you for your response