
Data engineers are a rare breed. Without them, a machine learning project would crumble before it starts. Their knowledge and understanding of software and hardware tools, combined with an innate sense of building flexible data pipelines, is unparalleled.
So why are data engineering concepts not taught to aspiring data science professionals? After all:
“A data scientist is only as good as the data he/she has access to.”
And data engineers are the ones who build robust pipelines that transform the data so the data scientists can use it. They are a critical cog in any machine learning project. Just look at the surge in the term ‘Data Engineer’ on Google in the last 5 years:
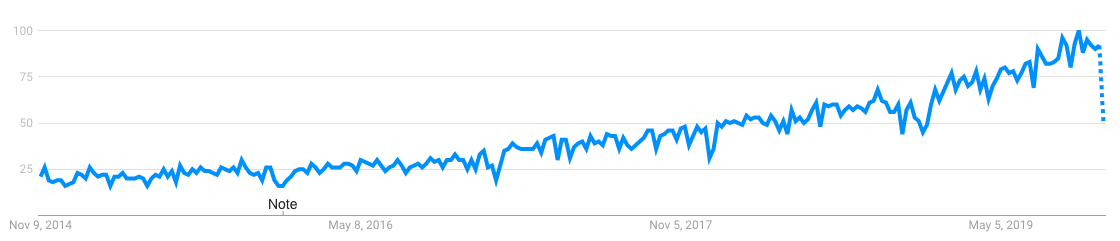
Incredible! Think of a data engineer as a Formula 1 car builder. That person can make or break a champion driver – it’s in his/her hands how smooth and well built the car will be, right? That’s what a data engineer does in a machine learning project.
Given the importance of this role and the demand for data engineering professionals, we have included even more sessions on the topic at DataHack Summit 2019, India’s largest applied Artificial Intelligence and Machine Learning conference!
You will gain a wider understanding of Data Engineering and its importance through our eminent speakers who will also take a hands-on approach to Data Engineering. There’s just one week to go, so:
RESERVE YOUR SEAT HERE!
Power-packed Data Engineering Sessions at DataHack Summit 2019
- MLOps – Putting Machine Learning Models to Production
- Handling High-Velocity Data Streams using Kafka & Spark
- Data Engineering in Action – Working with Data at Scale
- Analyzing Streaming Data using Online Learning
- All You Need to Know about Deploying DL Models using TensorFlow Serving
- Deploy Deep Learning Models in Production using PyTorch
Here is a comprehensive list of resources on Data Engineering that you might find useful:
Hack sessions are one-hour hands-on coding sessions on the latest frameworks, architectures, and libraries in machine learning, deep learning, reinforcement learning, NLP, and other domains.
MLOps – Putting Machine Learning Models to Production by Akash Tandon
You may have heard of data science’s 80/20 rule. It states that 80% of a data scientist’s time is spent dealing with messy data and only 20% of it is spent performing analysis. It’s more or less true but there’s a caveat attached to it.
A critical aspect that was overlooked, until recently, was the operationalization and deployment of data science and specifically, machine learning pipelines. Be it a startup or enterprise, it’s common to hear of machine learning projects getting stuck in the proof-of-concept phase.

This is a make-or-break facet of your project. You need to be aware of how this works and where it fits into your machine learning pipeline.
Akash Tandon, a Senior Data Engineer at Atlan, will be taking a hands-on hack session on ‘MLOps – Putting Machine Learning Models to Production’. He will focus on deploying machine learning models locally and on a cloud platform.
To do that, he will borrow relevant principles from software engineering and DataOps disciplines. He will also cover various concepts including the need for CI/CD pipelines for machine learning, retraining, versioning of code/model/data, containerization, inference APIs, and monitoring.
Here are the key takeaways from Akash’s hack session:
- Understand the need for and basic principles of MLOps
- Basic building blocks of production machine learning pipelines
- Learn how to use cloud platforms for handling scale
Handling High-Velocity Data Streams using Kafka & Spark by Durga Vishwanatha Raju
Spark and Kafka – two of the most widely used tools in the Big Data domain. I invariably come across them when I’m reading up on how a data engineering pipeline was set up or is being deployed. They are vital tools in a data scientist’s toolbox – make sure you’re well versed with them.

Durga Viswanatha Raju, a veteran big data and data engineering expert and leader, will be showcasing these tools in his hack session on ‘Handling High-Velocity Data Streams using Kafka and Spark’.
It promises to be a very interesting and knowledge-rich session. Here’s a quick overview of what he plans to cover:
- Overview of the Kafka ecosystem
- Getting data from log files into Kafka Topic using Kafka Connect
- Processing data using Spark Structured Streaming
- Displaying Streaming Analytics Results
- Overview of Storing results to Databases like HBase
Here are the key takeaways from Durga’s hack session:
- Get an overview of streaming analytics
- Integration of Kafka and Spark structured streaming
If new you’re to Spark, I suggest going through the below in-depth tutorials:
- Comprehensive Introduction to Apache Spark, RDDs and Dataframes
- PySpark for Beginners – Take your First Steps into Big Data Analytics
Data Engineering in Action – Working with Data at Scale by Amit Prabhu and Rishabh Raj
Data engineering becomes pivotal when we’re dealing with vast amounts of data. The complexity increases and it becomes difficult to handle the sheer volume – so how do you pivot and integrate data engineering into your existing machine learning pipeline?

Before you begin the analysis, structuring the data in the right manner is important. Different sources mean different schema, extraction logic, de-duplication and being in sync with changing data sources, in addition to a number of other challenges. That’s where data engineering and more specifically, data integration techniques come in.
In this hack session by Amit Prabhu and Rishabh Raj, you will get insights on data integration sources and best practices associated with it. The need for data engineering and its importance in data science will also be highlighted at a broad level.
Key Takeaways from their hack session:
- Fundamental understanding of data engineering
- Best practices in data integration
Analyzing Streaming Data using Online Learning by Dr. Sayan Putatunda
Do you know what data streaming is? How it works and why every data scientist should be aware of it? If not, you need to rectify this immediately!
The most continuous data series are time series data, like traffic sensors, health sensors, transaction logs, activity logs, etc. In fact, the IoT devices (all kinds of sensors) are radiating real-time data.

Streaming such high volume and velocity data comes with its own set of challenges:
- One-time pass
- Infinite data
- Very high speed of data accumulation
- Limitations of memory, and
- Concept Drift i.e. change in the distribution of incoming data
Due to these unique challenges, conventional batch processing methods are not effective and there is a need for new methodologies.
So here, we have our eminent speaker Dr. Sayan Putatunda who will discuss the need for Streaming data analysis and also share with us why conventional batch processing methods are not sufficient. His talk at DataHack Summit 2019 will be on ‘Analyzing Streaming Data using Online Learning’.
Hear from Dr. Sayan himself on what you can expect from his Power Talk:
Also, I would recommend taking out some time and watching the below webinar by Varun Khandelwal on streaming analytics (it’s a good precursor to any data engineering session):
All You Need to Know about Deploying Deep Learning Models using Tensorflow Serving by Tata Ganesh
Ah, one of my favorite topics – deploying deep learning models. It is not taught in most online courses, isn’t spoken about much at meetups and quite a lot of aspiring data scientists are not aware of it. And yet it’s a key part of EVERY deep learning project in the industry.
There are certain challenges you might face when deploying these deep learning models, such as model versioning, containerization of the model, etc.
Web frameworks like Flask and Django can be used to wrap the model into a REST API and expose the API. But this solution requires developers to write and maintain code to handle requests to the model and support other deployment-related features as well.

To tackle this problem, TensorFlow introduced TensorFlow Serving, a flexible, high-performance serving system for machine learning models, designed for production environments.
In this hack session, Tata Ganesh, a Senior Machine Learning Engineer at Capillary Technologies, will help us in understanding TensorFlow Serving and illustrate its features using an example use case.
Here is what he has to say about the hack session, listen up!
Deploy Deep Learning Models in Production using PyTorch by Vishnu Subramanian
Another really intriguing hack session on deploying deep learning models – this time using PyTorch. We know how difficult delivering artificial intelligence predictions are. They come with a wide variety of challenges, like:
- The data has to reside on the client-side, which requires the model to run on devices like mobile phones, IoT devices
- Handling multiple user requests
- Handling applications that can have near real-time requirements, when the model inference times can be in few seconds
The solution to this is PyTorch. It is extremely popular among researchers, but production teams have had a tough time to convert the latest research into a production-friendly environment.

From PyTorch 1.0, the community and several teams from companies like Facebook and Microsoft have taken significant efforts to make it easier and seamless for production usage.
So, in this hack session, our speaker Vishnu Subramanian will facilitate you to look at different approaches to how teams can put their models in production.
Key Takeaways from Vishnu’s hack session are:
- Deploy PyTorch models using Flask
- Handle multiple user requests
- Understand how to use torch script for saving the trained model as a graph and loading it in another language like C++
- Reduce inference time by using Quantization techniques
And if you’re new to PyTorch or need a quick refresher, here is the perfect article to get you started:
End Notes

Data engineering is a booming field – and there are a plethora of openings in the industry right now. I’m sure you’ve already gathered this – the role of a data engineer is much broader than just managing data workflows, pipelines, and Extract, Transform and Load (ETL) processes.
If you want to master Data Engineering, then start learning right away with these incredible sessions at DataHack Summit 2019. It’s a place where the brightest minds collaborate to deliver real-time and hands-on learning experience on various topics related to applied Machine Learning and Artificial Intelligence.







