Pivot tables – The Swiss Army Knife of Data Analysis
I love how quickly I can analyze data using pivot tables. With one click of my mouse, I can drill down into the granular details about a certain product category or zoom out and get a high-level overview of the data at hand. Microsoft Excel users will be intimately familiar with these pivot tables. They’re the most used feature of Excel, and it’s easy to see why! But did you know that you can build these pivot tables using Pandas in Python? A pandas pivot table is easy to create and works just the same.
That’s right! The wonderful Pandas library offers a list of functions, among which a function called pivot_table is used to summarize a feature’s values in a neat two-dimensional table. The pivot table is similar to the dataframe.groupby() function in Pandas. We’ll see how to build such a pivot table in Python here. We can even use Pandas pivot table along with the plotting libraries to create different visualizations. Pivot tables offer a ton of flexibility for me as a data scientist. I’ll be honest – I rely on them a lot during the exploratory data analysis phase of a data science project.
Learning Objectives
- Learn to create a python pivot table using Pandas.
- Learn to use different aggregation functions on the features of the created pivot table in pandas.
- Learn to handle missing data in the pandas pivot table.
Table of contents
Sample Dataset for Testing Pandas Pivot Table
I’m sure you’ve come across the Titanic dataset in your data science journey. It’s among the first datasets we pick up when we’re ready to explore a project. I’ll be using that to show you the efficacy of the pivot_table function.
Let’s import the relevant libraries:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')For all those who forgot what the Titanic dataset looks like, I present to you the dataset!
df = pd.read_csv('drive/My Drive/AV/train.csv')
df.head()Table of Contents
Sample Dataset for Testing Pandas Pivot Table
Building a Pivot Table Using Pandas
Conclusion
Frequently Asked Questions
Q1. How do you create a pivot table in Python?
Q2. What is the DataFrame.pivot method?
Q3. what is the difference between the pivot and pivot_table methods in Python Pandas?
Sample Dataset for Testing Pandas Pivot Table
I’m sure you’ve come across the Titanic dataset in your data science journey. It’s among the first datasets we pick up when we’re ready to explore a project. I’ll be using that to show you the efficacy of the pivot_table function.
Let’s import the relevant libraries:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
plt.style.use('ggplot')
For all those who forgot what the Titanic dataset looks like, I present to you the dataset!
df = pd.read_csv('drive/My Drive/AV/train.csv')
df.head()
I will be dropping multiple columns to make it easier to analyze the data and demonstrate the capabilities of the pivot_table function:
df.drop(['PassengerId','Ticket','Name'],inplace=True,axis=1)
The above syntax drops the columns with column names, 'PassengerId', 'Ticket', and 'Name', from the dataset.Building a Pivot Table Using Pandas
Time to build a pivot table in Python using the awesome Pandas library! We will explore the different facets of a python pivot table in pandas in this article and build an awesome, flexible excel-style pivot table from scratch.
How to Group Data Using Index in a Pivot Table?
- pivot_table requires data, and an index parameter
- data is the Pandas dataframe you pass to the function.
- index is the feature that allows you to group your data. The index feature will appear as an index in the resultant table. Generally, categorical columns are used as indexes.
I will be using the ‘Sex’ column as the index for now:
#a single index
table = pd.pivot_table(data=df,index=['Sex'])
table
We can instantly compare all the feature values for both the genders. Now, let’s visualize the finding.
Python Code:

Well, the female passengers paid remarkably more for the tickets than the male passengers.
You can learn more about how to visualize your data here.
How to Run a Pivot With a Multi-Index?
You can even use more than one feature as an index to group your data. This increases the level of granularity in the resultant table, and you can get more specific with your findings:
#multiple indexes
table = pd.pivot_table(df,index=['Sex','Pclass'])
table
Using multiple indexes on the dataset enables us to concur that the disparity in ticket fare for female and male passengers was valid across every Pclass on Titanic.
Different Aggregation Functions for Different Features
The values shown in the table are the result of the summarization that aggfunc applies to the feature data. aggfunc is an aggregate function that pivot_table applies to your grouped data.
By default, it is np.mean(), but you can use different aggregate functions for different features too! Just provide a dictionary as an input to the aggfunc parameter with the feature name as the key and the corresponding aggregate function as the value.
I will be using np.mean() to calculate the mean for the ‘Age’ feature and np.sum() to calculate the total survivors for the ‘Survived’ feature:
#different aggregate functions
table = pd.pivot_table(df,index=['Sex','Pclass'],aggfunc={'Age':np.mean,'Survived':np.sum})
table
The resultant table makes more sense in using different aggregating functions for different features.
Aggregate on Specific Features With Values Parameter
But what are you aggregating on? You can tell Pandas the feature(s) to apply the aggregate function on in the value parameter. The value parameter is where you tell the function which features to aggregate on. It is an optional field, and if you don’t specify this value, then the function will aggregate all the numerical features of the dataset:
table = pd.pivot_table(df,index=['Sex','Pclass'],values=['Survived'], aggfunc=np.mean)
table
table.plot(kind='bar');
The survival rate of passengers aboard the Titanic decreased with a degrading Pclass among both the genders. Moreover, the survival rate of male passengers was lower than that of female passengers in any given Pclass.
Find the Relationship Between Features With Columns Parameter
Using multiple features as indexes is fine, but using some features as columns will help you to intuitively understand the relationship between them. Also, the resultant table can always be better viewed by incorporating the columns parameter of the pivot_table.
The columns parameter is optional and displays the values horizontally on the top of the resultant table. Both columns and the index parameters are optional, but using them effectively will help you to intuitively understand the relationship between the features.
#columns
table = pd.pivot_table(df,index=['Sex'],columns=['Pclass'],values=['Survived'],aggfunc=np.sum)
table
Using Pclass as a column is easier to understand than using it as an index:
table.plot(kind='bar');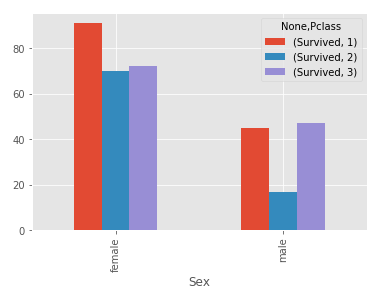
Handling Missing Data
pivot_table even allows you to deal with the missing values through the parameters dropna and fill_value:
- dropna allows you to drop the null values in the grouped table whose all values are null
- fill_value parameter can be used to replace the NaN values in the grouped table with the values that you provide here
#display null values
table = pd.pivot_table(df,index=['Sex','Survived','Pclass'],columns=['Embarked'],values=['Age'],aggfunc=np.mean)
table
I will be replacing the NaN values with the mean value from the ‘Age’ column:
#handling null values
table = pd.pivot_table(df,index=['Sex','Survived','Pclass'],columns=['Embarked'],values=['Age'],aggfunc=np.mean,fill_value=np.mean(df['Age']))
table
Conclusion
In this article, we explored the different parameters of the awesome pivot_table function and how it allows you to easily summaries the features in your dataset through a single line of code. If you are new to Python programming and want to learn more about data analysis with Python, I highly recommend you explore our free Python for Data Science and Pandas for Data Analysis in Python courses.
Key Takeaways
- We can create python pivot table in pandas using the pivot_table function.
- We can pass different parameters in the pivot_table function to aggregate data, handle missing values, etc.
Q1. How to do a pivot table in pandas?
A. To create a pivot table in pandas, use the pivot_table() function. Specify the data, index, columns, and values. For example: pd.pivot_table(data, index='row', columns='column', values='value').
Q2. What is the difference between pandas pivot and pandas pivot table?
A. The difference between pivot and pivot_table in pandas is that pivot reshapes data without aggregation, while pivot_table allows for data aggregation and supports functions like sum, mean, etc.
Q3. What is the purpose of the pivot_table() function in pandas?
A. The purpose of the pivot_table() function in pandas is to summarize and aggregate data, enabling the transformation of long data into a summarized, cross-tabulated form.
Q4. What is the equivalent of pivot in pandas?
A. The equivalent of pivot in pandas is the pivot() function, which reshapes data based on column values without performing aggregation.
I am on a journey to becoming a data scientist. I love to unravel trends in data, visualize it and predict the future with ML algorithms! But the most satisfying part of this journey is sharing my learnings, from the challenges that I face, with the community to make the world a better place!







This is an extremely valuable and very well presented article. It has really helped me untangle the usage of pivot_table quickly. A very small point, having to do with the analysis, is that in the section "Aggregate on specific features with values parameter" I believe that using 'np.mean' instead of 'np.sum' provides a better perspective on survival rates.
Hi Charles I am so glad to hear that you found the article useful! And thanks for pointing the mistake in the article. The average number of survivors definitely gives a better perspective on survival rates than the number of survivors.
This is really an article very well written in a very comprehensive manner, helped me understand intricacies of pivot table a lot! Had one question regarding it, how to find sum of column values for different level of indexes Let's say in the above example, how to find sum of all female who has survived, and can we represent it in the column itself as a sum row?
Glad you found it useful! If I understand correctly, what you are looking for is the "margins" argument of the Pivot table. I have implemented it in this Gist. Hope it helps.
Excellent article. The layout was clear and concise and the numerous examples really helped me understand what to do in different situations. I have passed this along with my network.
Thanks a lot!