This article was published as a part of the Data Science Blogathon.
Introduction
“Data is the new oil” ~ that’s no secret and is a trite statement nowadays. The more important point to ponder on is how we can build more efficient machines and platforms that can handle this huge influx of data, which is growing at an exponential rate. A few years back when Data Science and Machine learning were not hot buzz words, people used to do simple data manipulations and analysis tasks on spreadsheets (not denouncing spreadsheets, they are still useful!) but as people became more data-savvy and computer hardware got more efficient, new platforms replaced the simpler platforms for trivial data manipulation and model building tasks. First R/Python replaced Excel as the standard platforms for data handling tasks because they could handle much larger datasets.
Then came Big Data platforms such as Spark, a unified computing engine for parallel data processing on computer clusters, which utilizes in-memory computation and is even more efficient in handling big data in the order of billions of rows and columns.

You can read all about Spark in Spark’s fantastic documentation here.
However, this article is aimed to help you and suggest quick solutions that you can try with some of the bottlenecks you might face when dealing with a huge volume of data with limited resources on Spark on a cluster to optimize your spark jobs. Although Spark has its own internal catalyst to optimize your jobs and queries, sometimes due to limited resources you might encounter memory-related issues hence it is good to be aware of some good practices that might help you. This article assumes that you have prior experience of working with Spark.
This article will be beneficial not only for Data Scientists but for Data engineers as well.
In this article, you will be focusing on how to optimize spark jobs by:
-
— Configuring the number of cores, executors, memory for Spark Applications.
-
— Good Practices like avoiding long lineage, columnar file formats, partitioning etc. in Spark.
Let’s get started.
Configuring number of Executors, Cores, and Memory :
Spark Application consists of a driver process and a set of executor processes. The driver process runs your main() function and is the heart of the Spark Application. It is responsible for executing the driver program’s commands across the executors to complete a given task. It holds your SparkContext which is the entry point of the Spark Application. The worker nodes contain the executors which are responsible for actually carrying out the work that the driver assigns them. Cluster Manager controls physical machines and allocates resources to the Spark Application. There can be multiple Spark Applications running on a cluster at the same time.
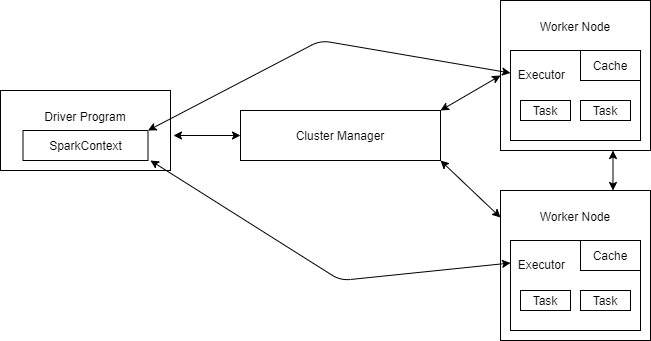
Architecture of Spark Application
There are three main aspects to look out for to configure your Spark Jobs on the cluster – number of executors, executor memory, and number of cores. An executor is a single JVM process that is launched for a spark application on a node while a core is a basic computation unit of CPU or concurrent tasks that an executor can run. A node can have multiple executors and cores. All the computation requires a certain amount of memory to accomplish these tasks. You can control these three parameters by, passing the required value using –executor-cores, –num-executors, –executor-memory while running the spark application.
You might think more about the number of cores you have more concurrent tasks you can perform at a given time. While this ideology works but there is a limitation to it. It is observed that many spark applications with more than 5 concurrent tasks are sub-optimal and perform badly. This number came from the ability of the executor and not from how many cores a system has. So the number 5 stays the same even if you have more cores in your machine. So setting this to 5 for good HDFS throughput (by setting –executor-cores as 5 while submitting Spark application) is a good idea.
When you run spark applications using a Cluster Manager, there will be several Hadoop daemons that will run in the background like name node, data node, job tracker, and task tracker (they all have a particular job to perform which you should read). So, while specifying —num-executors, you need to make sure that you leave aside enough cores (~1 core per node) for these daemons to run smoothly.
Also, you will have to leave at least 1 executor for the Application Manager to negotiate resources from the Resource Manager. You will also have to assign some executor memory to compensate for the overhead memory for some other miscellaneous tasks. Literature shows assigning it to about 7-10% of executor memory is a good choice however it shouldn’t be too low.
For example, suppose you are working on a 10 nodes cluster with 16 cores per node and 64 GB RAM per node.
You can assign 5 cores per executor and leave 1 core per node for Hadoop daemons. So now you have 15 as the number of cores available per node. Since you have 10 nodes, the total number of cores available will be 10×15 = 150.
Now the number of available executors = total cores/cores per executor = 150/5 = 30, but you will have to leave at least 1 executor for Application Manager hence the number of executors will be 29.
Since you have 10 nodes, you will have 3 (30/10) executors per node. The memory per executor will be memory per node/executors per node = 64/2 = 21GB. Leaving aside 7% (~3 GB) as memory overhead, you will have 18 (21-3) GB per executor as memory. Hence finally your parameters will be:
–executor-cores 5, –num-executors 29, –executor-memory 18 GB.
Like this, you can work out the math for assigning these parameters. Although do note that this is just one of the ways to assign these parameters, it may happen that your job may get tuned at different values but the important point to note here is to have a structured way to think about tuning these values rather than shooting in the dark.
Avoid Long Lineage
Spark offers two types of operations: Actions and Transformations.
Transformations (eg. map, filter,groupBy, etc.) construct a new RDD/DataFrame from a previous one, while Actions (e.g. head, show, write, etc.) compute a result based on an RDD/DataFrame, and either return it to the driver program or save it to the external storage system. Spark does all these operations lazily. Lazy evaluation in spark means that the actual execution does not happen until an action is triggered. Every transformation command run on spark DataFrame or RDD gets stored to a lineage graph.
It is not advised to chain a lot of transformations in a lineage, especially when you would like to process huge volumes of data with minimum resources. Rather, break the lineage by writing intermediate results into HDFS (preferably in HDFS and not in external storage like S3 as writing on external storage could be slower).
Broadcasting
When a variable needs to be shared across executors in Spark, it can be declared as a broadcast variable. Note the broadcast variables are read-only in nature. Broadcast variables are particularly useful in case of skewed joins. For example, if you are trying to join two tables one of which is very small and the other very large, then it makes sense to broadcast the smaller table across worker nodes’ executors to avoid the network overhead.
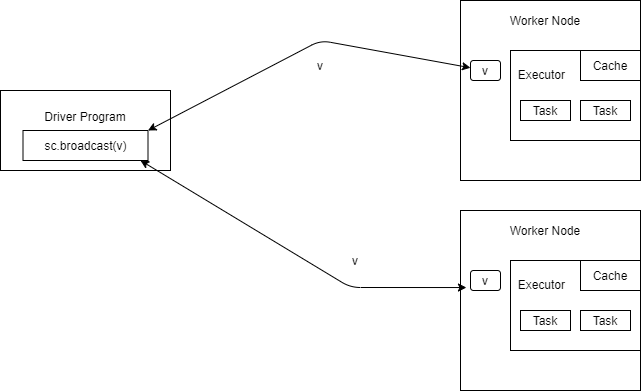
Broadcasting in Spark
Partitioning your DataSet
While Spark chooses good reasonable defaults for your data, if your Spark job runs out of memory or runs slowly, bad partitioning could be at fault.
If your dataset is large, you can try repartitioning (using the repartition method) to a larger number to allow more parallelism on your job. A good indication of this is if in the Spark UI you don’t have a lot of tasks, but each task is very slow to complete. On the other hand, if you don’t have that much data and you have a ton of partitions, the overhead of having too many partitions can also cause your job to be slow. You can repartition to a smaller number using the coalesce method rather than the repartition method as it is faster and will try to combine partitions on the same machines rather than shuffle your data around again.
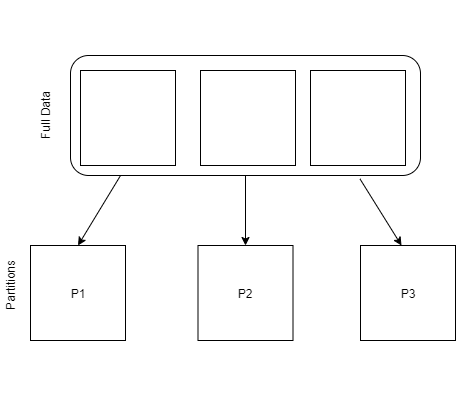
Partitioning of Data
Columnar File Formats
Spark utilizes the concept of Predicate Push Down to optimize your execution plan. For example, if you build a large Spark job but specify a filter at the end that only requires us to fetch one row from our source data, the most efficient way to execute this is to access the single record that you need. Spark will actually optimize this for you by pushing the filter down automatically.
Columnar file formats store the data partitioned both across rows and columns. This makes accessing the data much faster. They are much more compatible in efficiently using the power of Predicate Push Down and are designed to work with the MapReduce framework. Some of the examples of Columnar file formats are Parquet, ORC, or Optimized Row-Column, etc. Use Parquet format wherever possible for reading and writing files into HDFS or S3, as it performs well with Spark.
Use DataFrames/Datasets instead of RDDs :
Resilient Distributed Dataset or RDD is the basic abstraction in Spark. RDD is a fault-tolerant way of storing unstructured data and processing it in the spark in a distributed manner. In older versions of Spark, the data had to be necessarily stored as RDDs and then manipulated, however, newer versions of Spark utilizes DataFrame API where data is stored as DataFrames or Datasets. DataFrame is a distributed collection of data organized into named columns, very much like DataFrames in R/Python. Dataframe is much faster than RDD because it has metadata (some information about data) associated with it, which allows Spark to optimize its query plan. Since the creators of Spark encourage to use DataFrames because of the internal optimization you should try to use that instead of RDDs.
End Notes
So this brings us to the end of the article. Spark itself is a huge platform to study and it has a myriad of nuts and bolts which can optimize your jobs. In this article, we covered only a handful of those nuts and bolts and there is still a lot to be explored. I encourage you to continue learning. I hope this might have given you the right head start in that direction and you will end up speeding up your big data jobs.







Litterally, I found the article very helpful. It will help a lot to everyone reading this and will for sure beautify the presentation. Great Work Mann. Just wanna say that this article is SHORT, SWEET AND SUFFICIENT. Keep it up.🙌