This article is part of the Data Science Blogathon.
Introduction
Neural networks are ubiquitous right now. Organizations are splurging money on hardware and talent to ensure they can build the most complex neural networks and bring out the best deep learning solutions.
Although Deep Learning is a fairly old subset of machine learning, it didn’t get its due recognition until the early 2010s. Today, it has taken the world by storm and captured public attention in a way that very few algorithms have managed to accomplish.

In this article, I wanted to take a slightly different approach to neural networks and understand how they came to be. This is the story of the origin of neural networks!
The Origin of Neural Networks
The earliest reported work in the field of Neural Networks began in the 1940s, with Warren McCulloch and Walter Pitts attempting a simple neural network with electrical circuits.
The below image shows an MCP Neuron. If you studied High School physics, you’ll recognize that this looks quite similar to a simple NOR Gate.
The paper demonstrated basic thought with the help of signals, and how decisions were made by transforming the inputs provided.
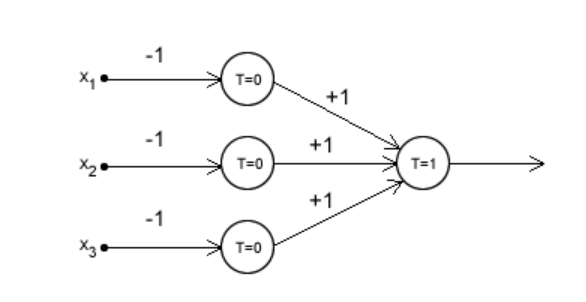
McCulloch and Pitts’ paper provided a way to describe brain functions in abstract terms, and showed that simple elements connected in a neural network can have immense computational power.
Despite its groundbreaking implications, the paper went virtually unnoticed till about 6 years later, when Donald Hebb (image below) published a paper that reinforced that neural pathways strengthen each time they are used.

Keep in mind that computing was still in its nascent stage at that point, with IBM coming out with its first PC (The IBM 5150) in 1981.

Fast forward to the ’90s, a lot of research into artificial neural networks had already been published. Rosenblatt had created the first perceptron in the 1950s. The backpropagation algorithm was successfully implemented at the Bell Labs in 1989 by Yann LeCun. By the 1990s, the US Postal Service had already deployed LeCun’s model for reading ZIP Codes on envelopes.
The LSTM (Long Short Term Memory) as we know it today was coined back in 1997.
If so much groundwork had already been laid down by the 90’s, why did it take until 2012 to leverage neural network for deep learning tasks?
Hardware and the Rise of the Internet
A major challenge that deep learning research had encountered was the lack of reproducible research. The advancements had thus far been theory-driven, because of little availability of reliable data and limited hardware resources.
The last two decades have seen rapid strides in the field of Hardware and the Internet. In the 1990s, the IBM PC had a RAM of 16KB. In the 2010s, the average RAM of PC’s used to be around 4GB!
Nowadays, we can train a small-sized model on our computers, which would have been unfathomable in the ’90s.
The Gaming market also played a significant role in this revolution, with companies like NVIDIA and AMD investing heavily in supercomputing to deliver a high-end virtual experience.
With the growth of the internet, creating and distributing datasets for machine learning tasks became that much easier.
It has become rather easy to collect images from Google or mine text from Wikipedia to train and build Deep Learning Models.
The 2010’s: Our Era of Deep Learning
ImageNet: In 2009, the beginning of the modern deep learning era, Stanford’s Fei-Fei Li created ImageNet, a large visual dataset that has been lauded as the project that spawned the AI Revolution in the world.
Back in 2006, Li was a new professor at the University of Illinois – Urbana Champaign. Her colleagues would continuously talk about coming up with new algorithms that would make better decisions. She, however, saw the flaw in their plan.
The best algorithm wouldn’t run well if it was trained on a dataset that reflected the real world. ImageNet consisted of more than 14 million images across more than 20,000 categories, and to date, remains the cornerstone in Object Recognition Technology.
Public Competitions: In 2009, Netflix held an open competition called Netflix Prize, to predict user ratings for films. On September 21, 2009, a prize of 1 million USD was awarded to BellKor’s Pragmatic Chaos team which beat Netflix’s own algorithm by 10.06%.
Started in 2010, Kaggle is a platform that hosts machine learning competitions open to everyone across the globe. It has allowed researchers, engineers, and homegrown coders to push the envelope in solving complex data tasks.
Prior to the AI Boom, the investment in artificial intelligence was around 20 million USD. By 2014, this investment had grown twenty-fold, with market leaders like Google, Facebook, and Amazon allocating funds to further research into AI products of the future. This new wave of investments led to increased hiring in deep learning from a few hundred to tens of thousands.
End Notes
Despite its slow beginnings, Deep Learning has become an inescapable part of our lives. From Netflix and YouTube recommendations to language translation engines, from facial recognition and medical diagnosing to self-driving cars, there is no sphere that Deep Learning has not touched.
These advances have broadened the future scope and application of Neural Networks in improving the quality of our lives.
AI is not our future, it is our present, and it’s just getting started!






Very interesting and informative
Wow...I never knew a lot of these things!